Exposing Deep Fakes Using Inconsistent Head Poses¶
Authors: Xin Yang, Yuezun Li, Siwei Lyu
Venue: arXiv, 2018 — arXiv:1811.00661
TL;DR¶
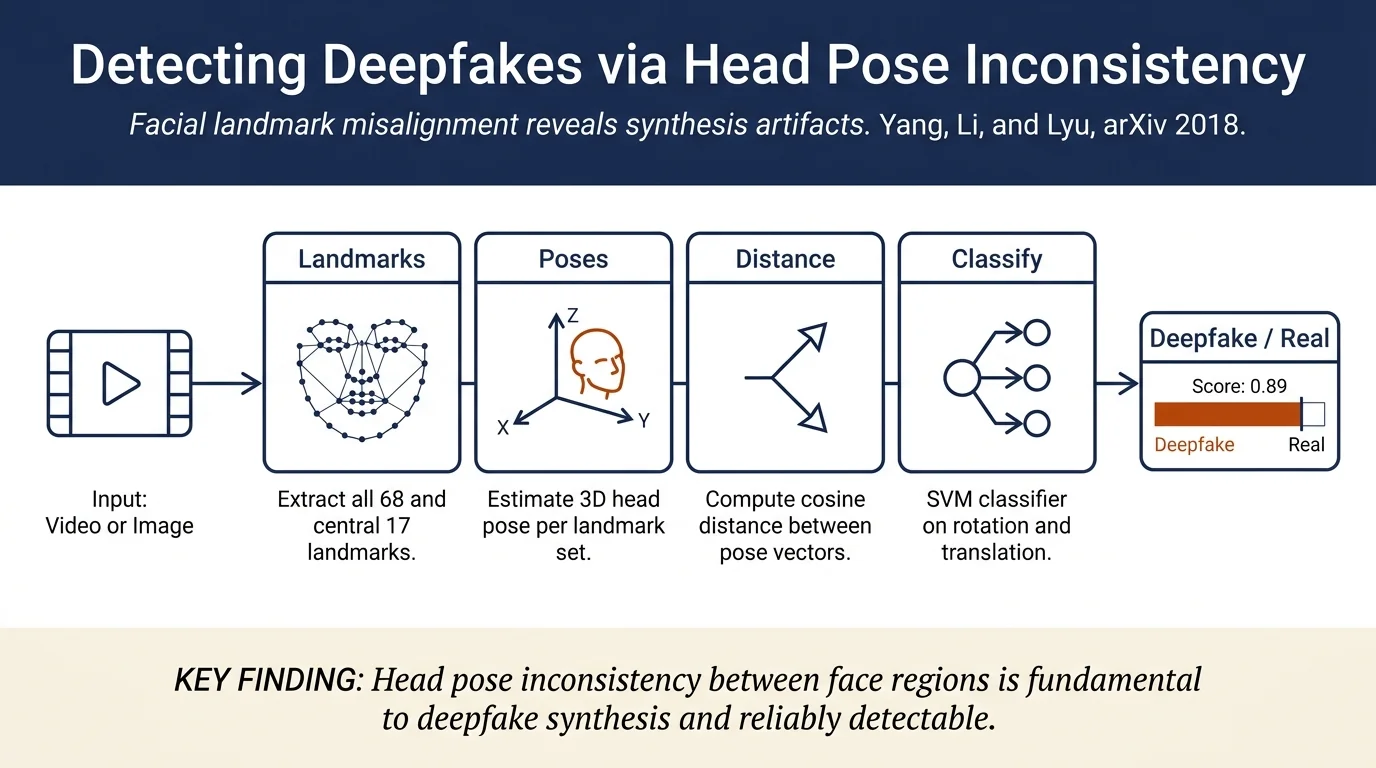
Deepfakes splice a synthesized face into an original image, introducing landmark misalignment errors invisible to the eye but detectable through 3D head pose estimation. The method compares head poses estimated from all facial landmarks versus only the central region; real faces show consistent poses while deepfakes exhibit large differences. An SVM classifier trained on head pose differences achieves 89.0% AUROC on deepfake videos and 84.3% on a diverse face-swap dataset.
Contributions¶
- Identifies intrinsic limitation in deepfake generation: neural networks don't guarantee landmark consistency between original and synthesized faces.
- Proposes head pose inconsistency as a robust forensic cue for deepfake detection.
- Demonstrates that facial landmark mismatch (mean shift 1.54 pixels) translates to detectable head pose divergence (cosine distance 0.02–0.08 for fakes vs. <0.02 for real).
- Develops practical SVM-based classifier with straightforward feature extraction (rotation matrices and translation vectors).
- Provides comprehensive ablation study comparing head pose representations (orientation vectors, Rodrigues vectors, full rotation matrices) with and without translation features.
Method¶
The key insight exploits the deepfake generation pipeline:
- Face alignment: The source face is warped via affine transformation M into a canonical 64×64 configuration using central facial landmarks.
- Synthesis: A generative neural network creates the synthesized face, but doesn't guarantee landmark preservation—the output landmarks Q₀_out deviate from input P₀_in (observed mean shift 1.54 ± 0.92 pixels).
- Inverse transformation: The synthesized face is inverse-transformed back (M⁻¹), reintroducing mismatch into the larger face region.
- Key observation: Outer contour landmarks remain unchanged (from original), but inner face landmarks become misaligned.
The detection method leverages this structure:
- Estimate 3D head pose from all 68 facial landmarks (whole face) using Levenberg-Marquardt optimization on the pose-from-landmarks problem.
- Estimate 3D head pose from only 17 central landmarks (red subset in Fig. 2).
- Compute cosine distance between the two estimated head orientation vectors. Real images show distance <0.02; deepfakes show distance 0.02–0.08.
- Features for SVM: differences in rotation matrices (Ra − Rc) and translation vectors (~ta − ~tc), standardized.
Results¶
AUROC (area under ROC curve): - UADFV dataset (video-level): 97.4% (combining rotation and translation; best) - UADFV dataset (frame-level): 89.0% - DARPA GAN Challenge (frame-level): 84.3%
Ablation study shows translation features matter: rotation-only achieves 85.3% on frames, but adding translation improves to 89.0%.
The method works across two distinct deepfake datasets with different synthesis methods, suggesting the inconsistency cue is fundamental to the generation process rather than dataset-specific.
Connections¶
- Rössler et al. (2019) extends deepfake detection benchmarks with multiple synthesis methods (Face2Face, FaceSwap, DeepFakes, NeuralTextures) and evaluates detection approaches including CNN-based and steganography-based methods.
- Related to media forensics and face manipulation detection broadly.
- Contrasts with Vaccari & Chadwick (2020) which examines social and epistemic impacts of deepfakes rather than technical detection.
- Part of emerging synthetic media detection literature; Rana et al. (2022) surveys detection approaches finding deep learning achieves 89.7% mean accuracy.
Notes¶
Strengths: - Addresses a real limitation in neural network face synthesis, not superficial artifacts. - Features are simple, interpretable, and don't require large models. - Works on both videos and still images. - Ablation study is thorough.
Limitations: - Performance drops on blurry synthesized faces (DARPA GAN, 84.3% AUROC), suggesting landmark detection errors propagate. - Doesn't address advanced post-processing that might alter the landmark structure. - Evaluated on relatively small datasets (49 video pairs for training, 14 pairs + 493 images for testing). - Assumes access to a robust facial landmark detector (DLib), which may fail on heavily manipulated or occluded faces.
Future directions: - Robustness to image compression, noise, and post-processing. - Combination with other forensic cues (color, blinking, eye reflections). - Adaptation to emerging synthesis methods (StyleGAN, NVIDIA's face synthesis).