Is Less Really More? Fake News Detection with Limited Information¶
Authors: Zhaoyang Cao, John Nguyen, Reza Zafarani Venue: arXiv preprint, April 2025 — arXiv:2504.01922 Code: https://github.com/kappakant/SLIM
TL;DR¶
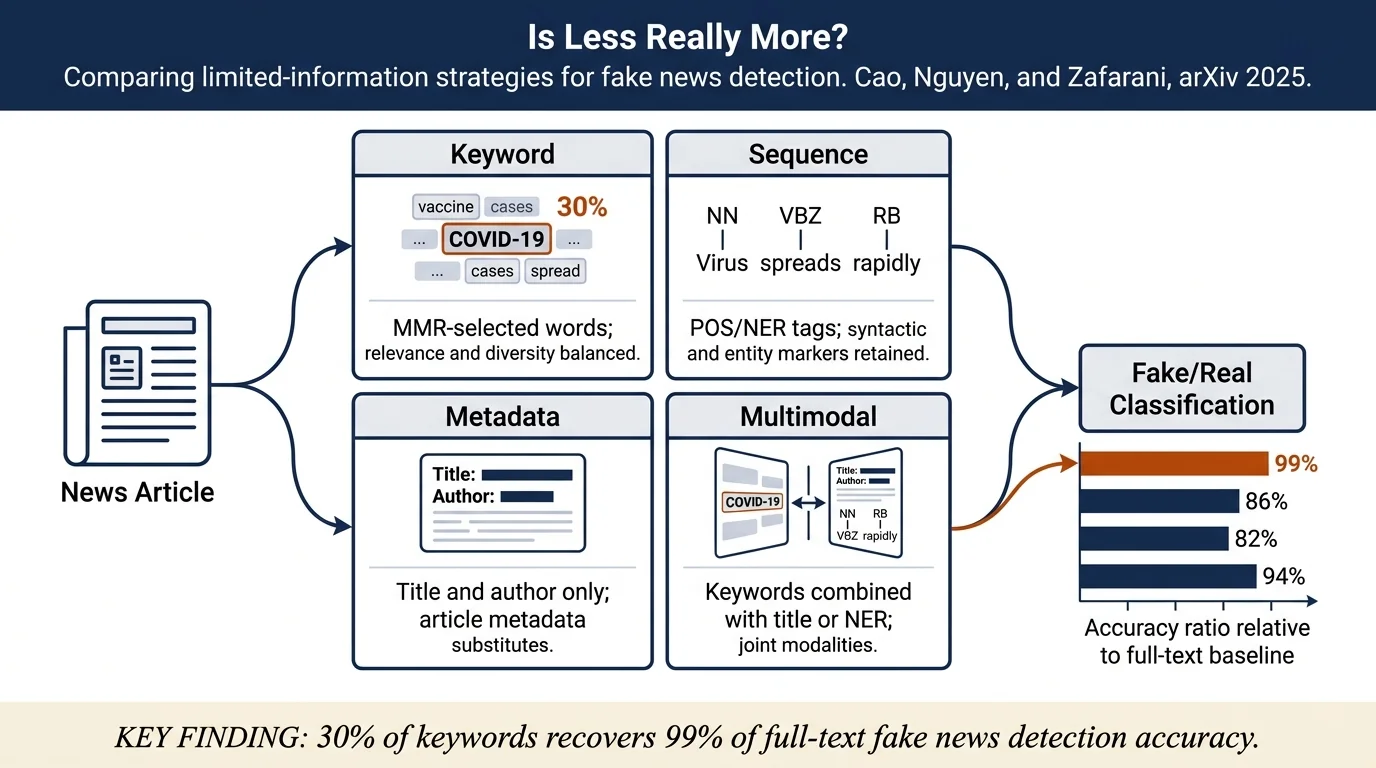
SLIM (Systematically-selected Limited Information) replaces full news article text with strategically chosen subsets — extracted keywords, POS/NER sequence tags, or textual metadata — to address the computational cost and data-sparsity limitations of full-text fake news detection. Information-theoretic measures (normalized Shannon entropy, average token count) confirm these subsets are substantially sparser than full text. Fine-tuning XLNet_base on SLIM variants achieves 95.55% on ReCOVery and 97.60% on Fake_And_Real_News, matching or beating MisRoBÆRTA and BiLSTM_CapsNet. Retaining just 30% of keywords recovers ~99% of full-text accuracy, and combining keywords with title or NER tags yields additional gains.
Contributions¶
- First framework to systematically quantify and compare multiple limited-information strategies for fake news detection using information-theoretic measures (normalized Shannon entropy and average token count).
- Demonstrated that MMR-selected keywords at 30% of full-text length are sufficient to achieve near-full-text accuracy (~99% accuracy ratio) across multiple benchmarks.
- Showed that multi-modal combination of limited information (keywords + title, keywords + NER) consistently outperforms single-modality subsets.
- Established that metadata alone (title, author) cannot substitute for text body — accuracy drops ~10% below baseline — but serves as a useful complement when combined with keywords.
Method¶
SLIM formalises the news article as an ordered sequence \(A = \{w_1, w_2, \ldots, w_p\}\) and defines four variants based on the type of limited input:
SLIM_KEYWORD. BERT computes a document embedding \(e_d \in \mathbb{R}^n\). N-gram word embeddings \(e_{w_i}\) are computed for each word; candidates must have positive cosine similarity to \(e_d\). MMR (Maximal Marginal Relevance, \(\lambda = 0.5\)) then iteratively selects the word \(w^*\) that maximises:
The keyword proportion \(k\) is expressed as a fraction of total word count and is swept from 10% to 35% in experiments.
SLIM_SEQUENCE. Tokenised text is POS-tagged; adjectives and adverbs are retained (SLIM_POS). Named-entity chunks are extracted without count limits (SLIM_NER), since named entities are already sparse.
SLIM_METADATA. Only title and/or author fields are passed to the encoder, bypassing the body text entirely.
SLIM_MULTIMODAL. Concatenation (\(\oplus\)) of keyword sets with NER words (\(\text{SLIM}^I\)), author (\(\text{SLIM}^{II}\)), or title (\(\text{SLIM}^{III}\)).
All variants share the same backbone: XLNet_base, pre-trained with XLNet's permutation language modelling objective \(\mathcal{F}(\theta) = \max\mathbb{E}[\sum_t \log p(x_{z_t} \mid \mathbf{x}_{z_{<t}};\theta)]\) and fine-tuned with cross-entropy loss using Adam (\(\eta = 5 \times 10^{-5}\)). Prediction is \(\hat{y} = \text{argmax}_i(\mathbf{z}_i)\) over XLNet logits.
Information density of each input type is measured via normalised Shannon entropy \(S_\text{normalized} = \sum_{w \in A} H(w)/\text{sig}(w)\) where significance \(\text{sig}(w) = f_w^{\mathcal{T}} / |\mathcal{T}|\) normalises by relative word frequency in the full article.
Results¶
Full-text SLIM baseline (Table 3):
| Dataset | Accuracy | Macro-F₁ | AUC |
|---|---|---|---|
| ReCOVery | 95.55 ± 0.0046 | 94.71 | 95.53 |
| Fake_And_Real_News | 97.60 ± 0.0031 | 97.60 | 97.62 |
Comparison with baselines (Table 1, 25% keywords):
| Method | ReCOVery | Fake_And_Real_News |
|---|---|---|
| DocEmb_TFIDF BiLSTM | 89.56 | 92.26 |
| MisRoBÆRTA | 91.35 | 97.34 |
| BiLSTM_CapsNet | 95.49 | 95.56 |
| SLIM | 95.55 | 97.60 |
| SLIM_KEYWORD | 92.86 | 92.76 |
| SLIM_MULTIMODAL^III | 93.72 | 93.72 |
Key findings by research question:
- RQ2 (keywords): 30% keyword extraction achieves ~99% accuracy ratio on ReCOVery. Accuracy ratio increases monotonically with keyword proportion on both datasets.
- RQ3 (sequences): POS tagging achieves ~94% accuracy ratio at 10–20% of full text. NER alone reaches 86.82% on ReCOVery (significantly below baseline) and 90.08% on Fake_And_Real_News.
- RQ4 (metadata): Title alone: 82.25% (ReCOVery), 85.21% (Fake_And_Real_News) — statistically significant degradation (~10% drop). Author alone: 76.99% (ReCOVery).
- RQ5 (multimodal): Keywords + title outperforms keywords alone on ReCOVery. Keywords + NER slightly reduces accuracy (~0.5%) on Fake_And_Real_News due to heterogeneous NER effects.
Connections¶
- Uses ReCOVery as a primary benchmark; the dataset was introduced in Zhou et al. (2020).
- SLIM_MULTIMODAL extends the multi-signal approach of SAFE (Zhou et al., 2020) from image+text fusion to keyword+metadata fusion.
- The strategic feature-selection philosophy complements the hand-crafted feature tradition surveyed in feature engineering, but uses a language-model-guided MMR rather than manual selection.
- Multimodal detection topic covers the broader context of combining heterogeneous information sources.
- Zhou et al. (2023) — HERO is a concurrent Syracuse group work using hierarchical linguistic trees; SLIM takes the opposite direction — minimising rather than enriching the input representation.
Notes¶
The central empirical insight — that 30% of keywords, selected by a principled MMR procedure, recovers ~99% of full-text accuracy — is practically significant for deployment in sparse-data or real-time contexts. However, this claim rests on two benchmarks (ReCOVery, Fake_And_Real_News), both English-language and relatively balanced. Generalisation to highly imbalanced, multilingual, or domain-shifted datasets remains open.
The metadata result is instructive: titles alone are sufficient for ~82–85% accuracy, confirming that clickbait-style linguistic patterns are detectable from headlines. The author feature is weaker, suggesting author identity is either noisy or absent in these datasets.
Future work flagged by the authors: syntactic-semantic augmentation (controlled paraphrase generation, dependency shuffling) to further close the gap between limited-information and full-text performance.