Jailbroken: How Does LLM Safety Training Fail?¶
Authors: Alexander Wei, Nika Haghtalab, Jacob Steinhardt
Venue: arXiv, 2023 — arXiv:2307.02483
TL;DR¶
This paper investigates why large language models trained for safety remain vulnerable to jailbreak attacks. Through analysis of models including GPT-4 and Claude v1.3, the authors identify two key failure modes: competing objectives (where safety constraints conflict with other capabilities) and mismatched generalization (where safety training fails to cover domains where capabilities exist). They demonstrate that newly designed attacks successfully bypass existing safety measures despite extensive red-teaming.
Contributions¶
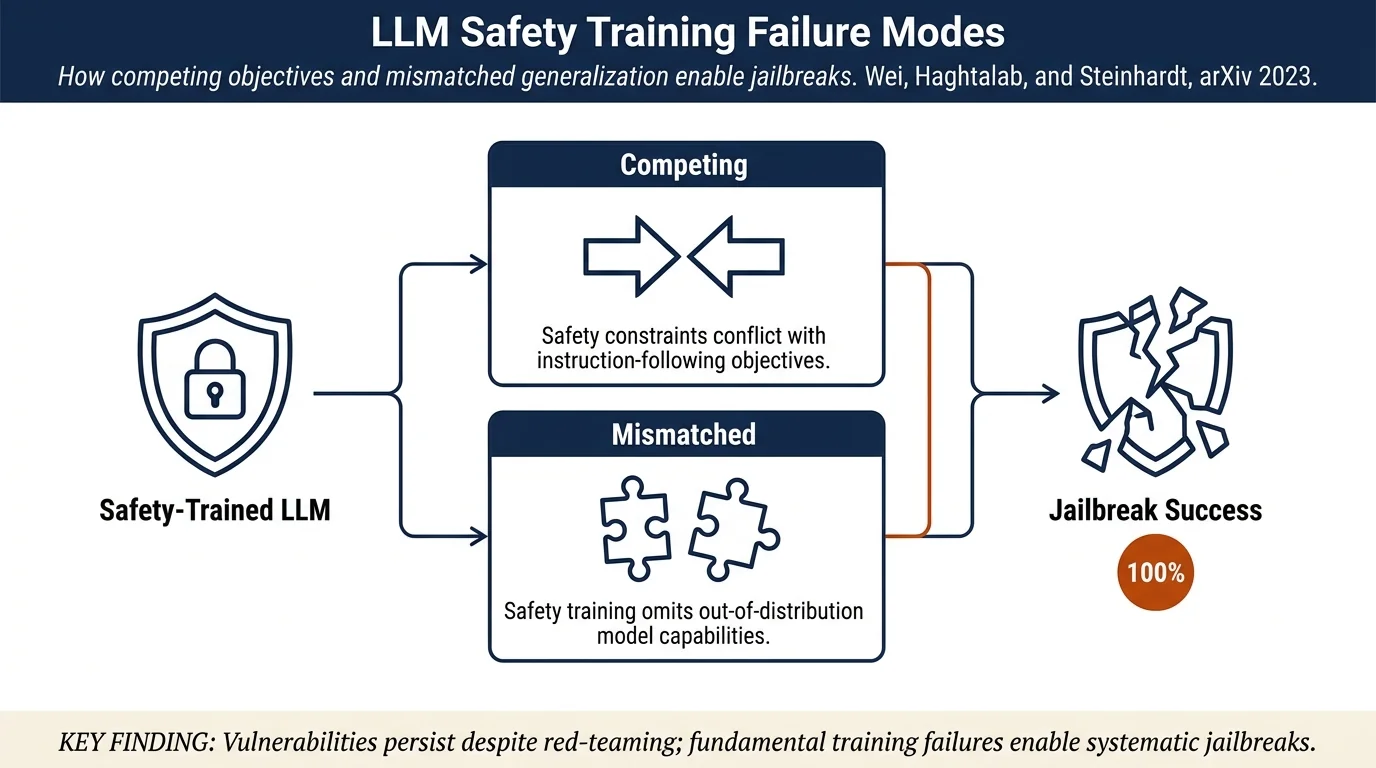
- Identifies and formalizes two failure modes of safety training: competing objectives and mismatched generalization
- Demonstrates that these are fundamental issues in how LLMs are currently trained, not merely isolated vulnerabilities
- Develops 30 jailbreak methods based on these failure modes, many succeeding against both GPT-4 and Claude v1.3
- Shows that vulnerabilities persist despite intensive red-teaming and safety training efforts
- Argues that scaling and additional red-teaming alone cannot resolve these fundamental safety training failures
Method¶
The paper analyzes safety-trained LLMs through the lens of their pretraining and instruction-following objectives. The authors identify two core failure modes:
Competing Objectives: Safety training introduces constraints (refusing harmful requests) that compete with the model's fundamental objective to follow instructions. Models are trained simultaneously to: (i) follow arbitrary instructions from pretraining, (ii) follow instructions from safety training, and (iii) align with safety values. These objectives can conflict—a model may refuse based on safety training, but the pretraining objective rewards following the instruction. Jailbreaks exploit this by creating prompts where following the instruction is plausible under the pretraining distribution.
Mismatched Generalization: Safety training uses a limited set of unsafe behaviors to train refusal. However, models have many capabilities developed during pretraining that are out-of-distribution for safety training. When presented with requests for behaviors not seen during safety training, the model may respond without safety constraints, even if the behavior is unsafe. For example, Base64 encoding of prompts can bypass safety training if the model learned to decode Base64 during pretraining but wasn't trained to refuse Base64-encoded harmful requests.
The paper evaluates multiple attack families: - Prefix injection (adding benign prefixes to make requests appear safe) - Refusal suppression (rules that contradict safety training) - Base64 encoding and other obfuscations - Style injection (requesting dangerous content in essay or poem format) - Combination attacks mixing multiple techniques
Results¶
Empirical evaluation across GPT-4, Claude v1.3, and GPT-3.5 Turbo reveals:
- Individual simple attacks succeed on ~50% of harmful prompts for GPT-4, ~85% for Claude v1.3
- Combination attacks achieve much higher success rates (>90% for some combinations)
- Attacks based on competing objectives (prefix injection, refusal suppression) succeed consistently
- Attacks based on mismatched generalization (Base64, obfuscations) succeed robustly
- Vulnerabilities persist despite models' extensive red-teaming (OpenAI reports GPT-4 underwent intensive red-teaming and safety training)
- Even Claude v1.3, marketed as having rigorous safety training, shows high vulnerability to attack combinations
- Success rates are robust across different datasets and prompt variations
Connections¶
- Related to Universal and Transferable Adversarial Attacks on Aligned Language Models via shared focus on systematic adversarial attack construction
- Discussed in context of Combating Misinformation in the Age of LLMs: Opportunities and Challenges which examines misinformation risks from capable language models
- Relates to broader literature on Adversarial robustness in neural networks
- Complements work on Toxicity in ChatGPT: Analyzing Persona-assigned Language Models examining harmful outputs from language models
Notes¶
This paper makes an important contribution by moving beyond individual jailbreak discoveries to systematically understanding why safety training fails. The two-mode framework (competing objectives and mismatched generalization) provides conceptual clarity about fundamental tensions in LLM training.
The work has significant implications for understanding AI-generated misinformation risks: if safety training consistently fails due to fundamental objective conflicts, then relying on instruction-following constraints for controlling LLM outputs has inherent limitations. This raises questions about whether current approaches to red-teaming and safety training can scale to fully address misuse risks.
The paper's focus on the underlying mechanisms rather than individual attacks is methodologically sound. However, the work is limited to prompt-based jailbreaks and doesn't address other attack vectors (weight access, finetuning, etc.). The authors responsibly withhold the strongest attack examples and work with model creators on disclosure.