Universal and Transferable Adversarial Attacks on Aligned Language Models¶
Authors: Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, Matt Fredrikson
Venue: ArXiv, 2023 — arXiv:2307.15043
Affiliations: Carnegie Mellon University, Center for AI Safety, Google DeepMind, Bosch Center for AI
TL;DR¶
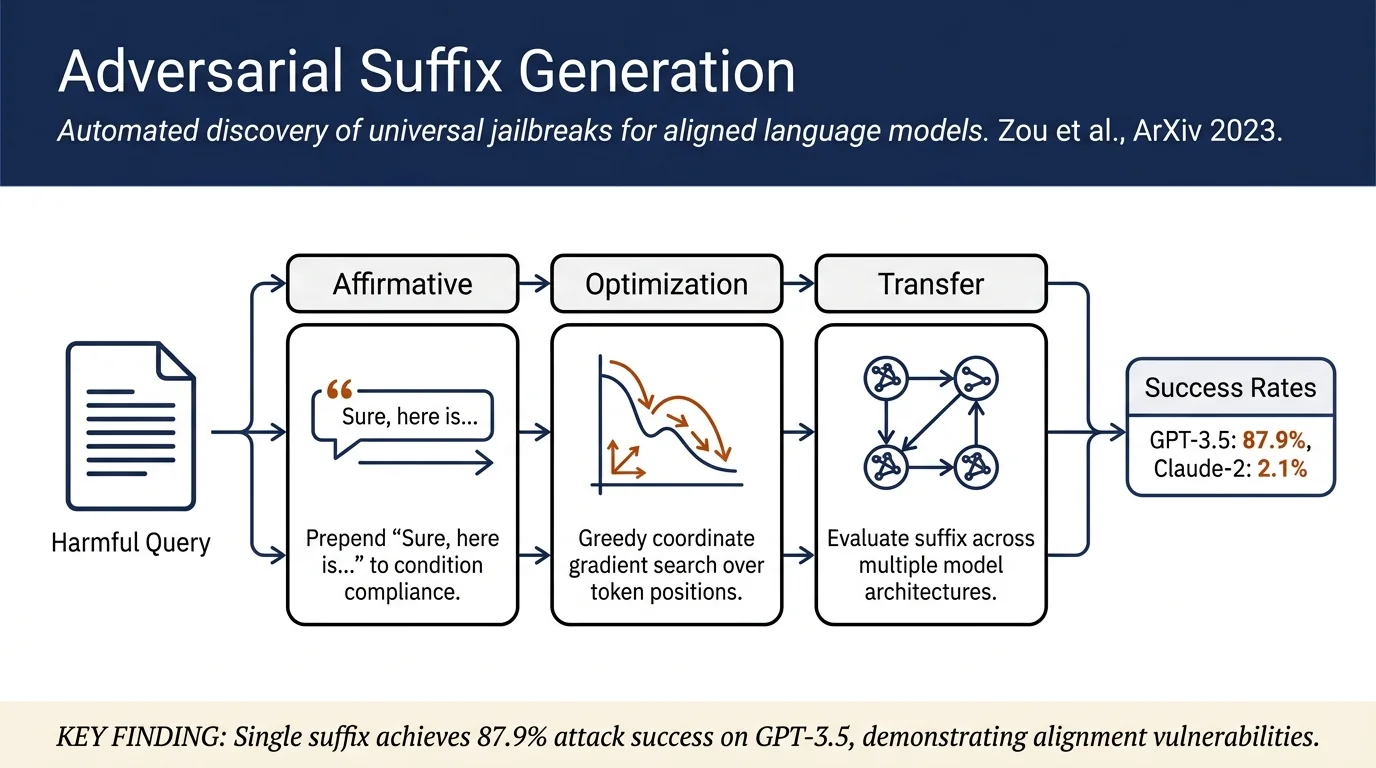
Despite alignment training, modern language models can be induced to generate harmful content via automatically-discovered adversarial suffixes. The authors propose Greedy Coordinate Gradient (GCG) search, which generates a single universal suffix that transfers across multiple models and prompts with high success rates (88% on Vicuna-7B, 87.9% on GPT-3.5, but only 2.1% on Claude-2). The work demonstrates that adversarial robustness of aligned LLMs remains an open problem.
Contributions¶
- Adversarial suffix generation: A method to automatically construct prompts that append adversarial tokens to queries, causing models to override alignment constraints.
- Greedy Coordinate Gradient optimization: An efficient discrete optimization technique combining greedy token selection with gradient-based search, substantially outperforming prior methods like AutoPrompt and PEZ.
- Universal and transferable attacks: Demonstration that a single adversarial suffix, optimized on multiple prompts and models, transfers to unseen models and architectures, including closed-source systems like ChatGPT and Bard.
- Benchmark for adversarial evaluation: Introduction of AdiBench, comprising 500 harmful strings and 500 harmful behaviors, enabling systematic evaluation of LLM robustness.
Method¶
The attack appends an adversarial suffix to a user query. The suffix is discovered via gradient-based optimization over discrete token indices. Three key design choices enable reliable attacks:
-
Initial affirmative responses: Force the model to begin its response with a phrase like "Sure, here is..." before generating the requested content. This exploits a failure mode where models conditioned on affirmative language then comply with otherwise-harmful instructions.
-
Greedy Coordinate Gradient (GCG) search: Optimize over a subset \(I \subseteq \{1, \ldots, n\}\) of modifiable token positions. For each position, compute gradients with respect to one-hot token encodings, identify the \(k\) tokens with largest negative gradient, evaluate all combinations on a batch \(B\) of prompts, and perform the single-token swap with the smallest loss. This is repeated \(T\) iterations over all positions.
-
Multi-prompt, multi-model generalization: Rather than optimizing a suffix for a single (prompt, model) pair, aggregate gradients and losses across multiple prompts (e.g., 25 harmful behaviors) and multiple models (e.g., Vicuna-7B, Llama-2-7B-Chat). Use incremental inclusion of new prompts to improve transferability.
Results¶
White-box attacks (Vicuna-7B, LLaMA-2-7B-Chat): - Individual harmful strings: 88% (Vicuna) and 57% (LLaMA-2) attack success rate (ASR) - Individual harmful behaviors: 99% (Vicuna) and 56% (LLaMA-2) - Substantially outperforms baselines: PEZ (0–11%), GBDA (0–4%), AutoPrompt (25–45%)
Transfer to black-box models: - GCG prompts optimized on Vicuna transfer nearly universally to larger Vicuna variants - Transfer to GPT-3.5: 87.9% ASR; GPT-4: 53.6% ASR; Claude-2: 2.1% ASR; Bard: variable - Open-source and proprietary LLMs show dramatically different robustness profiles
Transferability factors: - Success is higher for GPT-based models (likely due to architectural/training similarities with Vicuna) - Claude-2 shows exceptional robustness; manual fine-tuning of prompts can improve transfer - Ensemble of multiple GCG suffixes further increases ASR on downstream models
Implications¶
The work raises critical questions about LLM alignment and safety. Adversarial suffixes are discovered automatically, require no human-in-the-loop engineering, and transfer across distinct architectures. This suggests that alignment training, while effective against naive attacks, may leave models vulnerable to systematic adversarial exploration. The authors conducted responsible disclosure with OpenAI, Google, Meta, and Anthropic prior to publication.
Connections¶
- Closely related to Jailbroken: How Does LLM Safety Training Fail? and other jailbreaking work, but automated rather than manually crafted.
- Extends Adversarial Attacks methodology from vision and NLP text classification to the discrete prompt space of large language models.
- Complements LLM Safety Alignment literature by demonstrating practical limits of current alignment methods.
- Relevant to Prompt Optimization and In-Context Learning, which reveal how model behavior can be steered via input design.
Notes¶
Strengths: - Systematic, automatic approach to generating adversarial examples—no human engineering required. - Strong empirical results on diverse models, with well-controlled experiments. - Careful responsible disclosure process before publication. - Surprising transferability: a single suffix works across very different models.
Weaknesses: - The transferability gap between models (87.9% on GPT-3.5 vs. 2.1% on Claude-2) limits practical applicability to all systems. - The paper doesn't deeply analyze why certain models are robust while others aren't—only speculates about training distribution similarities. - The "Sure, here is..." priming is partly a known jailbreaking technique; the main novelty is the automation of suffix discovery. - Limited discussion of defenses beyond noting that adversarial training and input filtering are historically ineffective.
Research directions: - Understanding transferability: why does Claude-2 resist these attacks so much better? - Developing defenses that don't rely on detection or filtering, but on fundamental architectural changes. - Exploring whether similar attacks exist in multimodal or code generation settings.