The Evolution of Distributed Systems for Graph Neural Networks and their Origin in Graph Processing and Deep Learning: A Survey¶
Authors: Jana Vatter, Ruben Mayer, Hans-Arno Jacobsen Venue: ArXiv, 2023 arXiv: 2305.13854
TL;DR¶
This survey systematically examines distributed systems for scalable GNN training, bridging graph processing systems (Pregel, PowerGraph, GraphLab) and DNN training systems (TensorFlow, PyTorch) to show how techniques from both domains inform GNN system design. The paper categorizes methods across partitioning, sampling, communication, synchronization, and parallelism, providing practitioners a foundation for choosing and implementing distributed GNN architectures.
Contributions¶
- Unified framework connecting three domains: graph processing systems, distributed DNN training systems, and distributed GNN systems, showing how techniques evolved across each
- Comprehensive categorization of distributed GNN training methods across:
- Partitioning strategies (edge-cut, vertex-cut, balanced, online/offline, feature engineering)
- Sampling techniques (vertex-wise, layer-wise, importance-based, cluster-based, neighborhood sampling)
- Inter-process communication (caching strategies, importance-based vertex caching, distributed storage)
- State synchronization (synchronous, asynchronous, hybrid modes)
- Parallelism models (data, model, hybrid parallelism)
- Programming abstractions (message passing, dataflow, vertex-centric)
- System-level analysis of 20+ distributed GNN implementations (NeuGraph, DistDGL, GraphSAINT, P³, DGL, AGL, PaGraph, DistGNN)
- Connections to practice showing how large-scale GNN training is adapted to real-world graph characteristics (skewed degree distributions, heterogeneous networks)
Method¶
The survey structures distributed GNN training into foundational topics and system design dimensions:
Foundations (Section 2) cover graph processing basics (vertices, edges, connectivity), distributed graph processing (MapReduce, Pregel, PowerGraph, vertex-centric and block-centric models), and distributed DNN training (data/model parallelism, synchronization modes, coordination strategies).
GNN Training Basics (Section 3.1) explain the GNN computation model: vertices are initialized with features, messages are aggregated from neighbors using an aggregation function, and activations are updated via an update function. This process repeats for k layers, with each layer expanding the receptive field by one hop.
Distributed GNN Systems (Section 3.2–3.9) cover:
-
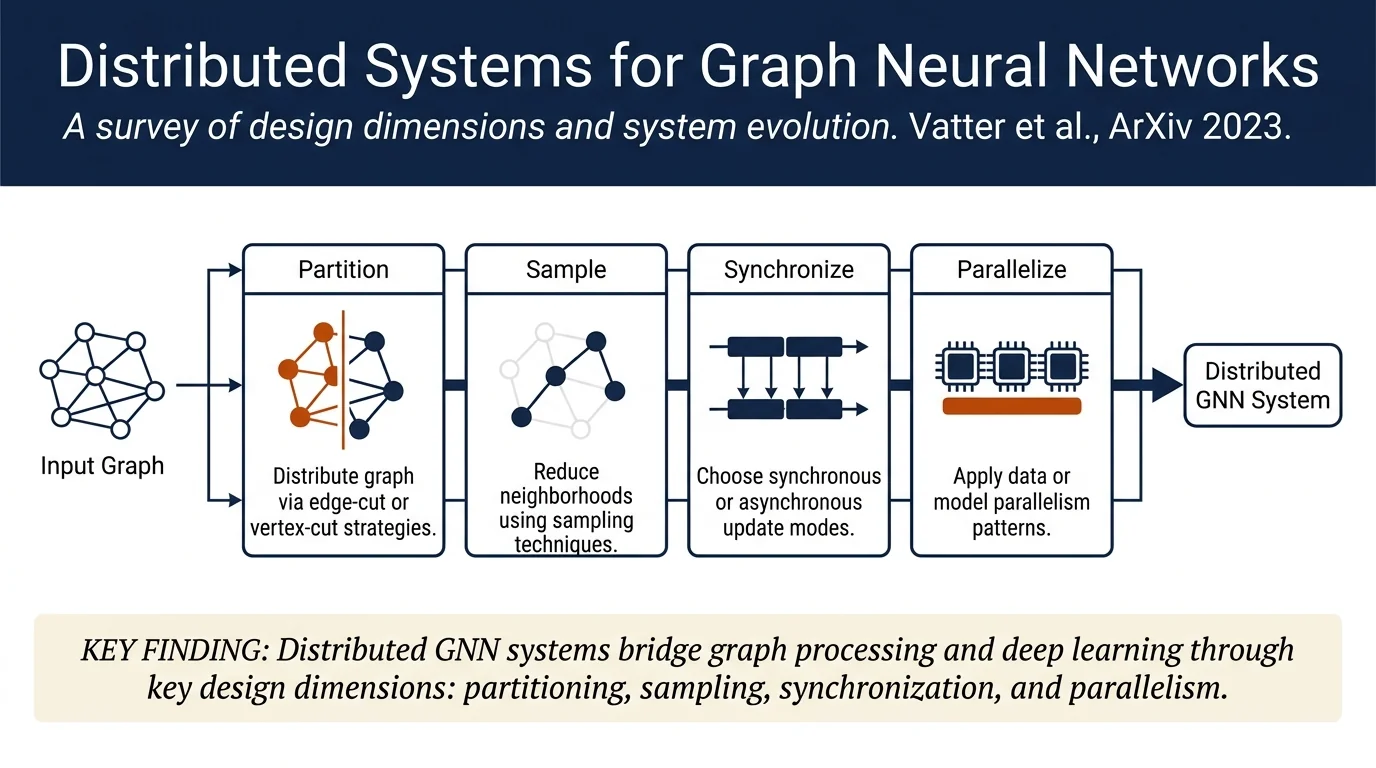
Partitioning (Section 3.2.1): Graphs are partitioned across workers using edge-cut (assigns edges to machines, may replicate vertices), vertex-cut (assigns vertices, replicates edges), or balanced approaches. Strategies include METIS, streaming partitioners, and specialized methods like GrETa (dataflow-based) and ZIPPER (edge-centric with equality constraints).
-
Sampling (Section 3.2.2): Reduces neighborhoods to prevent explosion; methods include vertex-wise (random selection), layer-wise (fixed neighborhood size per layer), importance-based (biased toward important vertices), and cluster-based sampling (e.g., ClusterGCN).
-
Communication (Section 3.2.4): Vertices cache neighbors, features, or aggregated values; importance-based caching prioritizes frequently accessed data; distributed key-value stores enable shared memory across machines.
-
Synchronization (Section 3.2.4): Synchronous modes (all workers finish before next iteration) vs. asynchronous (updates as ready); hybrid approaches balance convergence and throughput.
-
Parallelism (Section 3.2.5): Data parallelism (graph split, model replicated), model parallelism (model split across machines), or hybrid; edge/vertex parallelism distinguishes matrix multiplication strategies.
-
Message Propagation (Section 2.2.5): Pregel-based (push/pull semantics) or dataflow-based (computation as explicit graph of transformations).
-
Programming Abstractions (Section 3.2.3): Message passing APIs (Pregel-style), dataflow models (MapReduce-style), vertex-centric (Pregel), edge-centric, or hybrid abstractions; systems like PyG Geometric, DGL, and SAGA-NN hide complexity behind high-level APIs.
Results¶
The paper presents a taxonomy rather than experimental results, but key insights include:
- Partitioning trade-offs: Edge-cut reduces computation cost but increases communication; vertex-cut balances better for power-law graphs; balanced strategies suit heterogeneous topologies
- Sampling benefits: Layer-wise and importance sampling reduce memory and communication compared to full-batch training
- Communication bottleneck: Inter-process communication is the primary bottleneck in large-scale GNN training; caching and sampling strategies directly address this
- System coverage: 20+ systems analyzed, ranging from academic prototypes (NeuGraph, DistDGL) to production frameworks (DGL, AGL), with different trade-offs in ease of use, performance, and flexibility
- Evolution pattern: Early systems adapted Pregel (PowerGraph). Recent systems unify graph processing and DNN training paradigms, exposing partitioning and sampling as first-class knobs
Connections¶
- Related to Geometric Deep Learning: Grids, Groups, Graphs, Chains and Gauges which provides foundational GNN architectures (GCN, GAT, GraphSAGE) that distributed systems implement
- Complements Learning Rumor Spreading with Tree Kernel and Rumor Detector Using Kernel Subgraph which use graph-based approaches for misinformation detection; distributed GNN systems enable scaling these to large networks
- Related to Rumor Detection Using Recursive Visual and Textual Neural Networks which uses neural networks on rumor propagation graphs; distributed GNN training enables such approaches at scale
- Informs Hierarchical Attention Networks for Document Classification and Rumor Detection which applies hierarchical GNN designs to rumor cascades
Notes¶
Strengths: - Uniquely comprehensive, bridging systems and ML: most GNN papers focus on algorithms; most systems papers focus on DNN/graph processing independently. This survey synthesizes all three - Practical focus on implementation choices: partitioning, sampling, and communication strategies are decision points practitioners face, and the paper categorizes them clearly - Extensive coverage of 20+ systems with detailed tables (categorization tables for each technique) aid comparison - Connection to prior art: sections on related work surveys in graph processing and DNN training contextualize the field - Mathematical clarity: GNN computation model (equations 1–2) and distributed system diagrams (Figures 2–3) are clear
Weaknesses: - Survey, not experimental: no benchmarks comparing systems on standard graphs (e.g., OGB datasets) or datasets; recommendations are qualitative - Limited coverage of fault tolerance and recovery: distributed systems face node failures, but the paper does not address checkpointing or recovery strategies - GNN architectures (GCN, GAT, GraphSAGE) covered briefly; readers unfamiliar with GNNs may struggle with Section 3.1 - Scope limited to training; inference on distributed systems is not covered - Limited discussion of heterogeneous graphs: most coverage assumes homogeneous node/edge types, though real misinformation networks (users, posts, shares) are heterogeneous
Relevance to misinformation detection: GNNs are widely used for fake news and rumor detection by modeling information diffusion as graphs (user-post networks, retweet cascades, claim-article-source networks). This survey's treatment of partitioning and sampling directly applies: rumor detection networks are often power-law (dominated by a few viral posts), requiring careful partitioning; sampling strategies ensure training doesn't time out on large cascades. Systems like DGL (widely used in misinformation research) implement many of the abstractions discussed here.