Detect Rumors in Microblog Posts Using Propagation Structure via Kernel Learning¶
Authors: Jing Ma, Wei Gao, Kam-Fai Wong
Venue: ACL (55th Annual Meeting), Vancouver, Canada, July 30 - August 4, 2017
DOI: 10.18653/v1/P17-1066
TL;DR¶
This paper addresses rumor detection in microblog posts by modeling information diffusion as propagation trees and proposing a kernel-based method (PTK) that captures high-order structural patterns differentiating rumors from non-rumors. The approach extends to context-sensitive variants (cPTK) and achieves superior early detection performance on Twitter datasets, outperforming state-of-the-art feature-based and RNN methods by directly learning from structural patterns rather than hand-crafted features.
Contributions¶
- Proposes Propagation Tree Kernel (PTK), a novel kernel method that evaluates similarity between propagation trees to detect rumors
- Extends PTK to context-sensitive variant (cPTK) that considers propagation paths from root to subtrees
- Formulates rumor detection as a finer-grained four-class problem (false, true, unverified rumor, non-rumor) rather than binary classification
- Demonstrates strong early detection performance: 75% accuracy on Twitter15 and 73% on Twitter16 within 24 hours
- Constructs and releases public Twitter15/Twitter16 datasets with propagation trees and ground truth annotations
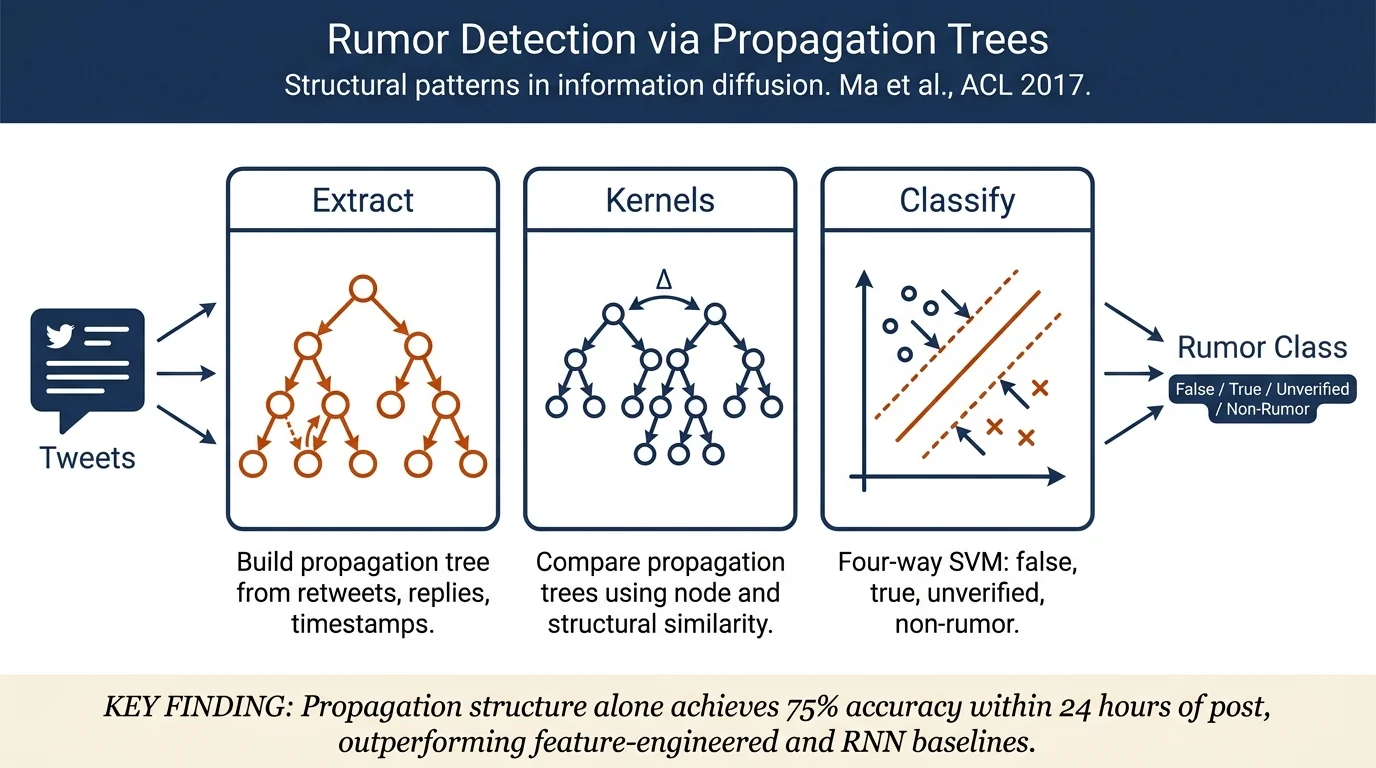
Method¶
The paper models microblog diffusion as trees where nodes represent retweets/replies and edges represent response relations. Each node v is represented as a tuple (u_v, c_v, t_v): user attributes, post content, and time lag from source tweet.
Propagation Tree Kernel (PTK): Unlike traditional tree kernels designed for parse trees, PTK handles propagation trees where nodes are continuous vectors (user/content/temporal features). PTK defines node similarity as:
f(v_i, v_j) = e^{-t} (αE(u_i, u_j) + (1-α)J(c_i, c_j))
where t is time difference, E is Euclidean distance for user similarity, J is Jaccard coefficient for content similarity, and α trades off user vs. content signals. The kernel then recursively measures subtree similarity, using f ∈ [0,1] for soft matching rather than exact discrete productions.
Context-sensitive PTK (cPTK): Extends PTK by considering the entire path from root to each subtree, capturing how information propagates before reaching a particular subtree. Useful for modeling temporal context: a questioning message early vs. late carries different signals about rumor veracity.
Both variants feed into a one-vs-all SVM classifier for the four-class problem.
Results¶
On Twitter15 dataset, cPTK achieves 75.0% accuracy overall, with per-class F1 scores: non-rumor 0.804, false 0.698, true 0.765, unverified 0.733. On Twitter16: 73.2% accuracy with F1 scores 0.740, 0.709, 0.836, 0.686 respectively. All variants (PTK-, cPTK-, PTK, cPTK) substantially outperform baselines including SVM-TS (temporal features), RFC (random forest, feature-engineered), and GRU (RNN-based). Early detection curves show cPTK maintains advantage over all baselines within the critical first 24 hours. Ablations show both user properties and context-sensitive modeling contribute meaningfully; content-only variants (PTK-, cPTK-) still beat GRU baseline.
Connections¶
- Related to 2016 Ma Rumor Rnn (same authors' RNN approach to rumor detection; this work extends structural focus beyond temporal)
- Applies tree kernel techniques to social media, extending Collins & Duffy's syntactic tree kernels to continuous-valued nodes
- Cited by 2018 Ma Fakenewsnet for propagation-based detection methodology
- Compared against feature engineering approaches in Castillo et al. 2011 and Kwon et al. 2017
Notes¶
Strengths: The core insight is elegant: rumors have distinctive structural patterns in how they spread (initial low-influence users, inflection when high-influence nodes amplify). The kernel method naturally captures these without manual feature design. Early detection results are practically valuable. The extension from binary to quaternary classification (false/true/unverified/non-rumor) is more realistic than prior binary formulations. Datasets are made public.
Limitations: Approach requires complete propagation trees (retweets + replies), limiting applicability to platforms with accessible reply/retweet data. Only Twitter validation; unclear how well propagation patterns transfer to other social networks (Facebook, Reddit, etc.). User features (follower count, verification status) are platform-specific. No analysis of which subtree patterns are most discriminative—results are implicit in the kernel. Context-sensitive PTK improves rumors but hurts non-rumor detection, suggesting the context signal is class-dependent in ways not fully understood.
Future directions: Graph representation learning as alternative to kernel methods; application to multimodal rumors with images/video; investigation of why cPTK helps rumors but not non-rumors; cross-platform validation.