Adapting Fake News Detection to the Era of Large Language Models¶
Authors: Jinyan Su, Claire Cardie, Preslav Nakov
Venue: arXiv, 2023 — arxiv:2311.04917
TL;DR¶
As large language models proliferate and machine-generated text becomes prevalent, traditional fake news detectors trained exclusively on human-written content are increasingly unreliable. This paper evaluates fake news detectors across three hypothetical eras—human-written dominance, mixed human-machine content, and machine-generated dominance—revealing that detectors trained on human-written fake news fail to generalize to machine-generated fakes. The authors recommend training detectors on balanced datasets mixing human-written and machine-generated content to improve robustness and cross-domain generalization.
Contributions¶
- First comprehensive evaluation of fake news detectors across diverse scenarios with both human-written and machine-generated content (HF, HR, MF, MR).
- Empirical evidence that detectors trained exclusively on human-written fake news (HF/HR) generalize poorly to machine-generated fake news (MF).
- Analysis of class-wise accuracy patterns across transformer models (RoBERTa, BERT, ELECTRA, ALBERT, DeBERTa) showing that balanced training data improves performance on all subclasses.
- Practical guidelines and recommendations for deploying fake news detectors in real-world contexts where both human and machine-generated content coexist.
- Framework for understanding data distribution shifts in fake news caused by the adoption of large language models.
Method¶
The paper proposes three experimental stages representing different content generation eras:
Human Legacy¶
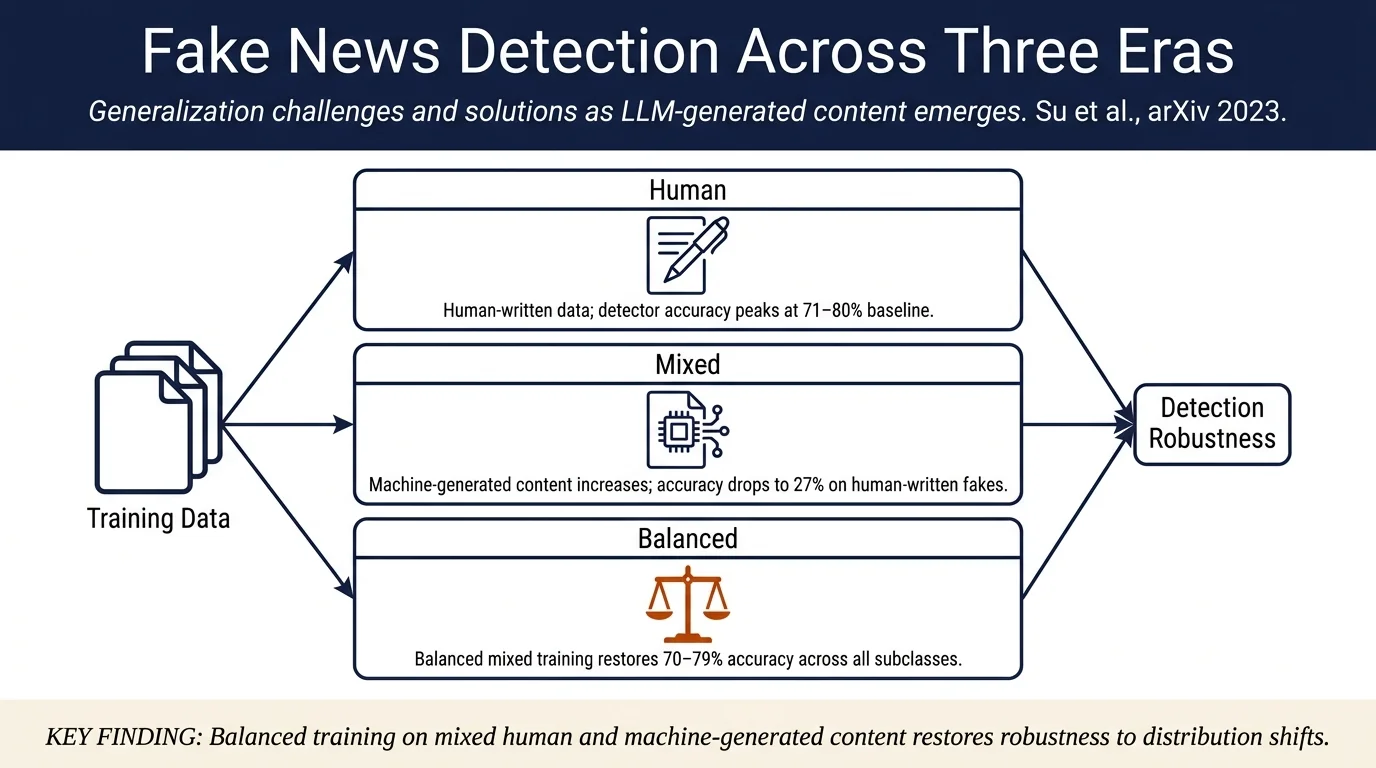
The classical setting where all training and test data consist of human-written real and fake news. Detectors achieve balanced and high accuracy across all subclasses (real/fake, human-written only).
Transitional Coexistence¶
The current realistic scenario where both human-written and machine-generated articles exist. Training data is mixed, with incrementally increasing fractions of machine-generated fake news (0%, 33%, 50%, 67%, 100% of the fake class). This stage models a transition period.
Machine Dominance¶
A hypothetical future where machine-generated real news articles dominate and serve as the primary source for real news. Training and test data consist of machine-generated real articles and either human-written or machine-generated fake articles.
Models tested: Transformer-based classifiers including BERT, RoBERTa, ELECTRA, ALBERT, and DeBERTa (both base and large variants).
Datasets: GossipCop++ and PolitiFact++ constructed from FakeNewsNet, with balanced subclasses: human-written fake (HF), human-written real (HR), machine-paraphrased real (MR), machine-generated fake (MF).
Evaluation: Subclass-wise accuracy for each of the four content types, enabling fine-grained analysis of detector biases.
Results¶
Key Findings¶
-
Human Legacy Stage: Detectors trained on human-written data achieve balanced high accuracy (71–80% across subclasses). When exposed exclusively to human-written data, detectors generalize well within this setting.
-
Critical Generalization Gap: When detectors trained exclusively on human-written fake news encounter machine-generated fake news, accuracy drops dramatically. Conversely, detectors trained only on machine-generated fake news perform worse at detecting human-written fakes. This asymmetry reveals a significant generalization gap.
-
Transitional Coexistence: As the fraction of machine-generated fake news increases from 0% to 100%:
- Machine-generated fake (MF) detection accuracy rises from ~44% to ~99%, suggesting detectors learn spurious source-distinguishing features.
- Human-written fake (HF) detection accuracy plummets from 71% to 27%, indicating model bias toward machine-generated patterns.
-
Machine-generated real (MR) detection accuracy drops, and human-written real (HR) accuracy becomes volatile.
-
Balanced Training Strategy: Training on balanced mixtures of human-written and machine-generated fake news stabilizes performance. In-domain accuracy remains relatively high (~70–79%) for all subclasses when training data is balanced (e.g., 50% HF, 50% MF).
-
Out-of-Domain Performance: The gap between in-domain and out-of-domain (cross-dataset) detection widens as machine-generated content increases in training. Mixing in some machine-generated real news (MR) during training helps close this gap and improves generalization to unseen data.
-
Model Size Trade-off: Larger models (RoBERTa-large, ALBERT-large) do not universally outperform smaller variants. Model size introduces biases; the base variants often yield better balance across subclasses, especially when facing distribution shifts.
-
Recommendation: For practical deployment, train detectors using a balanced mixture of human-written and machine-generated fake articles. This approach yields better performance on all subclasses and improves robustness to distribution shifts compared to training solely on human-written data.
Connections¶
- Solaiman et al. (2019) on OpenAI release strategies provides foundational analysis of GPT-2 detection capabilities and the arms race between generation and detection.
- Wang et al. (2024d) on the factuality of language models and risk of misinformation pollution examine related challenges of LLM-generated content; this paper complements that work with empirical evaluation of detection robustness.
- Khan et al. — Benchmark of ML models comprehensively compares traditional and transformer-based approaches on fake news datasets; this paper extends that work to machine-generated content scenarios.
- Fake news detection covers broader detection methods and datasets foundational to this work.
- AI-Generated Content and LLM-Generated Misinformation address related challenges in detecting AI-produced content.
- Pre-trained language models and BERT and transformer embeddings provide context on the detector architectures used (RoBERTa, ELECTRA, ALBERT, DeBERTa).
- Fake news detection methods surveys detection techniques that this work evaluates in a new distribution-shift context.
Notes¶
This work addresses a timely and pressing gap in fake news detection research. Most prior work assumes human-written fake news or ignores machine-generated content entirely. As LLMs become widespread, both for benign and malicious purposes, understanding detector robustness across mixed content landscapes is essential.
Strengths: - Comprehensive evaluation across four content subclasses and three temporal eras provides a clear, actionable framework. - Practical recommendations (balanced training, acknowledging model biases) are immediately applicable to practitioners. - Multiple transformer architectures and dataset scales are tested, increasing generalizability of findings. - The staged evaluation (Human Legacy → Transitional Coexistence → Machine Dominance) elegantly models realistic content evolution.
Limitations and Future Directions: - Evaluation is limited to two datasets (GossipCop++ and PolitiFact++); coverage of additional domains (health, science, politics in other languages) would strengthen conclusions. - The paper uses coarse-grained proportions (0%, 50%, 100% machine-generated) and could benefit from finer-grained analysis to pinpoint exact transition thresholds. - Human-AI co-authored content (where human-written text is enhanced by machines, or vice versa) merits separate investigation. - Future work should explore adaptive or curriculum-based training strategies to mitigate distribution shift without sacrificing performance on any subclass. - Studying the evolution of machine-generated and human-written text distributions over time (as models improve and writers adapt) would provide a more nuanced view of data distribution drift.
Impact: This work lays the groundwork for responsible fake news detection in an era where the boundary between human and machine content blurs. It raises awareness of potential risks and provides concrete, evidence-based strategies for practitioners building robust detection systems.