Release Strategies and the Social Impacts of Language Models¶
Authors: Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, Jasmine Wang
Venue: OpenAI Report, November 2019 — arXiv:1908.09203
TL;DR¶
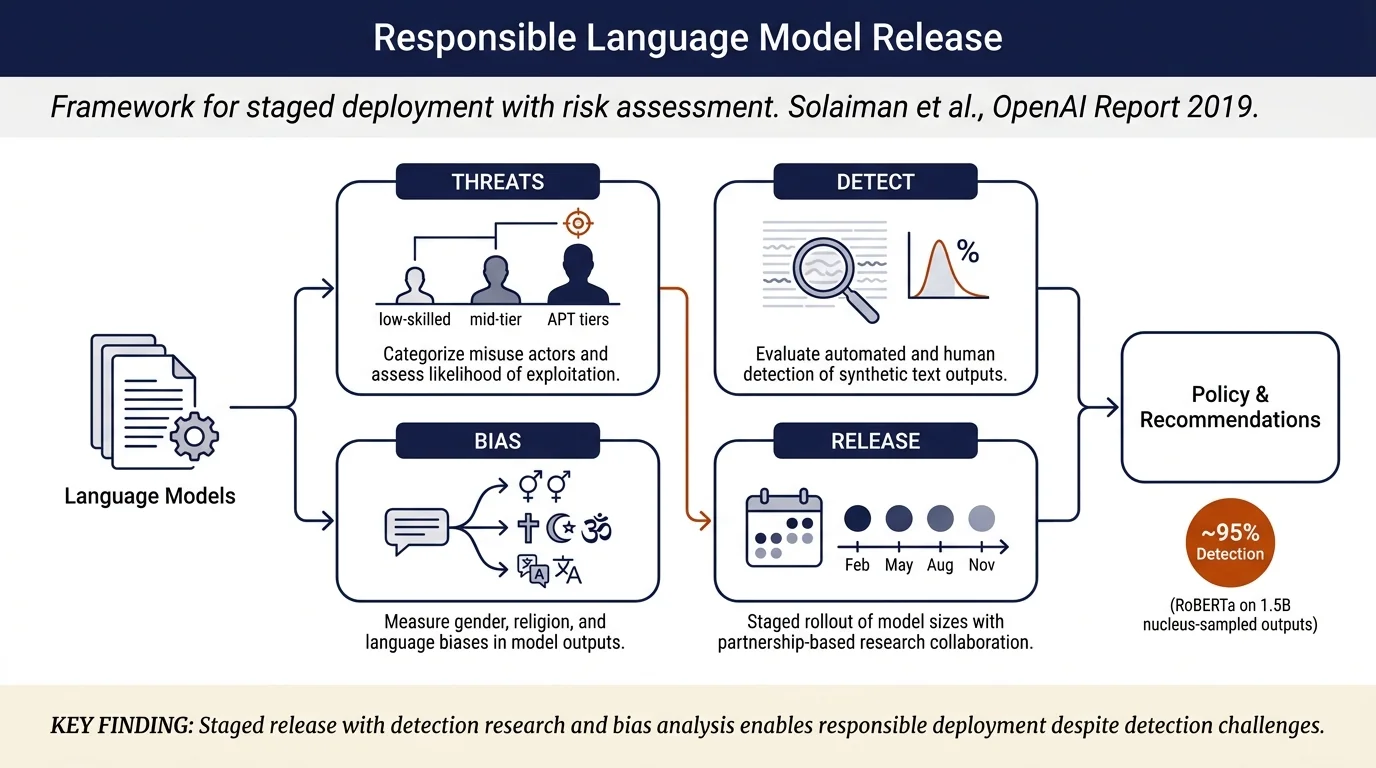
OpenAI's report on GPT-2 staged release and responsible publication of large language models. The authors adopted a nine-month staged release (Feb–Nov 2019, models from 124M to 1.5B parameters) to mitigate misuse risks while enabling beneficial research. They conducted partnership-based risk analysis on synthetic text generation, detection, and bias, finding minimal evidence of planned misuse but identifying technical and social challenges for deployment. The report offers recommendations for responsible release norms in the AI community.
Contributions¶
- Staged release methodology: Iterative release of increasingly capable models paired with risk analysis, allowing time for defenses and community adaptation.
- Misuse threat landscape: Tiered actor assessment (low-skilled/ideological, mid-tier toolmakers, advanced persistent threats), finding low immediate risk but acknowledging long-term uncertainty.
- Detection research: Evaluation of human and machine detection of GPT-2 outputs; simple classifiers achieve 88–74% accuracy depending on model size; RoBERTa-based detectors achieve ~95% on 1.5B outputs.
- Bias analysis: Exploratory study of gender, race, religion, and language preference biases in 774M and 1.5B parameter models; biases reflect training data representation.
- Partnership framework: Legal agreements enabling external research teams to assess misuse potential without premature release.
- Recommendations: Three-point framework for responsible publication—decision-making tradeoff frameworks, infrastructure for distributed risk analysis, and communication channels across AI organizations.
Method¶
Staged Release Process: GPT-2 variants (124M, 355M, 774M, 1.5B parameters) released at different times (Feb, May, Aug, Nov 2019) to enable risk analysis at each stage. By February 2019, OpenAI published baseline results on generating text; delayed larger model releases based on threat assessment.
Misuse Actor Assessment: Researchers examined public forums, threat reports, and security expert input to categorize potential misusers: 1. Low-skilled: ideologically motivated or curious, data-poisoning approaches 2. Mid-tier: capable of building tools for forums/social media; limited immediate evidence 3. Advanced persistent threats (APTs): state actors; difficult to observe; likely to replicate models regardless of release
Detection Evaluation: - Human detection: Crowdworkers evaluated cherry-picked GPT-2 outputs (355M, 774M, 1.5B) for credibility vs. New York Times articles. 355M outputs were ~66% credible; 774M and 1.5B near 75%. - Automated detection: Fine-tuned RoBERTa classifiers on TF-IDF n-gram and bigram features. Achieves 88% accuracy on 124M outputs, 74% on 1.5B (Temperature=1). RoBERTa base achieves ~95% on 1.5B nucleus-sampled outputs. Detection sensitivity to sampling method (nucleus vs. Top-K).
Bias Analysis: Internal testing and external partnerships (University of Oregon) developed bias probes. Examined associations between words and demographic categories (gender: "criminal" ↔ male; religion: "God" ↔ Christianity). Published top training domains in WebText dataset and model card with bias findings.
Partnership Research: External teams studied: - Cornell University: Human susceptibility to GPT-2-generated disinformation - Middlebury CTEC: Fine-tuning GPT-2 on extremist material; outputs more ideologically consistent; fine-tuning reduces detection by existing systems - University of Oregon: Bias probe development - University of Texas Austin: Statistical detectability of GPT-2 outputs after fine-tuning
Results¶
Detection Performance: - Simple logistic regression on TF-IDF features: 88% accuracy (124M parameters) to 74% (1.5B). - RoBERTa fine-tuned detection: ~95% accuracy on 1.5B nucleus-sampled outputs; accuracy varies with sampling method (nucleus easiest, Top-K harder). - Nucleus sampling outputs harder to distinguish from human text than Top-K. - Fine-tuning reduces detection: GROVER (another model) baseline detection drops significantly after GPT-2 fine-tuning.
Human Credibility: - GPT-2 1.5B outputs rated ~75% as credible (similar to real NYT articles). - Credibility scores vary less across model sizes than accuracy; humans rely on story plausibility (clarity, believability) more than accuracy. - Participants explained inaccuracies but assigned high credibility, suggesting high trust despite errors.
Bias Findings: - Gender bias: "criminal" associated with male identity; strong associations across 774M and 1.5B. - Religion bias: "God" strongly associated with Christianity. - Language preference: 1.5B more receptive to non-English and non-Latin scripts than 774M. - No statistically significant differences in gender/race bias between 774M and 1.5B.
Threat Landscape: - Minimal evidence of planned misuse in public forums; some discussion of generative capabilities but limited technical understanding. - Discussions suggest lower-tier actors interested in spam/phishing; no clear APT engagement observed. - Fine-tuning is a key variable affecting both misuse potential and detection difficulty.
Connections¶
- Synthesis and survey: Gehrmann et al. (2019) — GLTR: Detecting Generated Text shows rank-based detection using language model probabilities; OpenAI's RoBERTa approach is more effective but less interpretable.
- Competing model release: Zellers et al. (2019) — Grover: Defending Against Neural Fake News released GROVER (news-specialized) weeks later; uses similar staged approach; shows GROVER detects its own generations but is vulnerable to fine-tuning.
- Bias in language models: Bolukbasi et al.'s "Man is to Computer Programmer as Woman is to Homemaker" quantifies gender bias in word embeddings; OpenAI extends this to generation bias.
- Synthetic text and credibility: Kreps et al. (Cornell partnership work) showed humans find GPT-2-generated text credible despite inaccuracies.
Notes¶
This report is foundational for understanding dual-use concerns in language model release. The staged release strategy became a reference model for subsequent large model deployments (GPT-3, LLaMA, others). Key strengths: concrete threat modeling, partnership-based risk analysis, and transparent documentation of biases via model card. Weaknesses: detection evaluation is limited to in-house models; generalization to other families unclear; APT threat assessment is speculative. The report's framing of "security through transparency" (releasing smaller models first) later faced criticism as the gap between detection and generation narrows. Valuable for understanding policy trade-offs between openness and safety.