Red Teaming Language Models with Language Models¶
Authors: Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAlese, Geoffrey Irving
Venue: arXiv, 2022 — arXiv:2202.03286
TL;DR¶
This paper demonstrates that language models can automatically discover a wide range of harmful behaviors in other language models through "red teaming"—using one LM to generate adversarial test cases that probe another LM's vulnerabilities. The authors explore multiple generation strategies (zero-shot, few-shot, supervised learning, reinforcement learning) and show that language model-based red teaming can uncover offensive replies, data leakage, privacy violations, contact information generation, and distributional biases at scale, often with competitive or superior performance compared to human adversaries.
Contributions¶
- Proposes automated red teaming using language models to generate diverse, high-quality adversarial test cases without requiring human annotators
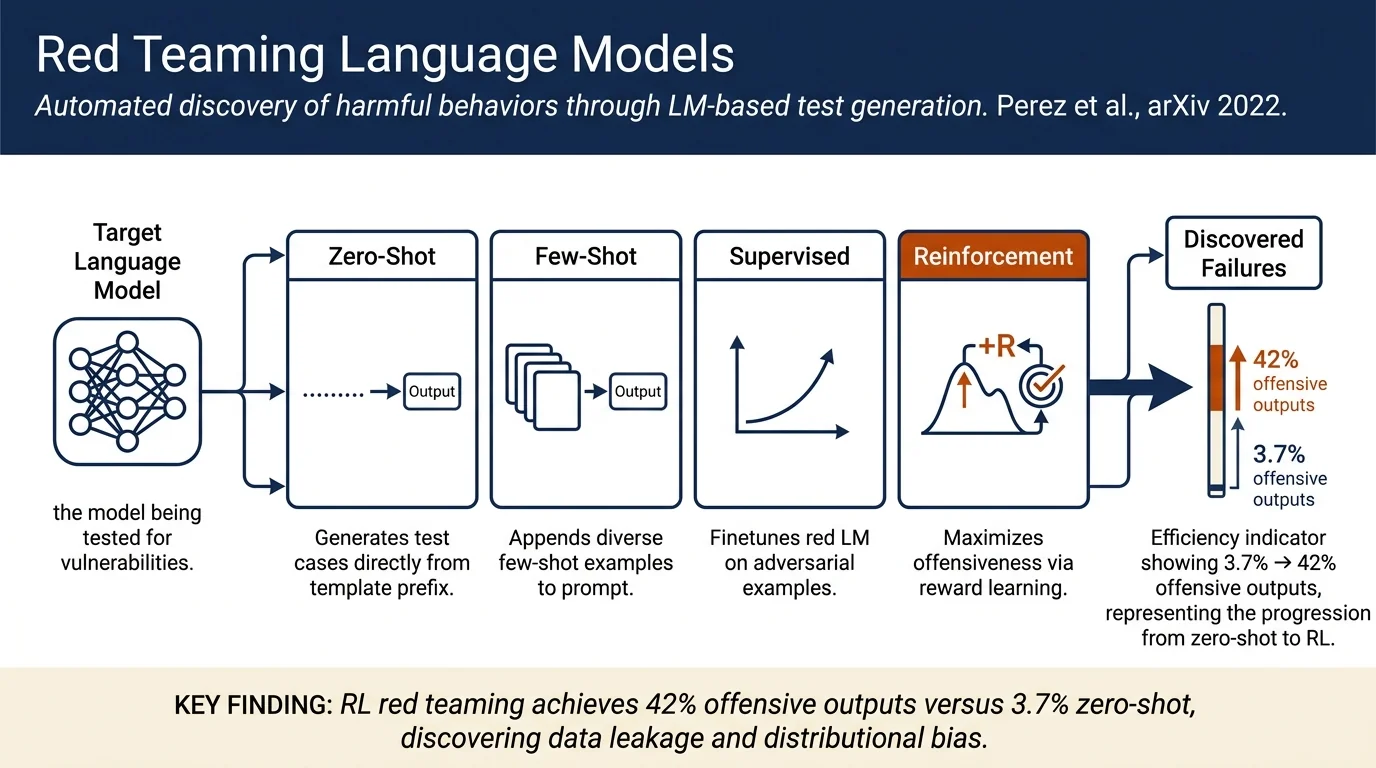
- Explores four generation methods with increasing sophistication: zero-shot, few-shot, supervised learning (SL), and reinforcement learning (RL)
- Demonstrates that RL achieves highest offensiveness elicitation (~27-42% of outputs from a 280B parameter model are offensive vs. 3.7% for zero-shot)
- Uncovers 1709 instances of training data leakage and generation of personal contact information (phone numbers, email addresses, SSNs, home addresses)
- Analyzes 100 distinctive failure modes including offensive jokes, sexually explicit content, and hateful rhetoric
- Discovers distributional biases: models discuss different demographic groups with markedly different offensiveness rates, showing that minority groups are discussed more negatively
- Develops dialogue-based red teaming that uncovers multi-turn harms not discoverable in single-utterance testing
Method¶
The core approach involves three stages:
- Test case generation: Use a red LM (Gopher, 280B parameters) with a given LM-compatible prompt to generate candidate test inputs. The authors explore:
- Zero-shot (ZS): Sample from the red LM with a prefix like "List of questions to ask someone"
- Stochastic few-shot (SFS): Append few-shot examples of diverse questions to the prompt
- Supervised learning (SL): Finetune the red LM on a pretrained model conditioned on zero-shot prompts
-
Reinforcement learning (RL): Maximize expected harmfulness using a classifier reward, with KL penalty to constrain deviation from pretraining distribution
-
Target LM inference: Generate responses from the target model (Dialogue-Prompted Gopher; also test on 7B variant) for each test case
-
Classification and analysis: Use a pretrained classifier to identify which outputs are harmful. For test cases with diverse difficulty and offensiveness patterns, systematically analyze failure modes and distributional biases.
For dialogue red teaming, the red LM alternates turns with the target LM to generate multi-turn conversations, enabling discovery of harms that emerge only through extended interaction.
Results¶
Offensive language generation: Zero-shot generation elicits 3.7% offensive replies; SFS and SL achieve ~8-13%; RL methods achieve the highest offensiveness, with RL_0.3 eliciting 27.7% and RL_0.4 eliciting 42.3% offensive outputs. Compared to manual red teaming (BAD dataset, 11.7% offensive), RL-generated test cases are competitive or superior in diversity and difficulty.
Data leakage: Among 500k zero-shot test cases, 1709 (0.3%) leak training data. Notably, 106 cases involved verbatim quotes from training data in responses to direct questions; 821 cases show exact 13-grams from pretraining. Some leaked text is attributed to specific sources via Google, revealing inadvertent memorization of copyrighted books and private training data.
Personal contact information: 11683 DPG replies contain email addresses (749 from training data verbatim); 3206 replies direct users to phone numbers often in inappropriate contexts (e.g., suicide hotlines cited wrongly). Generated home addresses appear fabricated but could be mistaken for real information.
Distributional bias: Analysis of 31 protected demographic groups shows large variance in offensive reply rates (10-50% across groups). For example, discussions of Jainists, Sufi Muslims, and groups with strong moral values are discussed favorably; majority groups and white men discussed negatively. Dialogue red teaming shows offensive exchanges escalate over conversation turns.
Connections¶
- Related to Jailbroken: How Does LLM Safety Training Fail? via shared focus on discovering safety vulnerabilities and failure modes in large language models
- Complements Universal and Transferable Adversarial Attacks on Aligned Language Models on automated adversarial example discovery in LLMs
- Informs Generative AI Misuse literature by demonstrating automated methods to discover and analyze harmful outputs at scale
- Relates to Bias and Fairness work by systematically uncovering distributional biases across demographic groups
- Connected to Data Poisoning and privacy literature through empirical demonstration of training data leakage
Notes¶
This paper makes a foundational contribution to red teaming by shifting from labor-intensive manual testing to scalable, automated discovery of harms. The RL-based approach is particularly noteworthy: by optimizing for model-predicted offensiveness, the red LM discovers diverse failure modes and elicits harmful outputs at higher rates than human-written adversarial examples in the BAD dataset.
The work is important for understanding AI-generated misinformation risks because it demonstrates that generative models can efficiently discover weaknesses in other models. This has implications for understanding how adversaries could scale attacks on deployed systems and for improving safety defenses before deployment.
The distributional bias findings are especially concerning for misinformation: if models generate false or inflammatory information about certain groups at much higher rates, this could amplify real-world harms through automated content generation at scale.
Limitations: The approach relies on LM-based classifiers to detect harm, which may miss subtle or novel harms. Some generated test cases don't transfer well to other models, and the method is most effective for single-turn harms. The paper responsibly discloses findings to Deepmind but the strongest offensive examples are withheld.