Real or Fake Text?: Investigating Human Ability to Detect Boundaries Between Human-Written and Machine-Generated Text¶
Authors: Liam Dugan, Daphne Ippolito, Arun Kirubarajan, Sherry Shi, Chris Callison-Burch
Venue: arXiv:2212.12672 — Link
TL;DR¶
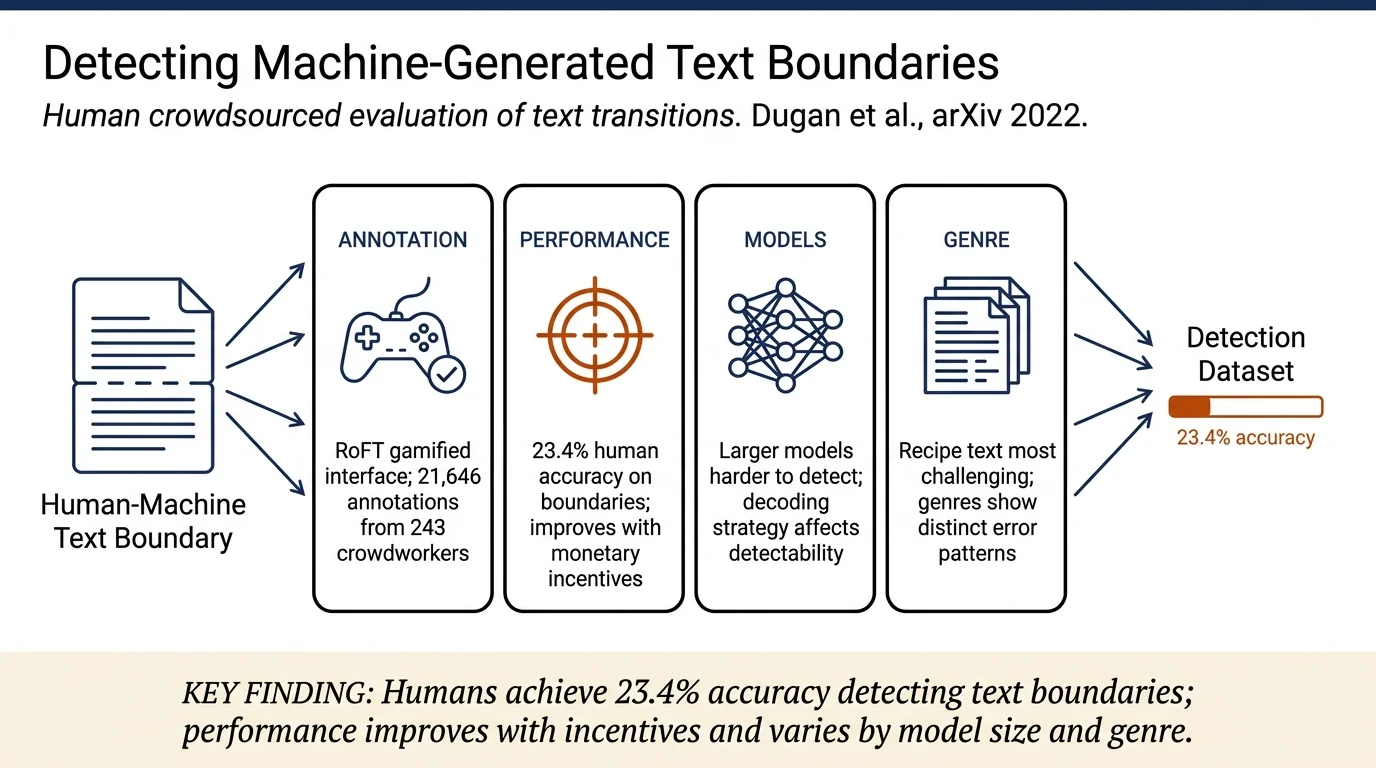
Dugan et al. investigate human ability to detect boundaries where text transitions from human-written to machine-generated, a more realistic and challenging task than binary fake/real classification. They introduce the RoFT (Real or Fake Text) game platform for crowdsourced annotation and release a dataset of 21,000+ annotations across four text genres. Key findings: humans significantly outperform random chance (23.4% vs. 10%), improve with monetary incentives, larger models produce harder-to-detect text, and different genres exhibit distinct error patterns.
Contributions¶
- Boundary detection task formulation: Reframes fake text detection as identifying where text transitions from human-written to machine-generated rather than binary classification, a more realistic and challenging problem.
- RoFT game platform: Gamified annotation interface where players identify the sentence where a document transitions from human-written to machine-generated; includes RoFT as a platform for future research.
- Large-scale annotated dataset: 21,646 annotations from 243 participants across 7,895 documents spanning four genres (News, Stories, Recipes, Speeches) with error classifications; fully anonymized and publicly available.
- Comprehensive analysis of detection difficulty: Documents how model size (GPT-2 vs. GPT-2 XL), decoding strategy (p=0.0 vs. p=0.4), text genre, and player expertise affect detectability and human performance over time.
- Error taxonomy: Systematizes the types of errors humans identify (grammar, repetition, irrelevance, contradictions, common-sense, coherence, generic language) and shows genre-specific error profiles.
- Skill variation and learning: Demonstrates substantial skill variance across players with some performing 3× better than others; players with monetary incentives (Group B) improve over time while unincentivized group (Group A) remains flat.
Method¶
Task design:
Players view documents sentence by sentence. They are shown sentences from the start of the document until a transition point, where remaining sentences are machine-generated by a language model. After reading, players must identify the sentence where they think the transition occurs. Explicitly told to select the first machine-generated sentence in the passage. Points awarded for correct identification (5 points for exact boundary + max(3-n, 0) for nearby guesses where n is distance from true boundary).
Participant groups:
- Group A (N=141): No monetary incentives; played 50 game rounds; received 2 bonus points of class extra credit.
- Group B (N=102): Offered $2/250 points of extra credit toward their grade, plus explicit instruction and help guide.
Datasets:
Four text genres sampled from different sources:
- News: New York Times Annotated Corpus (1,838 documents); processed via spaCy for sentence segmentation and named entity recognition.
- Stories: Reddit Writing Prompts and Fan Fiction; amateur short stories to test writing-quality effects (9,864 documents).
- Recipes: Recipe1M+ dataset; structured ingredient/step format tests domain-specific language (7,258 documents).
- Speeches: Presidential Speeches corpus (297 documents); formal, consistent register and style.
For each genre, corpus documents were sampled, sentences selected, and random documents filtered to those with ≥10 sentences to ensure sufficiently long prompts. One of every ten sentences was selected as the first machine-generated sentence; remaining sentences were replaced with model-generated continuations at sampling rate p ∈ {0.0, 0.4, 1.0} (nucleus sampling with temperature 0.96).
Generation:
Text generated using GPT-2 and GPT-2 XL (774M and 1.5B parameters). Also tested CTRL (1.6B parameter model with controllability) on Speeches domain for comparing control-code effects. Fine-tuned GPT-2 XL on recipes (using Recipe1M+ corpus) for domain adaptation analysis.
Analysis:
Measured mean score as the primary metric (correlation r=0.74 with accuracy, more stable than raw accuracy given guessing strategy effects). Collected 42,165 total annotations over 7,895 documents in the main study; final dataset of 21,646 annotations after filtering (removing rogue players exploiting suspiciously-optimal annotation strategies). Inter-annotator agreement measured via Spearman's α (slight but non-zero agreement α=0.25, indicating substantial difficulty).
Results¶
Overall human performance:
- Mean score on complete games: 2.75 (significantly above random baseline of 1.31 ± 0.25, p<0.001).
- Boundary detection accuracy: 23.4% correct on first attempt (vs. 10% random chance); improves to 72.3% when allowing any guess in top 3 sentences.
- Skill variance: Standard deviation of 1.84 across players; top 10% of players achieve >3.5 mean score while bottom quartile performs near random chance.
Group effects:
- Incentives matter: Group B (incentivized) showed improvement over time (ρ=0.42, p<0.001) while Group A (no incentives) showed no significant improvement (ρ=-0.06, n.s.).
- Effort analysis: Group B averaged 6.443 seconds per annotation; Group A 5.651 seconds; Group B players who received extra instruction showed highest performance.
Genre differences:
- Recipes most challenging: Mean score on recipes 1.62 (lowest); generated recipes contain "common-sense" errors (26%) indicating logical contradictions more than other genres.
- News easier: News articles scored 1.88 (near-average); players spotted "generic" language (18%) and "irrelevant" content (18%) at higher rates.
- Genre-specific error types: Stories exhibited more "irrelevant" errors (10%); Speeches more "generic" errors (18%); News more "irrelevant" (18%) plus "generic" (16%).
Model size effects:
- GPT-2 XL harder to detect: When generations come from GPT-2 XL, mean player score significantly lower (p=0.02) compared to GPT-2; effect consistent across all genres except News.
- Decoding strategy matters: Higher p values (more diverse sampling) make text harder to detect. Comparing p=0.0 (argmax, deterministic) vs. p=0.4 (nucleus sampling) shows significant detectability differences on Stories and Recipes.
Time and effort:
Players get faster at the task over time (Figure 7): mean time per annotation drops from ~12 seconds on round 1 to ~2.5–5 seconds by round 100. Despite speed gains, accuracy doesn't significantly degrade, suggesting learning of detection patterns.
Control codes effect (Speeches):
CTRL model with [Politics] and [Presidents] codes allows fine-grained control of generation style. When using control codes for half the generations, human detection ability slightly improves (no significant difference), suggesting control codes don't dramatically improve or harm detectability compared to raw language modeling.
Connections¶
- Related to Ippolito et al. (2019) on human vs. machine detection of generated text, but focuses on boundary detection rather than binary classification.
- Builds on generated-text-detection literature with human-subjects ground truth and multi-genre evaluation.
- Part of broader human-evaluation methodology for NLG and language model safety.
- Relevant to crowdsourcing and game-based annotation design (RoFT game platform).
- Related to Solaiman et al. (2019) on responsible AI and detection of GPT-2 generated text.
- Contributes to understanding detection-methods and human ability to discern machine-generated content across diverse text types.
Notes¶
Strengths: - Novel problem formulation: boundary detection is more realistic and challenging than binary classification, as real-world scenarios often involve partial machine-generated continuations. - Rigorous experimental design with two participant groups (incentivized vs. unincentivized) revealing the importance of motivation for learning detection skills. - Large-scale dataset (21K annotations) with detailed error taxonomy enabling fine-grained analysis. - Multi-genre evaluation demonstrates genre-specific patterns in detectability and error types. - Clear practical implications for understanding when and why humans fail to detect generated text. - Honest about limitations: acknowledges that university student population may not reflect general public; notes that results may not generalize to other language models or GPT-3/GPT-3.5.
Limitations: - Participant pool limited to university students (graduate and advanced undergraduates); likely higher media literacy and English proficiency than general population. - Evaluation limited to GPT-2 and GPT-2 XL; generalization to more recent models (GPT-3, LLaMA, etc.) uncertain. - Boundary detection task still somewhat artificial: real-world misinformation may blend human and machine text more subtly, or humans may not expect transitions. - Game-based interface may not reflect how people naturally evaluate real-world documents; competitive framing and point system could bias results. - No analysis of adversarial generation strategies that might deliberately obfuscate the transition point. - Limited discussion of why certain error types dominate certain genres—opportunity for deeper discourse analysis.
Impact: Introduces a valuable public dataset and game platform for studying human detection of machine-generated text. Reframes the problem in a more realistic direction and provides ground truth for training better detection systems. Finding that humans improve with incentives has implications for crowdsourcing quality control.