Automatic Detection of Generated Text is Easiest when Humans are Fooled¶
Authors: Daphne Ippolito, Daniel Duckworth, Chris Callison-Burch, Douglas Eck
Venue: arXiv:1911.00650 — Link
TL;DR¶
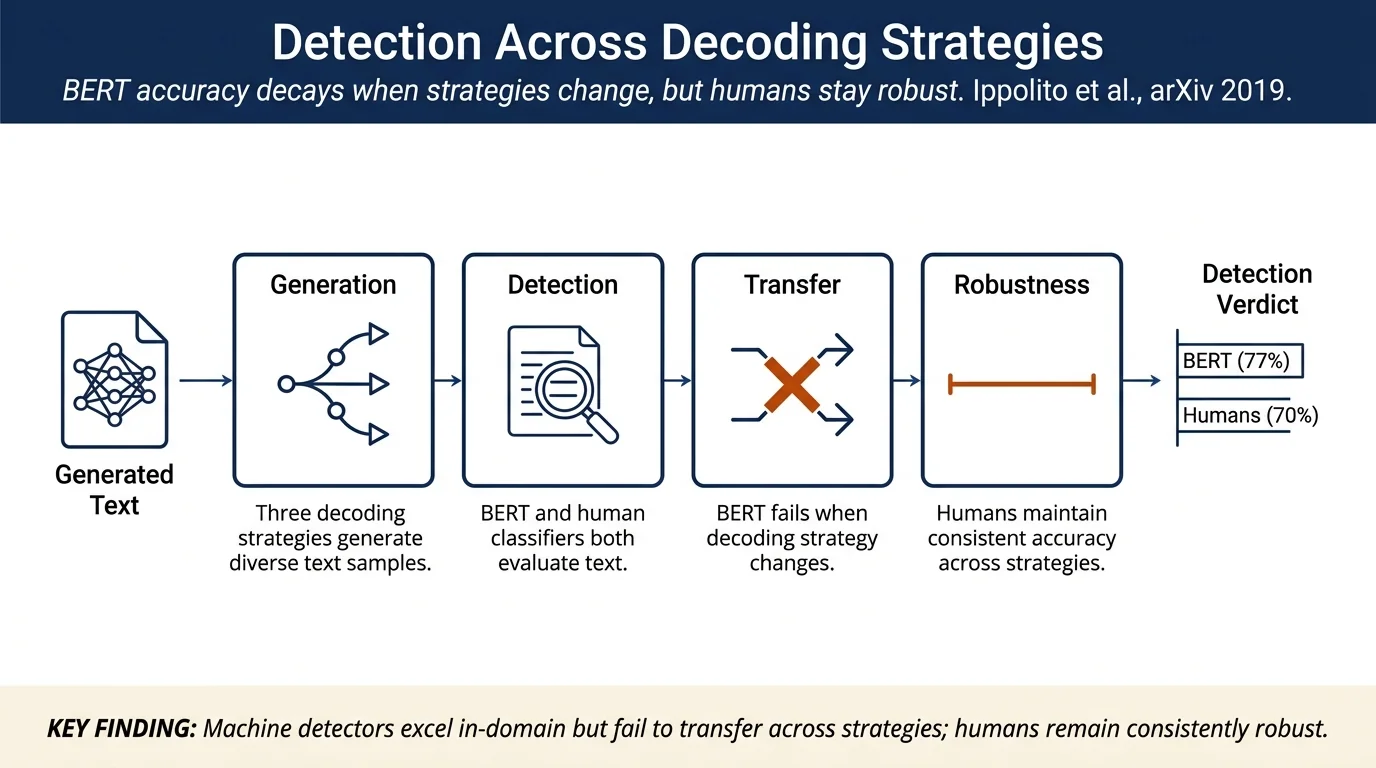
Ippolito et al. investigate the complementary abilities of humans and machines to detect machine-generated text from GPT-2 under various decoding strategies. They find that fine-tuned BERT detectors outperform humans (achieving 80%+ accuracy on long excerpts versus 71% for expert human raters), but detector performance is highly sensitive to the decoding strategy used during generation. Crucially, decoders trained on one strategy (e.g., top-k) transfer poorly to text generated with different strategies (e.g., nucleus sampling), whereas humans maintain relatively consistent detection ability across decoding methods.
Contributions¶
- Comprehensive detection benchmark: Three datasets with balanced machine and human-written examples, each generated using a different decoding strategy (top-k, nucleus sampling, untruncated random sampling) with varied excerpt lengths (2–192 WordPiece tokens) and optionally with priming tokens.
- Systematic analysis of BERT fine-tuning: Fine-tuned BERT-LARGE classifier achieves 88% accuracy on length-192 sequences with untruncated sampling but drops to 56% accuracy when trained on one strategy and tested on another, revealing brittle cross-domain transfer.
- Human evaluation framework: Expert raters (trained on 10 examples) and crowdworkers achieve 71.4% and 50.6% accuracy respectively on length-192 excerpts; humans are substantially more robust across decoding strategies than automatic systems, though less accurate overall.
- Analysis of linguistic properties: Histogram-of-likelihood (GLTR-inspired) and bag-of-words features show that top-k sampling produces text easily distinguishable by humans (concentrated on rare tokens), whereas nucleus sampling creates text more human-like but harder for top-k-trained detectors to identify.
Method¶
Dataset construction:
All machine-generated text samples are drawn from GPT-2-LARGE (774M parameters) trained on Common Crawl. For each of three decoding strategies, 250,000 generated samples are paired with 250,000 human-written excerpts from the Common Crawl corpus. Dataset variations:
- Decoding strategies: (1) Untruncated random sampling (baseline); (2) Top-k with k=40 (Radford et al., 2019); (3) Nucleus (top-p) sampling with p=0.96.
- Excerpt length: All excerpts truncated to 10 possible lengths (2, 4, 8, 16, 32, 64, 128, 192 WordPiece tokens).
- Priming: Two dataset variants—one with no priming, one with minimum priming (a single web-text token serving as the seed).
Automatic detection method:
Fine-tuned BERT-LARGE (cased) on the binary classification task (human vs. machine). Training: 15 epochs with checkpoints every 1,000 steps, batch size 256. Results reported on the test set using the checkpoint with highest validation accuracy on the current length and sampling strategy. Baselines include:
- Bag-of-words logistic regression
- GLTR histogram-of-likelihood features (four bins over the probability distribution)
- Total probability (simpler variant of GLTR)
Human evaluation:
Raters are shown length-16 WordPiece excerpts initially, then length is doubled and the question repeated (up to length-192). Four response options: "definitely human", "possibly human", "possibly machine", "definitely machine". Amazon Mechanical Turk for crowdworkers; expert raters (trained NLP students) for the trained-rater group.
Results¶
Automatic detection:
- Fine-tuned BERT on homogeneous data: Accuracy increases with excerpt length; on longest sequences (192 tokens) and untruncated sampling, achieves 88% accuracy and 99% AUC.
- Robustness across strategies: Discriminators trained on one decoding strategy generalize poorly to others. Training on top-k yields 90.1% accuracy on in-domain test data but only 42.5% on nucleus-sampled text (worse than chance). Training on mixed data improves cross-strategy performance but remains weaker than any single-strategy classifier (74.2% accuracy on nucleus when trained on mixed data).
- Simple baselines outperform complex ones: Logistic regression on bag-of-words features (over 50,000-dimensional embeddings) achieves 52–56% AUC on length-192 sequences. GLTR histogram features (Test 2: top-k buckets) outperform word features (AUC 0.87 vs. 0.63), suggesting distributional properties are the primary signal. When untrained detectors (p1.0, random sampling without priming) are tested on top-k samples, the GLTR approach achieves over 80% accuracy, though detection accuracy degrades on nucleus and untruncated random variants.
Human evaluation:
- Baseline crowdworker accuracy: 50.6% on length-192 excerpts (at chance for binary classification).
- Expert rater accuracy: 71.4% (after 10-example walkthrough), with 95% confidence intervals; accuracy increases with excerpt length, as expected.
- Human robustness: Unlike automatic detectors, expert raters maintain relatively consistent accuracy across decoding strategies. When comparing rater decisions across top-k, nucleus, and untruncated strategies, humans' error distributions remain balanced (roughly equal false positives and false negatives).
- Error analysis: Crowdworkers often mislabel human-written text as machine-generated, especially short excerpts. Experts notice linguistic cues (e.g., repetition of entity names, parallelism in sentence structure) that top-k-sampled text produces due to vocabulary concentration.
| Decoding Strategy | BERT (in-domain) | Human Expert |
|---|---|---|
| Untruncated | 88% (0.99 AUC) | 71.4% |
| Top-k (k=40) | 90.1% (0.94 AUC) | 70.1% |
| Nucleus (p=0.96) | 87.1% (0.94 AUC) | 68.3% |
Transferability challenge: When trained on untruncated sampling, nucleus-sampled text detection drops to 42.5% (worse than random). This asymmetry arises because nucleus sampling approximates the untruncated tail distribution (low-probability words), while top-k enforces high-probability tokens—BERT trained on the latter is fooled by the former.
Connections¶
- Related to GLTR (Gehrmann et al., 2019) on white-box distributional detection; this paper extends GLTR evaluation and identifies its limitation: poor cross-strategy transfer.
- Complements GROVER (Zellers et al., 2019), which focuses on generation quality; this work evaluates detectability of GROVER-style outputs.
- Contrasts with OpenAI's release strategies paper, which frames the detection problem as an AI safety concern; this paper provides empirical data on the difficulty of reliable detection.
- Contributes to human-computer evaluation methodology by showing systematic differences between human and machine detection biases.
- Part of the broader detection-methods literature on synthetic text, sitting between white-box (distributional) and black-box (learned-classifier) approaches.
Notes¶
Strengths: - Comprehensive experimental design across three orthogonal decoding strategies, excerpt lengths, and priming conditions. - Honest about failure modes: the paper openly reports that detector transfer is poor, and humans are more robust—a non-obvious finding that has implications for real-world deployment. - Clear practical implications: detection is feasible when humans can be fooled (longer excerpts, nucleus sampling makes human detection harder) but brittle when humans remain reliable. - Human evaluation with both expert raters and crowdworkers provides nuance on expertise effects.
Limitations: - Evaluation limited to English and GPT-2 outputs. Generalization to other models (BERT-generated, T5, LLaMA) and languages remains unclear. - No analysis of adversarial generation (deliberately designed to evade detectors). Nucleus sampling is closer to human-like text but not deliberately obfuscated. - Excerpt-length effects are interesting but don't directly apply to document-level detection in practice (full papers, news articles are longer and contain more redundancy). - Human rater expertise effect is not fully disentangled from training data (the 10-example walkthrough may have taught raters to exploit GPT-2–specific artifacts).
Impact: This work influenced subsequent research on cross-domain robustness of detection systems and raised awareness that detector training data and generation method are tightly coupled. The finding that humans are more transferable suggests detection systems might benefit from hybrid human-in-the-loop approaches.