Multimodal Emergent Fake News Detection via Meta Neural Process Networks¶
Authors: Yaqing Wang, Fenglong Ma, Haoyu Wang, Kishlay Jha, Jing Gao
Venue: ACM SIGKDD Conference on Knowledge Discovery and Data Mining, August 2021 — DOI
TL;DR¶
Existing fake news detectors trained on labeled data perform poorly on novel, emergent events due to domain shift. The paper proposes MetaFEND, which combines meta-learning and neural processes to leverage a handful of labeled posts from a new event to quickly adapt a detection model. Key innovations include hard attention (to focus on informative posts despite imbalanced class distributions) and label embedding (to treat categorical labels as semantic vectors rather than scalar values).
Contributions¶
- Formulates emergent fake news detection as a few-shot learning problem, recognizing that large-scale labeled datasets are unavailable for breaking news events
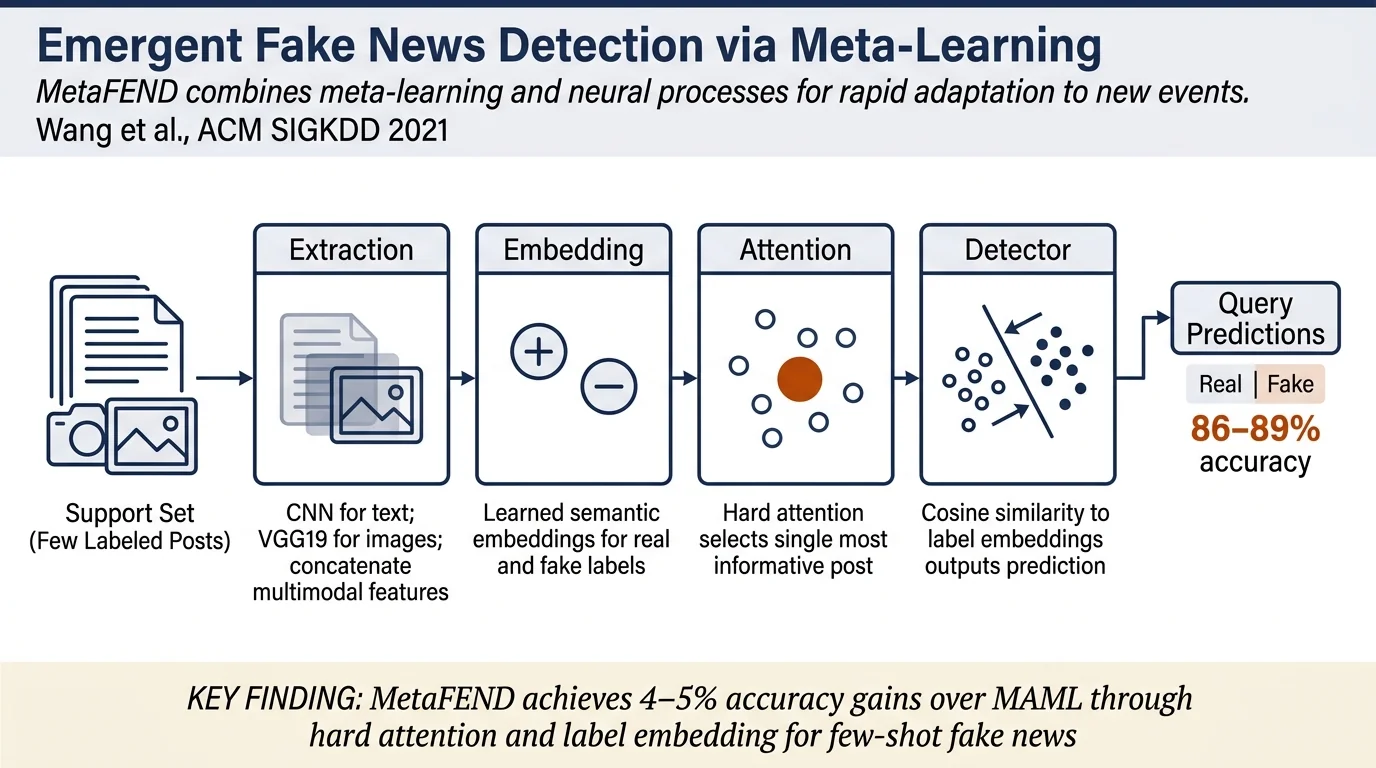
- Proposes MetaFEND, a meta neural process framework unifying meta-learning's parameter adaptation with neural processes' ability to condition on context data, linked via a novel leave-one-out simulation task
- Introduces hard attention mechanism using Straight-Through Gumbel SoftMax to select the single most informative post from an imbalanced support set, replacing standard soft attention
- Proposes label embedding to capture categorical structure of true/false labels, improving generalization across heterogeneous events
- Demonstrates 4-5% accuracy improvements over MAML, ANP, and other baselines on Twitter and Weibo datasets in 5-shot and 10-shot settings
Method¶
Problem setting: Given a new event with K labeled posts (support set), detect fake news on unlabeled posts (query set). Unlike standard classification, events are heterogeneous: news style, vocabulary, and class distributions vary significantly across events.
Meta neural process design: The framework has two stages executed with the same architecture:
-
Event adaptation: Simulate a learning task by treating each support post i as a target and the remaining posts as context. Minimize loss on this leave-one-out prediction to adapt parameters θ → θ_e via gradient descent. This bridges meta-learning (parameter update) and neural processes (explicit conditioning).
-
Detection: Use the adapted parameters θ_e to make predictions on the query set, conditioned on the full support set.
Architecture:
- Feature extractor: CNN for text (with FastText embeddings), frozen VGG19 for images, concatenated as d-dimensional features
- Label embedding: Fixed embeddings vec(fake) and vec(real) capture semantic meaning of labels, treating them as categorical rather than scalar
- Aggregator: Uses scaled dot-product attention over context features with hard attention variant
- Soft attention: Standard softmax over support posts; treats all posts equally when class-imbalanced
- Hard attention (novel): Samples a single post k using Straight-Through Gumbel SoftMax, creating a discrete, differentiable argmax that selects the most similar support post
- Detector: Fully connected layer outputting d-dimensional vector; predictions computed as cosine similarity to label embeddings
Results¶
Datasets: MediaEval Twitter dataset (6,934 fake / 5,683 real news) and Weibo dataset (4,050 fake / 3,558 real news), split to ensure no event overlap between train and test.
Baselines: Multi-modal models (VQA, att-RNN, EANN fine-tuned on support set) and few-shot methods (CNP, ANP, MAML, Meta-SGD).
Performance:
| Setting | Twitter Accuracy | Twitter F1 | Weibo Accuracy | Weibo F1 |
|---|---|---|---|---|
| 5-shot | 86.45% (+5.12% vs MAML) | 86.21% | 81.28% (+4.41%) | 80.19% |
| 10-shot | 88.79% (+4.19% vs MAML) | 88.66% | 82.92% (+5.22%) | 82.37% |
MetaFEND outperforms all baselines, with larger gains in 10-shot setting where soft attention's limitation becomes more pronounced.
Ablation study:
- Hard attention vs. soft attention: Hard attention improves accuracy, with advantage increasing as support set grows
- Label embedding vs. label values: Label embedding consistently improves accuracy in both 5- and 10-shot settings
Connections¶
- Related to EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection through shared multimodal feature extraction (text + image) and event-specific learning, but MetaFEND exploits few-shot adaptation rather than event-adversarial training
- Related to Fake news detection methods as a deep learning approach to fake news classification
- Related to Meta-learning and Few-Shot Learning as methodological foundations
- Related to MVAE: Multimodal Variational Autoencoder for Fake News Detection in multimodal fusion but uses attention-based aggregation rather than VAE
- Related to Emergent events as the key application domain for rapid adaptation
Notes¶
Strengths:
- Well-motivated problem: emergent events are practically important and existing approaches fail due to domain shift
- Novel integration of meta-learning and neural processes via leave-one-out simulation is elegant and principled
- Hard attention mechanism is a clear improvement over soft attention, especially with imbalanced data; case study (Fig. 5) effectively illustrates the problem
- Label embedding treating labels as categorical is a simple but effective insight
- Strong empirical results on two datasets with diverse characteristics (Twitter: text-heavy; Weibo: image-heavy)
Weaknesses:
- The improvement over MAML, while consistent, is modest (4-5%). The hard attention and label embedding contributions are somewhat incremental
- Limited to binary classification (real/fake). Real-world misinformation is often more nuanced (satire, misleading, out-of-context, etc.)
- Evaluation limited to two platforms (Twitter, Weibo). Generalization to other social media or news domains unclear
- No discussion of computational cost or inference time compared to baselines
- The leave-one-out simulation task, while novel, lacks theoretical justification for why this particular design bridges the two frameworks
Follow-ups:
- Extension to multiclass misinformation categorization
- Investigation of transfer across platforms and languages
- Theoretical analysis of the leave-one-out design in the context of risk minimization