FakeBERT: Fake News Detection in Social Media with a BERT-based Deep Learning Approach¶
Authors: Rohit Kumar Kaliyar, Anurag Goswami, Pratik Narang Venue: Multimedia Tools and Applications, Vol. 80, pp. 11765–11788, 2021 DOI: 10.1007/s11042-020-10183-2
TL;DR¶
FakeBERT combines BERT (Bidirectional Encoder Representations from Transformers) with parallel 1D convolutional neural networks to detect fake news on social media. The model captures semantic and long-distance dependencies in text, achieving 98.90% accuracy on the real-world fake news dataset and substantially outperforming CNN and LSTM baselines using traditional embeddings (92.70% and 97.55% respectively).
Contributions¶
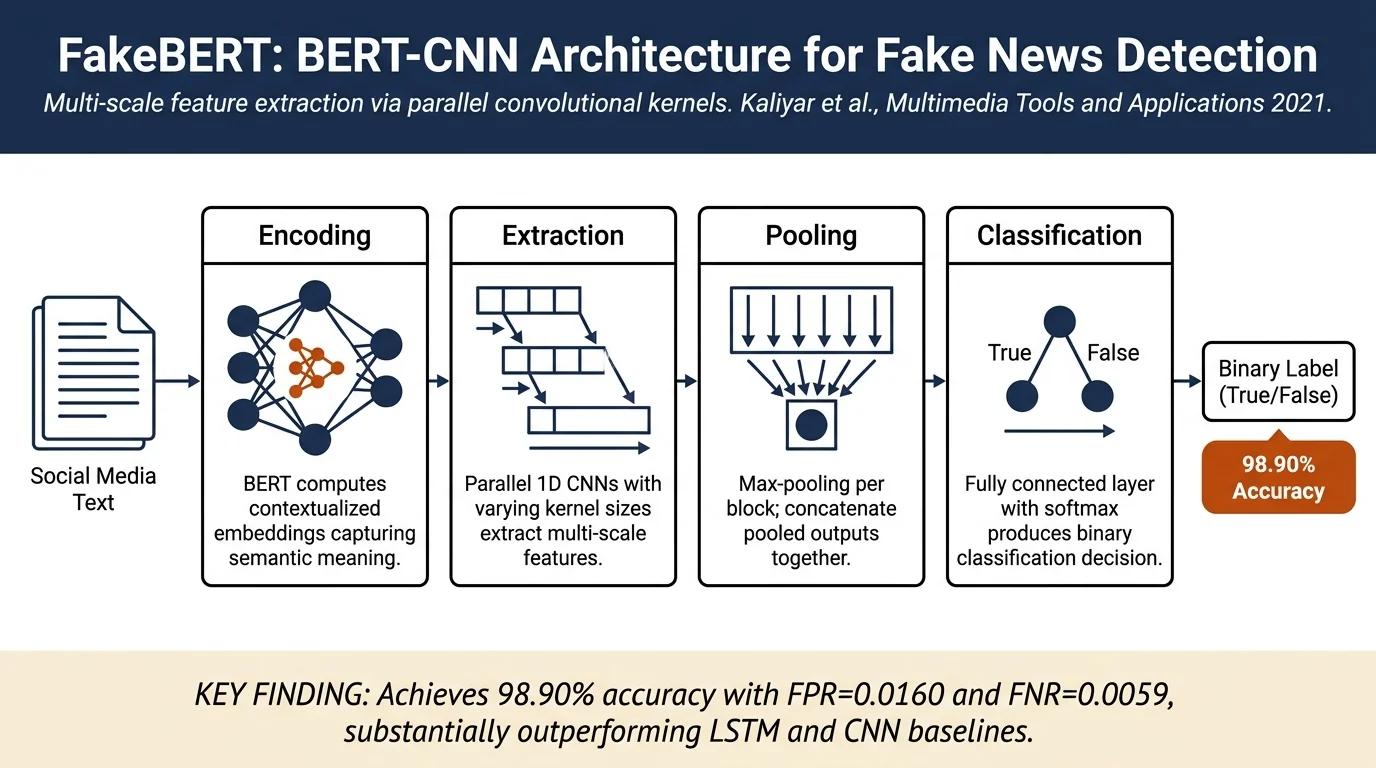
- BERT-CNN architecture: Combines BERT text encoders with parallel blocks of single-layer 1D convolutions with varying kernel sizes, enabling multi-scale feature extraction while leveraging pre-trained contextualized embeddings
- Bidirectional training approach: Proposes bidirectional training to handle ambiguity in fake news and better capture context
- Empirical evaluation: Comprehensive comparison against machine learning baselines (Multinomial Naïve Bayes, Decision Trees, Random Forests, KNN) and deep learning approaches (CNNs, LSTMs), showing BERT-based embeddings provide substantial improvements
- Performance metrics: Achieves 98.90% accuracy with low false positive (FPR = 0.0160) and false negative (FNR = 0.0059) rates on the real-world fake news dataset
Method¶
The FakeBERT model combines BERT with parallel 1D convolutional architecture:
Encoding: Input text is tokenized and passed through BERT (Bidirectional Encoder Representations from Transformers) as a sentence encoder. BERT computes contextualized embeddings capturing semantic meaning and long-range dependencies.
Feature extraction: The BERT output is multiplied by an embedding matrix and fed to three parallel blocks of single-layer 1D convolutional neural networks. Each block uses different kernel sizes (n-grams) and filters. The multiple kernel sizes enable capture of features at different scales.
Pooling and classification: Max-pooling is applied across each convolutional block, and the outputs are concatenated. A fully connected layer with softmax produces the final binary classification (true/false).
Training: The model uses cross-entropy loss and is trained with different CNN topologies and filter sizes. Bidirectional training involves processing text in both directions to handle writing style ambiguities in fake news.
Results¶
Classification performance on real-world fake news dataset (20,800 instances, 10,540 true, 10,260 false):
- FakeBERT accuracy: 98.90% with FPR = 0.0160, FNR = 0.0059
- CNN with BERT embeddings: 92.70%
- LSTM with BERT embeddings: 97.55%
- LSTM with GloVe embeddings: 97.25%
- CNN with GloVe embeddings: 91.50%
Comparison to prior work: - Ghanemi et al (2013): 48.80% - Singh et al: 87.00% - Ahmed et al (LR-unigram): 89.00% - Ruchansky et al: 89.20% - Ahmed et al (LSVM): 92.00% - Liu et al: 92.10% - O'Brien et al: 93.50%
Deep learning progression: CNN baseline without BERT (92.70%) → LSTM with GloVe (97.25%) → LSTM with BERT (97.55%) → FakeBERT (98.90%), demonstrating the cumulative benefit of contextual embeddings and multi-scale CNN feature extraction.
Connections¶
- Related to DEAP-FAKED which combines knowledge graphs with deep learning for fake news detection
- Shares architectural ideas with HERO: Hierarchical Relation-aware Linguistic Style using neural encoders for style-based detection
- Part of broader deep learning trend in Fake news detection moving away from hand-crafted linguistic features toward contextual embeddings
Notes¶
Strengths: - High accuracy (98.90%) on a real-world dataset from 2016 U.S. Presidential Election—practical relevance to political misinformation - Comprehensive experimental comparison across multiple baseline architectures (traditional ML, CNN, LSTM, BERT variants) - Detailed ablation analysis showing contribution of BERT embeddings vs. GloVe and benefit of bidirectional training - Clear methodology with well-defined hyperparameters and reproducible experimental setup - FPR and FNR metrics beyond accuracy showing balance in classification performance
Weaknesses: - Limited to English social media text; generalization to other languages or domains (health misinformation, scientific claims) unclear - No human evaluation of model interpretability or failure case analysis - Evaluation limited to binary true/false classification; fine-grained labels (satire, parody, propaganda) not explored - Computational cost comparison with simpler BERT-only baseline not discussed; added complexity of CNN layers may not be necessary - No analysis of temporal robustness—performance on newer fake news after model training unclear