KAN: Knowledge-aware Attention Network for Fake News Detection¶
Authors: Yaqian Dun, Kefei Tu, Chen Chen, Chunyan Hou, Xiaojie Yuan
Affiliations: College of Computer Science, Nankai University; Tianjin Key Laboratory of Network and Data Security Technology; School of Computer Science and Engineering, Tianjin University of Technology
Venue: The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), 2021
TL;DR¶
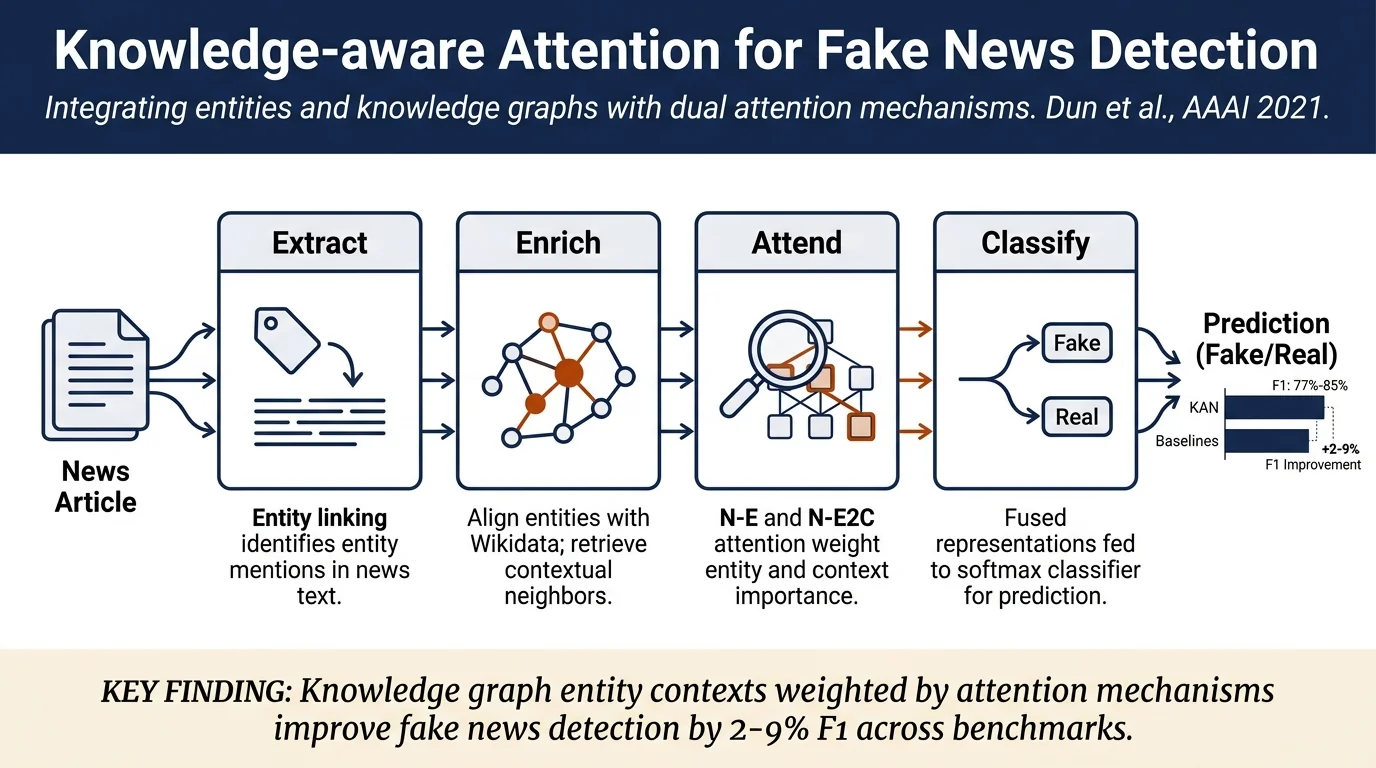
Most fake news detection models rely on textual features and social context but ignore knowledge-level relationships among entities in news. This paper proposes KAN, which extracts entity mentions from news, aligns them with knowledge graphs (Wikidata), and uses two attention mechanisms (N-E and N-E2C) to measure entity and entity-context importance. KAN achieves 7.4% F1 improvement over prior methods on PolitiFact, 2.8% on GossipCop, and 9.7% on PHEME.
Contributions¶
- Incorporates entities and their entity contexts (neighbors in knowledge graphs) as external knowledge for fake news detection—addressing the limitation that existing methods ignore knowledge-level entity relationships.
- Proposes Knowledge-aware Attention Network with two attention mechanisms:
- N-E attention: Measures semantic similarity between news content and entities to assign importance weights.
- N-E2C attention: Assigns importance weights to entity contexts based on the vitality of their corresponding entities.
- Demonstrates through ablation studies that both knowledge components and attention mechanisms are critical to detection performance.
Method¶
Knowledge Extraction: Uses entity linking (TagMe tool) to identify entity mentions in news and align them with Wikidata. For each linked entity, extracts its immediate neighbors (one-hop distance) as entity context.
Architecture: - Text Encoder: Transformer encoder with positional encoding to generate news representation p. - Knowledge Encoder: Separate transformer encoders for entity embeddings (from word2vec) and entity context embeddings to produce intermediate encodings q' and r'. - Attention Mechanisms: - N-E attention computes attention weights α between news and entities to produce weighted entity representation q. - N-E2C attention uses news and entity representations to weight entity contexts and produce representation r. - Classifier: Concatenates p, q, and r, feeds into a fully-connected layer with softmax and L2 regularization.
Results¶
Experiments on three benchmark datasets:
| Dataset | Metric | KAN | KCNN | B-TransE | GRU-2 |
|---|---|---|---|---|---|
| PolitiFact | F1 | 0.8539 | 0.7804 | 0.7641 | 0.7041 |
| PolitiFact | Accuracy | 0.8586 | 0.7827 | 0.7694 | 0.7109 |
| GossipCop | F1 | 0.7713 | 0.7433 | 0.7340 | 0.7079 |
| GossipCop | Accuracy | 0.7766 | 0.7491 | 0.7394 | 0.7180 |
| PHEME | F1 | 0.7461 | 0.6489 | 0.6074 | 0.6917 |
| PHEME | Accuracy | 0.7830 | 0.7265 | 0.7200 | 0.7371 |
Ablations reveal: - Removing entity contexts (KAN\EC) degrades performance, confirming their value. - Removing entities entirely (KAN\E) shows entities are crucial for disambiguation. - Removing all external knowledge (KAN\EC\E) reduces F1 by 2.2% on PolitiFact, 1.2% on GossipCop, and 1.3% on PHEME. - N-E and N-E2C attention mechanisms improve performance by 2.2% accuracy on PolitiFact and 6.2% on GossipCop when used together.
Connections¶
- Related to Knowledge graphs for entity linking and context extraction.
- Builds on Content-based fake news detection by enriching news representations with external knowledge.
- Uses attention mechanisms similar to those in Multimodal fake news detection for feature fusion.
- Contrasts with Propagation-based fake news detection which focuses on social context rather than knowledge graphs.
- Comparable to EANN (Wang et al. 2018) in using attention for multi-modal fusion, but operates on knowledge rather than image-text pairs.
- Extends the knowledge graph application in DEAP-FAKED by incorporating both entities and their contexts with attention weighting.
Notes¶
Strengths: - Novel and well-motivated use of entity contexts from knowledge graphs—entities rarely appear in isolation; their neighbors provide disambiguating context. - Thorough ablation studies demonstrate each component contributes meaningfully. - Strong empirical results across three diverse datasets (politics, entertainment, Twitter events). - Clear architectural design with interpretable attention weights.
Limitations: - Entity linking quality depends on the TagMe tool; errors propagate downstream. The paper does not report linking accuracy or analyze failure modes. - Knowledge graph coverage bias not discussed—rare entities may have sparse contexts or be absent from Wikidata. - Comparison to other knowledge-aware methods (e.g., B-TransE) is included, but limited discussion of why KAN's attention design outperforms them. - The entity context representation uses simple averaging of neighbor embeddings; richer encoding of multi-hop paths or relation types might improve performance. - Evaluation limited to supervised settings; generalization to out-of-domain news without retraining is unclear.