Cross-lingual COVID-19 Fake News Detection¶
Authors: Jiangshu Du, Yingtong Dou, Congying Xia, Limeng Cui, Jing Ma, Philip S. Yu
Venue: arXiv preprint, October 2021 — arXiv:2110.06495
TL;DR¶
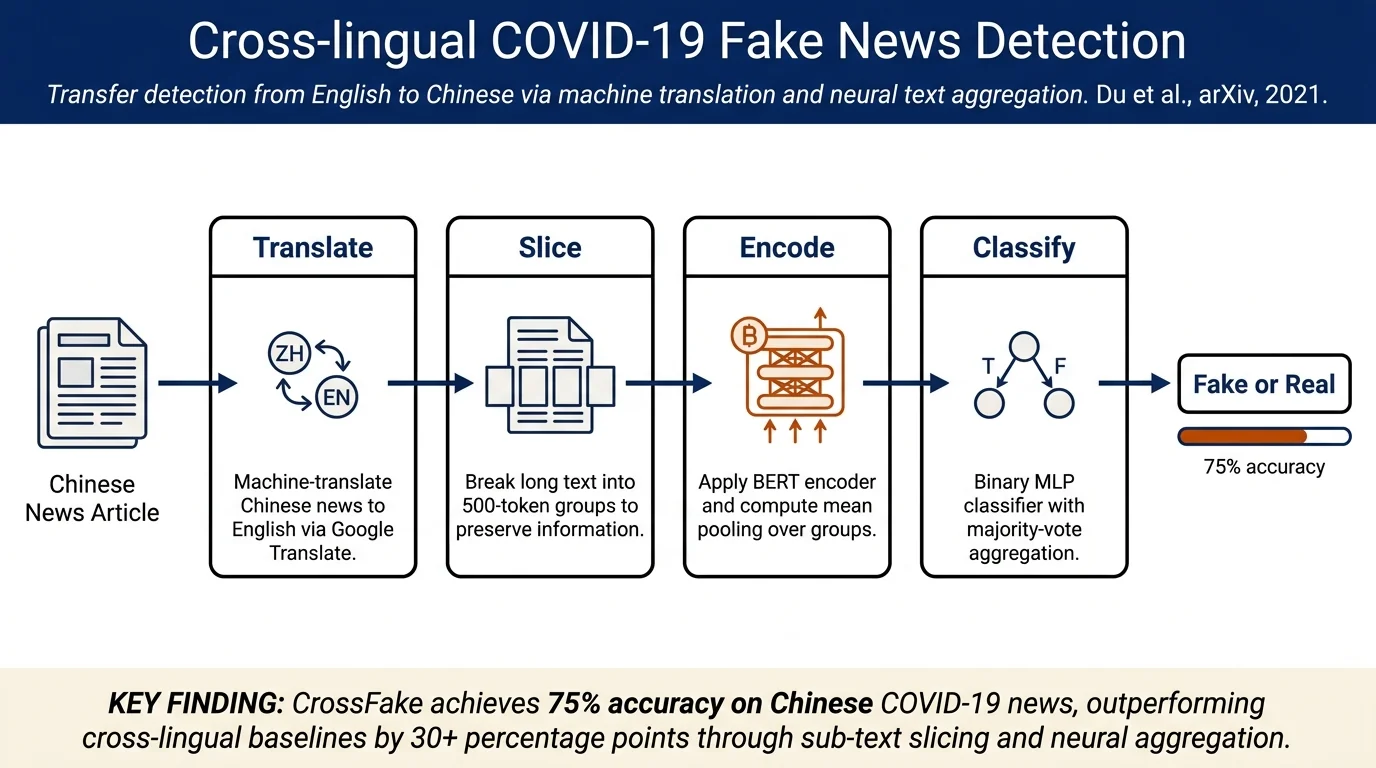
The paper addresses COVID-19 misinformation in low-resource languages by proposing CrossFake, a cross-lingual fake news detector trained on English COVID-19 news and applied to Chinese news via machine translation. The method slices long news texts into sub-text groups before BERT encoding to preserve fact-related information. On a manually annotated Chinese COVID-19 dataset (86 fake, 114 real), CrossFake achieves 75% accuracy, significantly outperforming monolingual and cross-lingual baselines, though machine translation quality remains a limiting factor.
Contributions¶
- Cross-lingual COVID-19 dataset: Manually annotated Chinese COVID-19 news dataset (200 articles: 86 fake, 114 real) matched with existing English COVID-19 datasets, addressing the gap in fact-checked non-English pandemic misinformation
- CrossFake framework: End-to-end neural architecture handling long news texts via sub-text slicing (500 tokens per group), mean pooling, and fully-connected aggregation before binary classification
- Empirical validation: Demonstrates that machine-translated Chinese news can be effectively classified using English-trained detectors, with 75% accuracy significantly exceeding text-only (71.6%) and social-context-based baselines (CSI 68.3%)
- Cross-lingual analysis: Identifies translation quality and information location as bottlenecks; shows pre-trained multilingual encoders (mBERT, multilingual transformers) underperform due to lack of domain knowledge for emerging COVID-19 terminology
- Comparative benchmarking: Evaluates against five monolingual (CSI, SAFE, exBAKE) and two cross-lingual baselines (CLEF, EMET), establishing new performance standards for COVID-19 cross-lingual detection
Method¶
Problem Definition: Train a binary classifier on English COVID-19 news (source language) to predict truthfulness of Chinese COVID-19 news (target language) without annotated Chinese training data.
Training Phase:
Text preprocessing: Break tokenized news body text into groups of 500 tokens sequentially: $\(T_e^G = \{t_{e1}, \ldots, t_{em}\}\)$ where \(m = \lceil |T_e| / 500 \rceil\)
Encoding: Apply BERT to each sub-text group independently: $\(h_e = \text{FC}\left(\frac{\sum_{i=1}^{m} \text{BERT}(t_{ei})}{m}\right)\)$ where FC is a fully-connected layer and mean pooling aggregates embeddings across all sub-texts.
Loss: Binary cross-entropy with sigmoid activation and SGD optimization: $\(L = \sum_{e \in N_e} -\log(y_e \cdot \text{ReLU}(\text{MLP}(h_e)))\)$
Testing Phase:
- Translate Chinese news to English via Google Translate API
- Tokenize and slice into groups of 100 tokens (shorter than English articles)
- Apply the trained classifier to each sub-text
- Aggregate predictions via majority voting with threshold θ = 0.8: $\(p_c = \begin{cases} 1, & \text{if} \frac{\sum_j |C(t_{cj})|}{n} \geq \theta \\ 0, & \text{otherwise} \end{cases}\)$
Results¶
Performance comparison (Table II)¶
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| CLEF (cross-lingual) | 43.1% | 42.9% | 97.4% | 59.5% |
| EMET (cross-lingual) | 45.9% | 42.2% | 70.9% | 51.9% |
| CSI (monolingual, LSTM) | 68.3% | 61.4% | 71.2% | 65.8% |
| SAFE (monolingual, TextCNN) | 71.6% | 63.7% | 80.7% | 71.0% |
| exBAKE (monolingual, BERT) | 64.3% | 55.6% | 92.1% | 69.0% |
| exBAKE-sub (BERT + sub-text) | 66.8% | 59.7% | 70.5% | 64.3% |
| CrossFake-avg | 73.6% | 64.8% | 85.4% | 73.5% |
| CrossFake-sub | 75.0% | 71.5% | 70.5% | 70.7% |
Key findings: 1. CrossFake outperforms baselines: 75% accuracy (CrossFake-sub) beats CNN-based SAFE (71.6%) and all cross-lingual baselines (43–46%) 2. Sub-text aggregation helps: Preserving full article information (CrossFake-avg 73.6%) beats truncating to 512 tokens (exBAKE 64.3%); aggregating predictions further improves precision (71.5%) 3. Cross-lingual models fail: CLEF and EMET achieve only 43–46% accuracy despite using multilingual encoders; high recall (97%, 71%) but poor precision, suggesting overfitting to "fake" predictions 4. CNN outperforms RNN: SAFE (TextCNN, 71.6%) substantially outperforms CSI (LSTM, 68.3%), suggesting local feature extraction is more effective than sequential modeling for long news articles
Analysis of failure modes¶
- Translation quality: "Coronavirus" mistranslated as "new crown virus" (literal Chinese translation), confusing the classifier
- Information location: Fake news with misinformation in middle/end of article are missed by models with fixed sequence length limits
- Dataset size: 200-article test set is small compared to typical benchmarks; results may not generalize
Connections¶
- ReCOVery (Zhou et al., 2020) — English multimodal COVID-19 dataset used as source for training; CrossFake extends to cross-lingual setting
- MM-COVID (Li et al., 2020) — broader six-language COVID-19 dataset with social context; proposes dEFEND social-aware method vs. CrossFake's translation-based approach
- CHECKED (Yang et al., 2020) — Chinese COVID-19 microblogs; CrossFake builds on similar motivation of addressing Chinese misinformation
- Cross-lingual detection and transfer learning — demonstrates practical cross-lingual transfer via translation and domain-specific tokenization strategies
- COVID-19 misinformation — pandemic infodemic research; identifies language-based gaps in fact-checking
- Transfer learning for NLP — shows BERT-based transfer learning to low-resource languages via machine translation
Notes¶
Strengths: - Addresses a genuine and timely problem: non-English COVID-19 misinformation circulating unmoderated while English fact-checking dominates - Practical approach: leverages existing English datasets and off-the-shelf translation rather than assuming annotated Chinese training data - Sub-text slicing strategy is simple and effective, preserving information across long documents that exceed BERT's 512-token limit - Systematic comparison across monolingual and cross-lingual baselines clarifies why multilingual models underperform (lack of domain knowledge, sequence length constraints)
Weaknesses and limitations: - Machine translation bottleneck: Translation quality directly impacts accuracy; mistranslations of domain-specific terms (COVID-19, vaccine, hydroxychloroquine) create fundamental error ceiling - Small test set: 200 articles (86 fake, 114 real) is small relative to other fake news benchmarks; confidence intervals/multiple runs would strengthen claims - Dataset curation methodology: Manual matching of English news to Chinese news introduces selection bias; Chinese sources matching English stories may overrepresent duplicated/widely-spread misinformation rather than indigenous Chinese misinformation - No social context: Unlike MM-COVID, CrossFake relies on text only; propagation patterns and user engagement likely carry additional signal for COVID-19 detection - Limited language scope: Only English→Chinese; claims about low-resource languages generalize from single language pair - Evaluation metric concerns: F1 averaging (macro vs. micro) unclear; precision/recall imbalance (73.6% vs. 85.4%) suggests class imbalance effects not controlled for
Impact and open questions: - Demonstrates feasibility of cross-lingual transfer for emerging-event detection without in-language annotations - Raises question: Can detection improve by addressing translation directly (better translation models, terminology dictionaries) rather than accepting translation as fixed input? - Opens avenue for multi-hop transfer: English → intermediate-resource language (Spanish) → low-resource language
Related datasets: ReCOVery (Zhou et al., 2020), MM-COVID (Li et al., 2020), CHECKED (Yang et al., 2020)