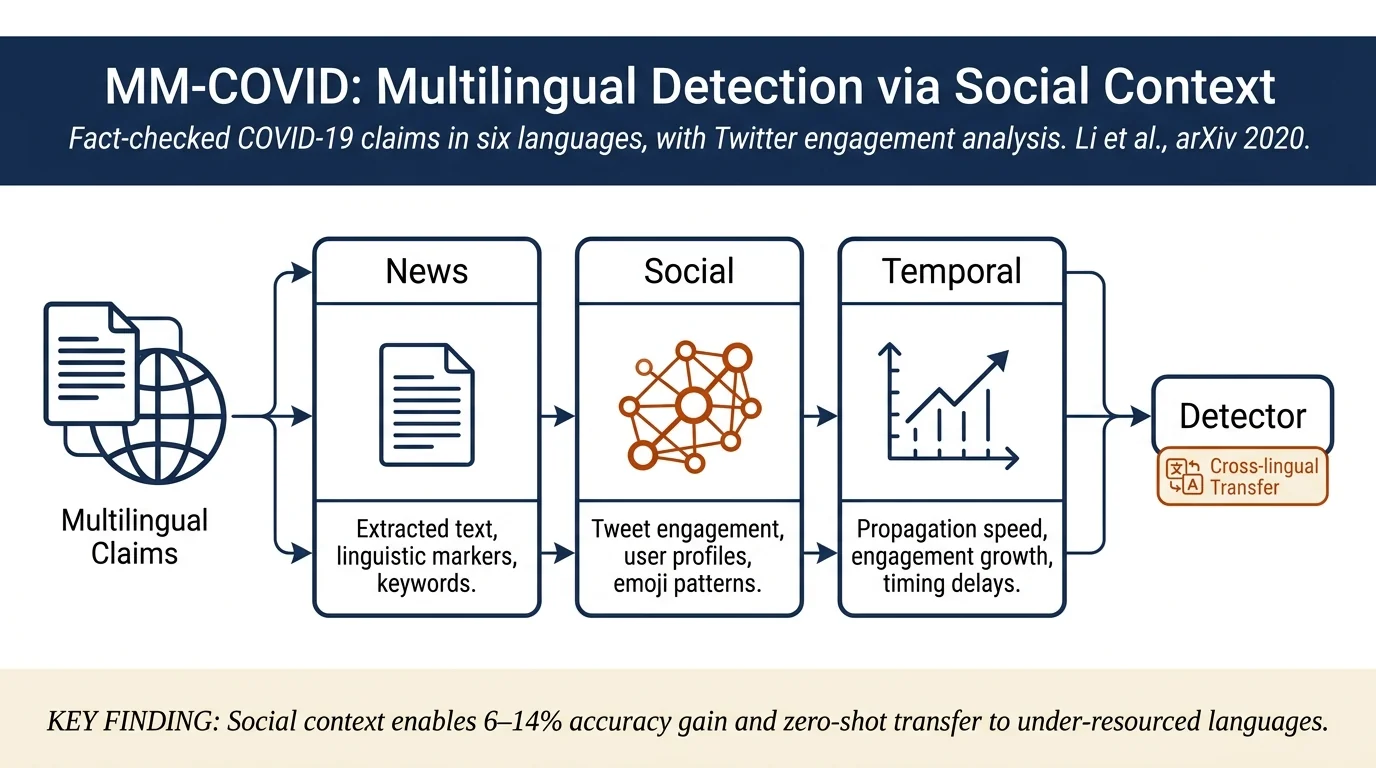
MM-COVID: A Multilingual and Multimodal Data Repository for Combating COVID-19 Disinformation¶
Authors: Yichuan Li, Bohan Jiang, Kai Shu, Huan Liu
Venue: arXiv preprint, November 2020 — arXiv:2011.04088
TL;DR¶
The paper introduces MM-COVID, a multilingual and multimodal dataset of COVID-19 fake news and social engagements in six languages (English, Spanish, Portuguese, Hindi, French, Italian). The dataset includes 3,981 fake news pieces with 7,192 tweets, fact-checking metadata, user profiles, and temporal propagation information. Baseline experiments show that social context features enable effective cross-lingual transfer, allowing detection models trained on English to generalize to under-resourced languages.
Contributions¶
- Multilingual COVID-19 dataset: First large-scale parallel fake news dataset covering six languages with both news content and Twitter social context, addressing the gap between monolingual (English) and non-English datasets
- Multimodal feature engineering: Comprehensive feature extraction across news content (text, linguistic patterns), social engagement (tweets, replies, retweets, user profiles), and temporal propagation
- Cross-lingual analysis: Empirical characterization of language-invariant and language-specific misinformation patterns, revealing that social context provides language-invariant signals for detection
- Benchmark evaluation: Three experimental scenarios (enough resource, low resource, no resource) demonstrating social context utility under data scarcity and cross-lingual transfer
- Practical applications: Insights into early detection, fact-checking prioritization, and mitigation strategy design
Method¶
The paper follows a dataset-centric approach rather than proposing a novel detection method. The methodological contribution lies in data collection, feature engineering, and analysis:
Data Collection Pipeline: 1. Source fact-checked COVID-19 claims from PolitiFact, Snopes, and Poynter covering six languages 2. Query Twitter with extracted URLs and keywords to retrieve related tweets 3. Collect associated user profiles, replies, retweets, and temporal metadata via Twitter API 4. Retrieve archived source content when original URLs become inaccessible
Feature Engineering:
News content features: - Fact-checking labels and debunked explanations - URL, language, location, release date - Text content and extracted images - Linguistic signals (word frequency, medical keywords like "doctor," "hospital," "vaccine")
Social engagement features: - Tweets: text, creation time, retweet/reply/like counts - User profiles: followers, friends, account age, follower-friend ratio (bot likelihood) - Tweet sentiment: emoji distribution and emotional language - Network structure: reply cascades, retweet trees, propagation depth
Temporal features: - Timeline of tweet emergence and engagement growth - Language-specific propagation patterns - Delay between fake news emergence and fact-checking
Baseline Methods Evaluated:
Content-only approaches: - SVM, XGBoost with bag-of-words features - dEFEND'C: sentence-level LSTM with content attention
Social context approaches: - dEFEND'N: incorporates user reply sequences to predict veracity - dEFEND: combines content and social attention mechanisms
Combined approach: - dEFEND: hierarchical attention jointly encoding news sentences and user comments
Results¶
Overall performance (enough resource: 80% training data)¶
| Method | en | es | pt | hi | fr | it | Avg |
|---|---|---|---|---|---|---|---|
| SVM | 0.74 | 0.87 | 0.72 | 0.72 | 0.79 | 0.78 | 0.77 |
| XGBoost | 0.75 | 0.89 | 0.73 | 0.72 | 0.81 | 0.8 | 0.78 |
| dEFEND'C (text only) | 0.77 | 0.91 | 0.86 | 0.95 | 0.82 | 0.83 | 0.86 |
| dEFEND'N (social only) | 0.82 | 0.93 | 0.84 | 0.91 | 0.91 | 0.91 | 0.87 |
| dEFEND (combined) | 0.91 | 0.95 | 0.96 | 0.96 | 0.91 | 0.92 | 0.93 |
Key finding: Social context provides 6–14% accuracy improvement over text-only baselines (dEFEND'C: 0.86 → dEFEND: 0.93). Improvement is consistent across all languages.
Low-resource scenario (20% training data)¶
dEFEND maintains 0.76–0.90 accuracy, showing graceful degradation. Social engagement signals remain beneficial when labeled data is scarce, suggesting user behavior is more stable than language-specific text patterns.
Zero-resource scenario (cross-lingual transfer)¶
Training on English and testing on other languages: - Within-language (80% training): 0.91–0.96 accuracy - Cross-lingual from English: 0.41–0.85 accuracy (variable by target language) - Multilingual training (all languages + 20% per language): 0.82–0.92 accuracy (near full-resource performance)
Social context features enable transfer: dEFEND'N achieves 0.85 macro F₁ in no-resource Portuguese even though it was trained only on English replies.
Language-invariant patterns¶
Emoji and emotional language prove language-invariant: fake tweets show laughing, angry, and shocked emojis consistently across all six languages, with 29–38% higher emoji density than real news tweets.
Language-specific findings¶
- Engagement patterns: English and Italian fake news attract bots more frequently; Portuguese and Hindi fake news show lower bot-likelihood ratios despite language-invariant emoji patterns
- Propagation speed: English fake news spike early; Hindi fake news accumulate engagement more gradually
- Topic variation: English emphasizes conspiracy theories (#vaccine, #hydroxychloroquine); Spanish focuses on economic impacts; Portuguese stresses health authority credibility loss
Connections¶
- ReCOVery (Zhou et al., 2020) is the closest English-only multimodal COVID-19 credibility dataset; MM-COVID extends this to six languages
- HERO (Zhou et al., 2023) benchmarks linguistic-style detection on MM-COVID, achieving 0.896 AUC via hierarchical discourse parsing
- dEFEND (Shu et al., 2019) provides the core detection methodology; this paper adapts dEFEND to multilingual settings
- Multimodal fake news detection — demonstrates value of combining text, image, and social signals
- COVID-19 misinformation — foundational dataset for pandemic-focused detection
- Cross-lingual detection and transfer learning — shows social context enables transfer to low-resource languages
Notes¶
Strengths: - Addresses a genuine gap: only monolingual English multimodal COVID-19 datasets existed at the time (ReCOVery) - Comprehensive feature engineering demonstrates multiple signal types (content, social, temporal) across languages - Practical scenarios (enough/low/no resource) reflect real-world deployment constraints - Language-specific findings (bot likelihood, topic variation, propagation speed) suggest that multilingual detection is not trivial; single-language models may not transfer naively
Weaknesses and limitations: - Fact-checking source bias: most fact-checks originated in English-majority agencies (PolitiFact, Snopes), introducing bias in what gets labeled as "fake" and potentially disadvantaging detection in less-checked languages - Limited temporal scope: data collection focused on early COVID-19 (March–May 2020); later phases (vaccination era, endemic transition) underrepresented; misinformation patterns may have shifted - Real news baseline: real news tweets are assumed accurate if posted from official health accounts, without explicit fact-checking; some real news may actually contain errors - Only six languages: excludes Mandarin Chinese, Russian, Japanese, and other high-disinformation regions; the choice of six languages appears driven by fact-checking availability rather than misinformation impact - Dataset is no longer updated: as of 2020, the dataset captured the pandemic's early phase; ongoing COVID-19 misinformation (e.g., vaccine hesitancy 2021–2023) requires separate collection - Evaluation is limited to dEFEND variants; other multilingual models (e.g., XLM-RoBERTa, mBERT) are not benchmarked, limiting generalizability claims
Impact and follow-up work: - The dataset has been used in subsequent multilingual misinformation research (e.g., HERO) - Demonstrates that early detection (within first few hours of tweeting) is feasible with social engagement patterns, a finding applicable to real-time content moderation systems - Opens research questions: How do language-invariant patterns (emoji, user behavior) scale beyond six languages? Can detection models trained on English truly generalize to under-resourced languages, or does domain adaptation remain necessary?
Related datasets: MM-COVID (dataset page), ReCOVery, CHECKED, FakeNewsNet