Where Are the Facts? Searching for Fact-checked Information to Alleviate the Spread of Fake News¶
Authors: Nguyen Vo, Kyumin Lee
Venue: arXiv, October 2020 — arXiv:2010.03159
TL;DR¶
Proposes a framework to automatically find fact-checking articles that address claims in original tweets. Uses a multimodal attention network (MAN) combining textual and visual content from tweets with fact-checking article text to rank candidate fact-checks; demonstrates that multimodal retrieval substantially outperforms text-only baselines and can warn users about fact-checked misinformation.
Contributions¶
- First study to search for fact-checking articles to increase users' awareness of fact-checked information when exposed to fake news
- Novel multimodal attention network (MAN) combining textual and visual matching signals with an attention mechanism that focuses on key word interactions
- Experimental validation on Snopes and PolitiFact datasets showing effectiveness and generalizability of the retrieval approach
Method¶
The framework addresses two challenges: (P1) how to extract useful information from original tweets (including images) to find relevant FC-articles, and (P2) how to design a retrieval system to find and rank FC-articles.
Input Representations. Original tweets are represented as pairs of text and images; fact-checking articles contain only text. Both are converted to vector representations via projection layers.
Basic Retrieval. Uses BM25 to retrieve initial candidate fact-checking articles based on tweet text, since raw text alone is insufficient to capture the full meaning present in images.
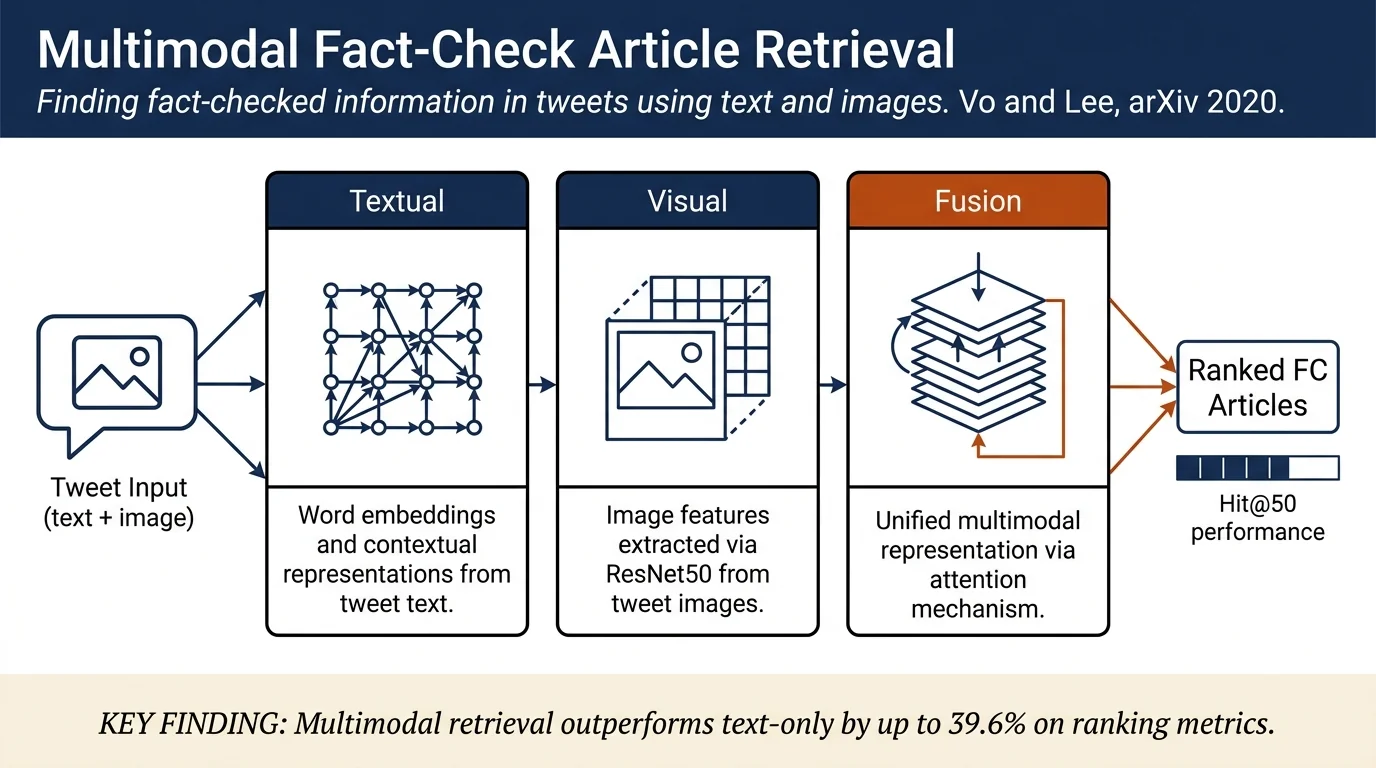
Multimodal Attention Network (MAN). Three-component architecture:
-
Textual Matching Layer. Uses Glove embeddings combined with contextual word embeddings from ELMo; derives Glove interaction matrix S and contextual word embedding interaction matrix C; learns dissimilarity matrix G via a sigmoid function to avoid over-reliance on raw similarities (handles cases like "hillar" vs. "hillary" that have high similarity but different meanings).
-
Visual Matching Layer. Uses ResNet50 to extract image representations; computes pairwise similarity matrix V between tweet and article images.
-
Unifying Textual and Visual Information. Concatenates scalar similarity score (computed from visual features) with textual feature vector; trains a dense layer to learn joint representations.
Training. Triplet loss minimization using original tweets paired with relevant and non-relevant FC-articles.
Results¶
Experimental Setup. Split Snopes and PolitiFact datasets into train/validation/test with 80/10/10 ratio. Evaluated using NDCG@K and Hit@K metrics.
Performance of Basic Retrieval. BM25 on tweets' text achieves ~50% Hit@50 (Snopes) and ~70% (PolitiFact). Adding images (BM25-I) improves Hit@50 to ~80% (Snopes) and ~94% (PolitiFact).
Multimodal Attention Network. MAN consistently outperforms all baselines: - On Snopes: 4.7% improvement on NDCG@1, 17.2% improvement on Hit@50 - On PolitiFact: 3.9% improvement on NDCG@1, maximum improvement of 39.6% on Hit@50 - On left-over queries: MAN-A (with augmented training data for sparse textual signals) achieves best results with 8% and 11% improvement on Snopes/PolitiFact
Ablation Studies. Contextual word embeddings from ELMo are more effective than Glove alone for capturing semantic nuances; combining Glove and ELMo (CTM) achieves strong improvements over baselines.
Connections¶
- Related to Hierarchical Multi-head Attentive Network for Evidence-aware Fake News Detection via multimodal and evidence-aware fact-checking approaches from the same group
- Complementary to DeClareE: Debunking Fake News and False Claims using Evidence-Aware Deep Learning which uses evidence for debunking via deep learning
- Extends MVAE: Multimodal Variational Autoencoder for Fake News Detection and EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection by focusing specifically on fact-checking article retrieval rather than veracity classification
- Applied in A Picture Paints a Thousand Lies? The Effects and Mechanisms of Multimodal Disinformation and Rebuttals Disseminated via Social Media and related multimodal fact-checking scenarios
Notes¶
Strengths: Novel problem formulation (finding FC-articles rather than just verifying claims); genuine multimodal design that captures word-level interactions via contextual embeddings; strong empirical results showing multimodal substantially beats text-only; publicly released code and datasets enable reproducibility.
Limitations: Limited to English-language datasets (Snopes, PolitiFact); evaluation restricted to political and consumer fact-checking domains; assumes fact-checking articles already exist for claims (reactive rather than proactive); doesn't address scalability for real-time deployment at social media scale.
Open questions: How does the approach generalize to new fact-checking sources and emerging claims? Can the framework be extended to cross-lingual retrieval? How sensitive is the model to the quality and comprehensiveness of the FC-article repository?