Misinformation Has High Perplexity¶
Authors: Nayeon Lee, Yejin Bang, Andrea Madotto, Pascale Fung
Affiliation: Center for Artificial Intelligence Research (CAiRE), Hong Kong University of Science and Technology
ArXiv: 2006.04666
TL;DR¶
False claims have measurably higher perplexity when scored by a language model primed with truthful evidence, while true claims have lower perplexity. The authors exploit this observation to build an unsupervised debunker that achieves 75% accuracy on scientific COVID-19 claims with minimal labeled data, releasing two new annotated test sets.
Contributions¶
- Novel application of language model perplexity as a falseness signal for claim verification
- Data-efficient debunking methodology using pre-trained language models (GPT-2) without supervised training labels on the debunking task
- Two new COVID-19–related test sets: Covid19-scientific (142 claims from scholarly sources) and Covid19-politifact (340 claims checked by journalists)
- Empirical demonstration that the approach outperforms baseline fact-checking models when training data is scarce
Method¶
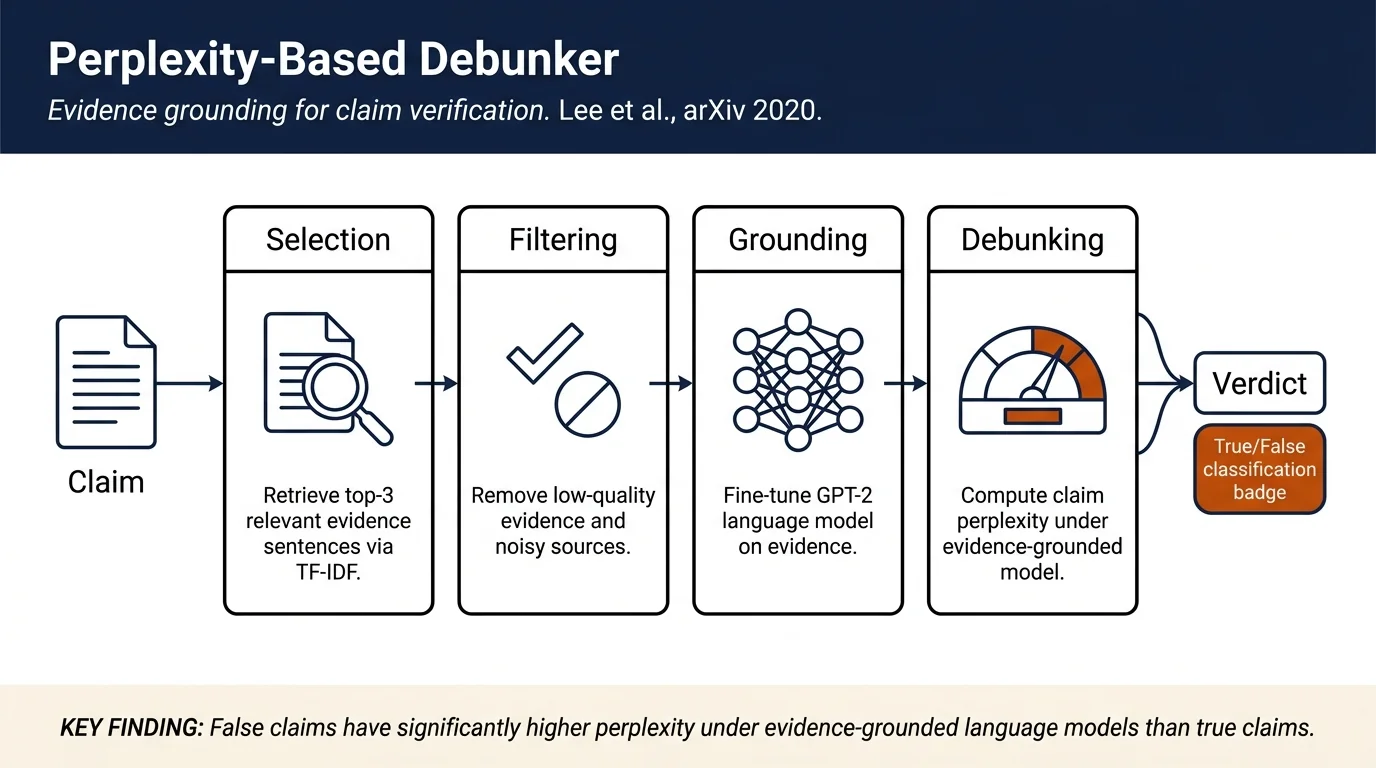
The system performs debunking in three steps.
Evidence Selection retrieves the top-3 most relevant evidence sentences from source documents using TF-IDF scoring.
Evidence Filtering removes low-quality evidence: quotes from unnamed speakers or social media posts, evidence from the claim's original speaker, and reciprocal questions that add noise without supporting signal.
Language Model Grounding fine-tunes GPT-2 on the extracted evidence sentences, training the model to assign high probability to language that aligns with truthful sources. The key insight is that a model trained on truthful knowledge will assign low probability (high perplexity) to false statements.
Debunking via Perplexity computes the perplexity of each claim under the evidence-grounded model. Claims exceeding a perplexity threshold are classified as False; those below are classified as True. The threshold is tunable to control the desired strictness toward false claims.
Results¶
On two COVID-19 test sets, the LM Debunker achieved:
- Covid19-scientific: 75.4% accuracy, 69.8% F1-Macro over 142 claims
- Covid19-politifact: 74.4% accuracy, 58.8% F1-Macro over 340 claims
These results substantially outperform baseline models: Fever-HexaF (64.8% accuracy), LiarPlus (42.3%), and LiarOurs (61.5%).
Notably, the system is data-efficient. With only 500 labeled training examples on Covid19-politifact, it achieved 73.5% accuracy—comparable to models trained on 10,000 examples—demonstrating strong transfer learning from pre-trained representations.
The paper includes ablation studies showing that evidence filtering improves F1-Macro by 13.5%–8.3% with only 1% accuracy loss, and that 5 epochs of fine-tuning strikes the best balance between fitting evidence and generalization.
Datasets¶
The paper releases two test sets publicly:
- Covid19-scientific: 142 claims (101 false, 41 true) extracted from scholarly articles, medical news sources (CDC, WHO, MedicalNewsToday), and verified against reliable sources.
- Covid19-politifact: 340 claims (263 false, 77 true) from the Politifact website, with finer-grained labels (pants-fire, false, barely-true, half-true, mostly-true, true) mapped to binary for consistency.
Connections¶
- Related to Zhou & Zafarani (2020) — A Survey of Fake News via shared emphasis on evidence-based verification and machine learning for detection
- Contrasts with Wang (2017) — Liar, Liar Pants on Fire in using evidence grounding rather than political metadata features
- Related to Thorne et al. (2018) — FEVER via three-stage architecture of evidence retrieval, filtering, and inference
Notes¶
Strengths: The core insight that misinformation exhibits higher perplexity under an evidence-grounded model is intuitive and well-motivated. The data efficiency is compelling for real-world deployment where labeled debunking data is scarce. The release of two new COVID-19 test sets is valuable for the community.
Limitations: The approach relies on the availability of clean, relevant evidence. In real-world scenarios where evidence quality is mixed or absent, performance may degrade. The paper leaves open the question of optimal evidence-selection and filtering strategies. The threshold-tuning is presented as an open research question rather than a principled solution.
Follow-ups: Future work could explore better evidence selection (beyond TF-IDF), integration of structured knowledge bases, and application to other languages and domains beyond COVID-19.