TweepFake: about detecting deepfake tweets¶
Authors: Tiziano Fagni, Fabrizio Falchi, Margherita Gambini, Antonio Martella, Maurizio Tesconi
Venue: arXiv preprint, 2020
arXiv: 2008.00036
TL;DR¶
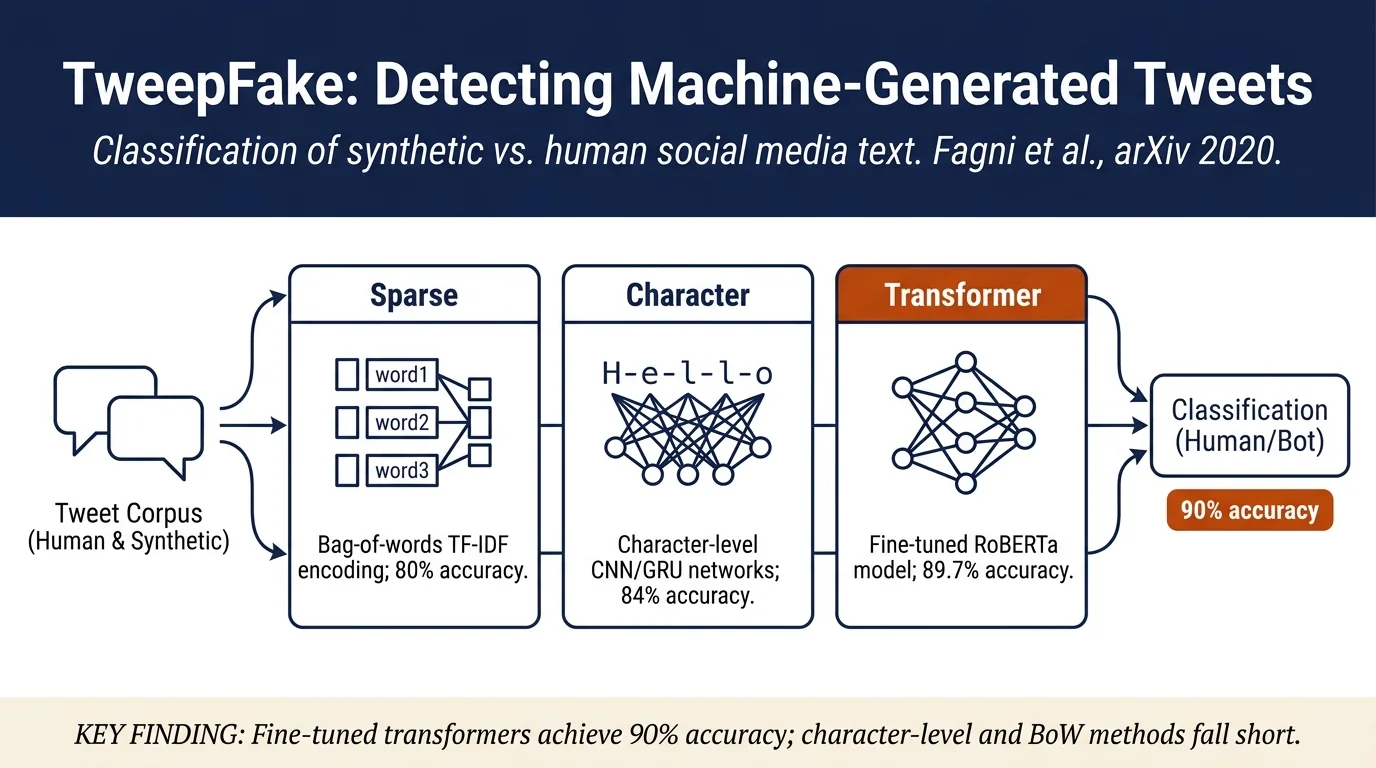
First publicly available dataset of real human-written and machine-generated tweets (TweepFake: 25,572 tweets, half human, half bot-generated from GPT-2, RNN, LSTM, Markov Chains, etc.). Benchmarks 13 detection methods and finds that transformer-based models fine-tuned on this task (RoBERTa) achieve ~90% accuracy, while BoW approaches fail (~80%). Character-level encodings work surprisingly well for short text, especially when combined with deep learning.
Contributions¶
- TweepFake dataset: First publicly labeled dataset of real and machine-generated social media messages. 25,572 tweets collected from 23 bot accounts (generated via multiple algorithms) and 17 human accounts; publicly available on Kaggle
- Diverse generation techniques: Bot tweets generated using Markov Chains, RNN, RNN+Markov, LSTM, GPT-2, and other methods, capturing variation in generation quality and style
- Comprehensive benchmark: Evaluates 13 different detection approaches using three encoding strategies (BoW, BERT, character-level) and three classifier types (logistic regression, random forest, SVM) plus deep learning networks
- Practical insights on detection trade-offs: Character-level representations outperform BoW; native language models (RoBERTa fine-tuned) achieve best results; human tweets and GPT-2 tweets are harder to distinguish than older generation techniques
Method¶
Dataset construction:
The authors collected tweets from 23 bot accounts and 17 human accounts imitated by those bots. Bot accounts were generated using various techniques: Markov Chains, RNN, RNN+Markov, LSTM, GPT-2, Torch RNN, CharRNN, OpenAI, and unknown methods. The final balanced dataset contains 12,572 human tweets and 12,572 bot tweets (total 25,572). The dataset is publicly available on Kaggle; code is published on GitHub.
Detection methods tested:
Three main encoding approaches were explored:
- Bag-of-Words (BoW) + TF-IDF: Standard sparse feature representation with logistic regression, random forest, and SVM classifiers
- BERT-based encodings: Context-aware embeddings from pretrained BERT, fine-tuned on the TweepFake task
- Character-level representations: Three neural network architectures tested:
- CHAR_CNN: CNN sub-network with three kernel sizes (3, 4, 5)
- CHAR_GRU: Bidirectional GRU layer
- CHAR_CNNGRU: Combined CNN and GRU architecture
Additionally, fine-tuned native language models were tested: - BERT_FT, DistilBERT_FT, RoBERTa_FT, XLNet_FT: Pretrained language models fine-tuned on the balanced TweepFake dataset
Experimental setup:
All experiments implemented in scikit-learn and Keras. BoW models optimized on validation set; deep learning models trained for 3 epochs on GPU. Tweets tokenized with stop-word removal and hashtag/URL replacement. Vocabulary limited to 25,000 most frequent tokens. For character-based models, tweets encoded as contiguous character IDs (max length 280 tokens).
Results¶
Overall accuracy on test set (Table 4):
Fine-tuned native language models achieved best performance: - RoBERTa_FT: 89.7% global accuracy - XLNet_FT: 87.7% global accuracy - DistilBERT_FT: 88.7% global accuracy
Character-level methods (CHAR_CNN, CHAR_GRU, CHAR_CNNGRU) achieved 83-84% accuracy.
BERT-based approaches achieved ~83.5% accuracy.
BoW methods were weakest (~80-81% accuracy across classifiers), confirming that sparse bag-of-words representations lose important contextual signal for this task.
Per-account accuracy (Figure 2 heatmap):
- Human tweets: methods achieve higher precision but lower recall; harder to identify bot tweets from accounts that imitate humans
- RNN-generated tweets: Easiest to detect (~93-100% accuracy)
- GPT-2-generated tweets: Hardest to detect (~63-74% accuracy depending on method); newest and most sophisticated generator poses the greatest challenge
- Others (LSTM, Markov, mixed): Intermediate difficulty
Key observation:
Character-level models maintain better balance between human and bot detection than text-representation-based approaches. RoBERTa-based detector achieved nearly 90% accuracy on RNN tweets but only 65% on GPT-2 tweets, suggesting newer generators produce more human-like text.
Connections¶
- Related to Generated text detection — shares the same core problem: machine vs. human text discrimination; differs in domain (tweets vs. news articles)
- Connected to Bot detection — social media bots are often detected via behavioral signals, but TweepFake focuses on text generation artifacts
- Shares methods with Neural text generation — understanding what makes generated text detectable informs both generation and detection research
- Complements work on Deepfakes — extends deepfake detection (originally video-focused) to the text domain on social media
- Related to Social media manipulation — bot-generated tweets are a core misinformation vector on Twitter and other platforms
Notes¶
Strengths: - First publicly available dataset specifically designed for deepfake tweet detection; addresses important gap in research (prior work focused on video deepfakes, not social media text) - Diverse generation methods in dataset reflect realistic bot ecosystem (multiple libraries, parameterizations) - Comprehensive benchmark of 13 methods provides solid baseline for future work - Practical insights on encoding strategies: character-level models are surprisingly effective for short text, contradicting assumptions about BoW's adequacy for microblogging - Fine-tuned transformer models achieve competitive accuracy; result aligns with broader NLP trends
Weaknesses: - Limited to English Twitter; generalizability to other platforms (Facebook, Reddit, Telegram) and languages unclear - Bot accounts are imitated human accounts (synthetic human persona), not necessarily realistic bot behavior (e.g., automated posting schedules, bot-to-bot interaction) - Dataset may overrepresent certain generation methods (GPT-2) and underrepresent others; real-world bot ecosystem has different distribution - No analysis of adversarial robustness: can bots adapt their text generation to evade detectors? - Detection performance drops significantly on GPT-2 tweets (65-80% accuracy), suggesting the arms race is just beginning; GPT-3 and larger models not tested - Temporal effects not explored: does detector performance degrade as bots and generators improve over time?
Implications: - Character-level and fine-tuned transformer models are effective for tweet-level text generation detection in controlled settings - Older generation methods (RNN, Markov) are easily detected; modern methods (GPT-2) require more sophisticated detectors - Short text (tweets) poses different challenges than long-form generated content (articles); detection strategies may not transfer across domains - Future work should test adversarial scenarios and deployment-time robustness on evolving bot and generator populations