Defending Against Neural Fake News¶
Authors: Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, Yejin Choi
Venue: NeurIPS 2019, Vancouver, Canada — arXiv
TL;DR¶
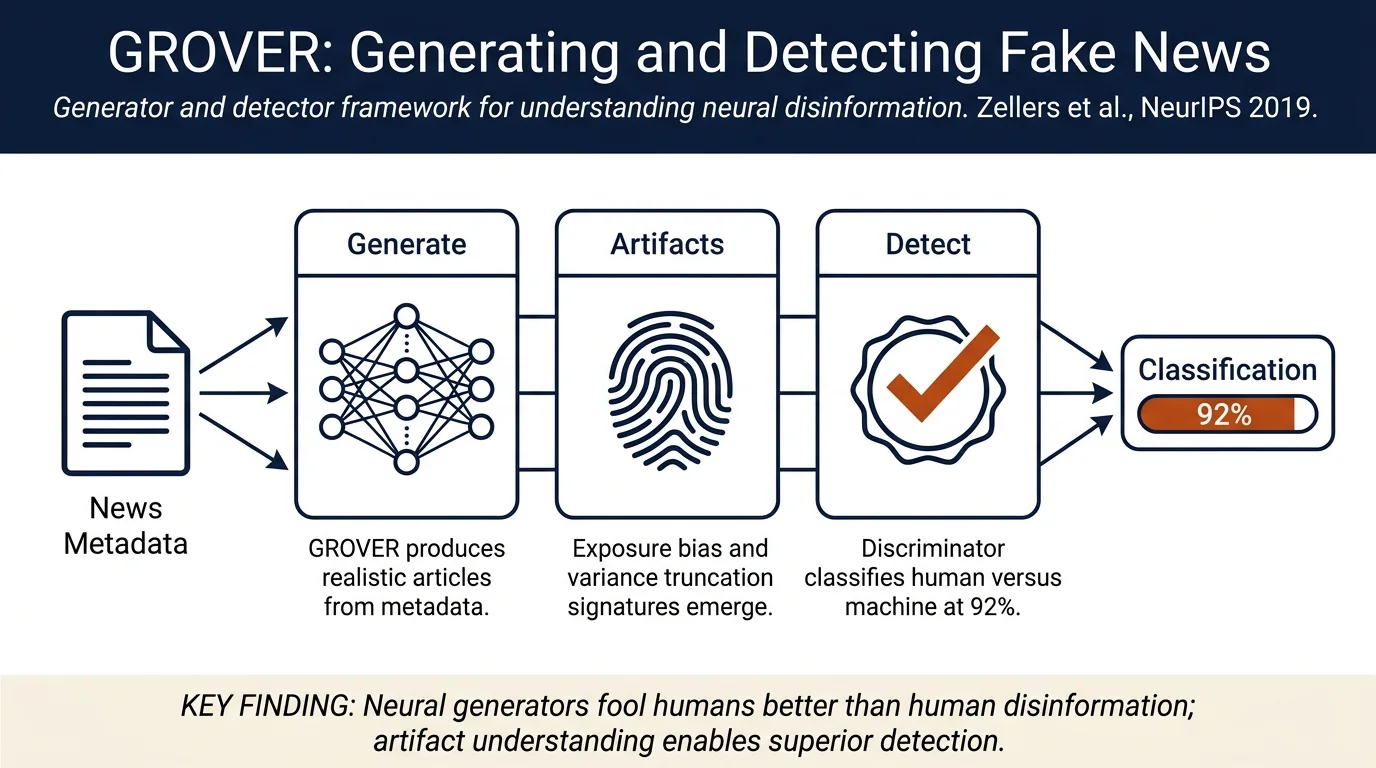
Zellers et al. introduce GROVER, a conditional neural text generation model that can both generate and detect neural fake news. The paper shows that humans cannot reliably distinguish GROVER-generated propaganda from real human-written disinformation, rating machine-generated propaganda as more trustworthy (2.42/3 vs 2.19/3 for human disinformation). Crucially, GROVER itself achieves ~92% accuracy at detecting its own generations—better than BERT or GPT2—suggesting that understanding how generative models produce artifacts (via exposure bias and variance truncation) enables better defenses.
Contributions¶
- GROVER: Controllable conditional text generation — A transformer-based model that generates full news articles conditioned on metadata (domain, date, authors, headline, body), enabling systematic exploration of neural fake news production.
- REALNEWS dataset — A large corpus of 120 GB of news articles (deduped to 7.1M articles) extracted from Common Crawl, suitable for training generative and discriminative models on authentic news structure.
- Empirical evidence of human vulnerability — Demonstrates that humans rate GROVER-generated propaganda as more credible than hand-written false claims, and cannot reliably distinguish machine from human-written disinformation.
- Detection via understanding generation artifacts — Shows that GROVER outperforms standard discriminators (BERT, GPT2) at detecting neural fake news, likely because understanding exposure bias and variance-reduction artifacts helps identify machine-generated text.
- Thorough analysis of generation failure modes — Investigates how sampling strategy (Nucleus Sampling), exposure bias, and variance reduction interact to create distinguishable artifacts in neural text generation.
Method¶
Generative model (GROVER):
Extends GPT2-style left-to-right language modeling to conditional generation over structured news articles. Articles are modeled as a joint distribution over five fields in order: domain, date, authors, headline, body. The model learns to decompose this joint distribution, allowing flexible inference: given partial context (e.g., domain and date), GROVER can generate the remaining fields or resample individual fields while keeping others fixed. Three model sizes were trained: GROVER-Base (12 layers, 124M params), GROVER-Large (24 layers, 355M params), and GROVER-Mega (48 layers, 1.5B params). Training used Nucleus Sampling (top-p) with p=0.96 for controlled, realistic generation.
Discriminative models:
Evaluated four discriminators against GROVER-generated text:
- GROVER-discriminator: A version of GROVER adapted for classification; adds a [CLS] token at the end and extracts the final hidden state.
- GPT2: Standard pretrained GPT2 (124M or 355M).
- BERT: Bidirectional encoder (110M or 340M parameters).
- FastText: Shallow n-gram classifier.
All models are trained to classify articles as Human or Machine on a balanced dataset (10k real articles, 10k GROVER-generated, split 5k train / 2k valid / 8k test).
Dataset (REALNEWS):
Constructed by scraping news article bodies and metadata from Common Crawl, yielding 120 GB uncompressed (7.1M articles after deduping). Articles range from December 2016 to March 2019. For evaluation, articles published in April 2019 were held out to ensure the discriminator hasn't seen evaluation data at training time.
Human evaluation:
Amazon Mechanical Turk workers rated articles on three dimensions: style consistency, content sensibility, and overall trustworthiness (1–3 scale). Three annotators per article; 100 articles in each of four conditions: (1) human news, (2) machine news, (3) human propaganda, (4) machine propaganda.
Results¶
Language modeling:
GROVER achieves 2.3–2.8 perplexity on the body field (conditional on metadata), compared to 2.4–2.6 for GPT2 and 3.3+ for BERT-Large. The model learns effectively when conditioned on partial context; even with all but one field provided, perplexity improves substantially.
Detection accuracy:
GROVER discriminator achieves ~90% accuracy at detecting GROVER-Mega generations in a balanced unpaired setting (single human article vs. single machine article). When GROVER has access to 5000 machine examples during training, accuracy rises to 92%. In contrast, GPT2 discrimination drops below 81%, and BERT varies widely (60–90% depending on hyperparameters).
Paired setting analysis:
In a more realistic semi-supervised scenario (discriminator has access to abundant real articles but few machine-generated examples), GROVER's performance remains strong. With only 16 examples from GROVER-Mega and 256 from GROVER-Large, discrimination accuracy reaches 78%. When access improves to 5000 examples, accuracy converges toward 92%.
Human evaluation:
Qualitative assessment shows GROVER-generated propaganda is rated as more trustworthy (mean 2.42/3) than human-written propaganda (2.19/3). Humans find machine-generated articles harder to distinguish from real news than human-written false claims, indicating that neural generation produces stylistic regularity that resembles authentic journalism.
Exposure bias and variance artifacts:
GROVER exhibits predictable failures tied to sampling strategy:
- Exposure bias: When the model trains on human sequences but samples from its own distribution at test time, it accumulates errors. Random sampling from the full vocabulary produces lower perplexity on human text but falls increasingly out-of-distribution as length increases.
- Nucleus Sampling artifacts: Limiting sample variance (low p) creates artificial artifacts: repetitive token sequences, unnatural semantic patterns. However, this variance reduction makes the text more easily classified as machine-generated.
- Sweet spot: Medium p (0.90–0.96) balances realism (low perplexity on human text) and variance reduction; this is the hardest region for discriminators.
Connections¶
- Raffel et al. (2019) — T5: Text-to-Text Transfer Transformer — shares architectural foundations (large Transformer language models for conditional generation) but focuses on task-agnostic pretraining rather than news-specific generation.
- Zhou & Zafarani (2020 survey) — comprehensive taxonomy of detection methods; discusses neural generation as an emerging threat.
- Related to Neural text generation — methodological work on understanding and controlling generative model outputs.
- Related to Fake news detection — proposes detection strategy grounded in understanding generation mechanisms.
- Related to Disinformation — explores both generation and defense in adversarial threat model.
- Related to Adversarial Machine Learning — frames problem as arms race between increasingly capable generators and detectors.
Notes¶
Strengths: - Novel framing of neural fake news as a dual-use threat (can detect as well as generate). - Thorough empirical investigation of why standard discriminators fail: exposure bias and variance truncation are concrete, explainable failure modes. - Human evaluation confirms the practical threat—machines fool humans better than human-written disinformation. - Large, high-quality REALNEWS dataset enables training large generative models on authentic news. - Clear release strategy: authors promise to release GROVER openly to facilitate defensive research.
Weaknesses: - Dataset (REALNEWS) is English-only and predominantly from 2016–2019 online news; generalization to other domains, languages, and time periods is unclear. - Human evaluation is small (100 articles × 3 annotators); inter-annotator agreement and power analysis are not reported. - The claim that GROVER is the "best" discriminator is qualified by hyperparameter search asymmetries; BERT and GPT2 may perform better with different tuning. - Practical threat model assumes adversary has access to Grover's training data or a close proxy; generalization to unknown adversarial generators is an open question. - The paper focuses on text-only articles; images, videos, and multimodal fake news are mentioned but not explored.
Follow-ups and open questions: - How do discriminators perform against neural generators with different architectures (e.g., large pretrained models like GPT3, BART, T5)? - Can adversarial training or domain adaptation improve discrimination across different generator families? - What is the effectiveness of exposure-bias and variance-reduction artifacts as universal signatures of neural generation, or are they model-specific? - How should GROVER's release be governed to balance defensive research against malicious use?