A Richly Annotated Corpus for Different Tasks in Automated Fact-Checking¶
Authors: Andreas Hanselowski, Christian Stab, Claudia Schulz, Zile Li, Iryna Gurevych
Venue: arXiv preprint, 2019 — arxiv:1911.01214
TL;DR¶
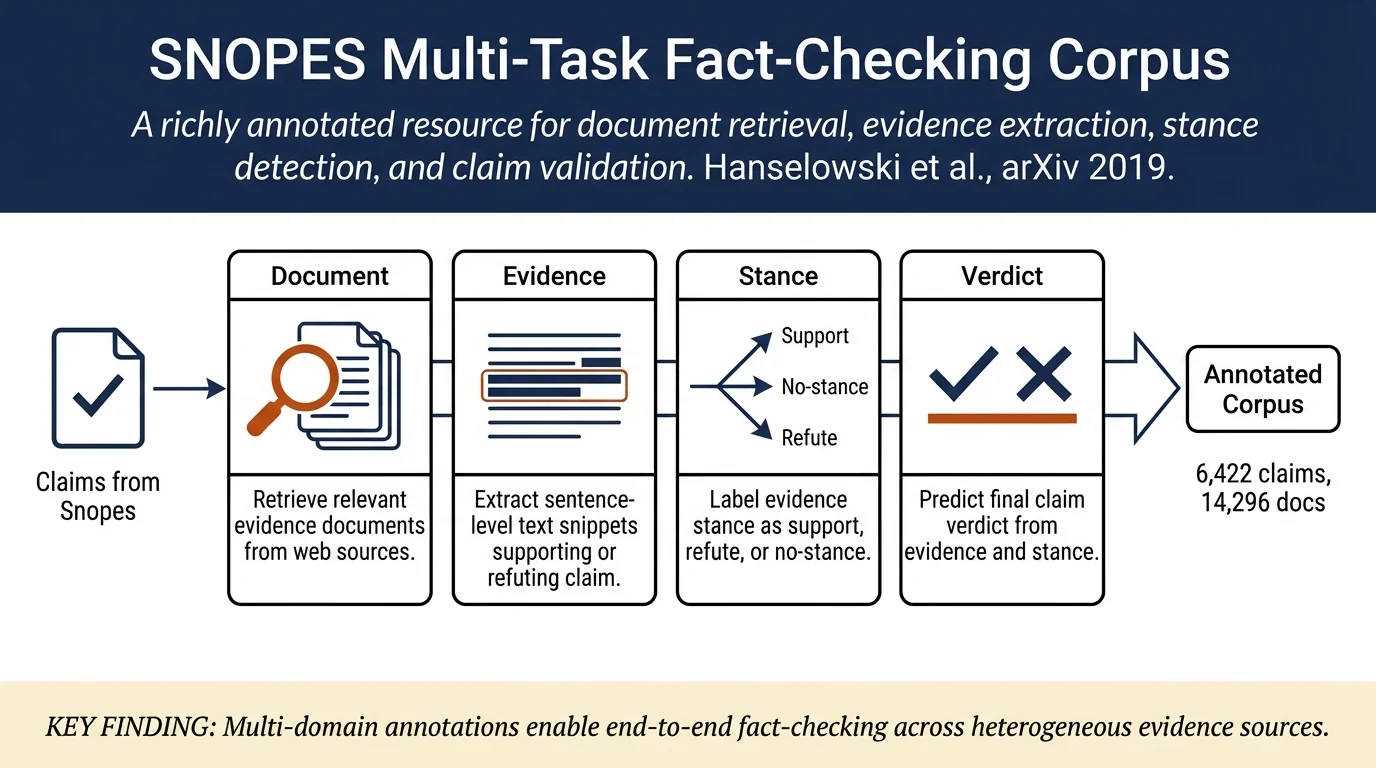
The paper introduces SNOPES, a large-scale fact-checking corpus with 6,422 validated claims and 14,296 documents covering multiple domains (news, social media, blogs). Each claim is annotated with evidence text snippets, evidence stance (support/refute/no stance), and verdicts, enabling training of models for four core fact-checking subtasks: document retrieval, evidence extraction, stance detection, and claim validation.
Contributions¶
- Introduction of SNOPES, a substantially larger multi-domain fact-checking corpus than existing resources (e.g., FEVER), with 6,422 claims and comprehensive annotations.
- Detailed corpus construction methodology and annotation scheme for stance, fine-grained evidence (FGE), and other metadata.
- Evaluation of high-performing models (FEVER, BERT, Fake News Challenge systems) on the corpus with focus on document retrieval, evidence extraction, stance detection, and claim validation.
- Detailed error analysis for each of the four fact-checking subtasks, identifying specific challenges and limitations of existing approaches.
- Open release of corpus and annotation code to support future research.
Method¶
The SNOPES corpus is constructed from claims curated on the Snopes fact-checking website. For each claim, the authors extract: - The claim text and associated verdict (false, mostly false, mostly true, true, or unproven/mixture) - Evidence text snippets (ETSs) from Snopes articles, with sentence-level granularity - Fine-grained evidence (FGE) annotations via crowdsourcing: crowd workers label which sentences in ETSs directly support or refute the claim - Stance annotations: explicit labels for whether ETSs support, refute, or express no stance toward the claim - Original documents (ODCs) retrieved from URLs provided by Snopes fact-checkers
The corpus covers diverse domains including news, social media, blogs, and other web sources. The annotation process employs multiple crowd workers per instance, with inter-annotator agreement measured via Cohen's Kappa and MACE agreement computation.
Results¶
Corpus statistics: - 6,422 claims with 14,296 related documents - 16,509 evidence text snippets (average 6.5 sentences per ETS) - 8,291 fine-grained evidence sets - Heavily skewed toward false claims (45.8% false vs. 10.3% true) - Stance distribution: 40.8% support, 13.7% refute, 45.5% no stance
Model performance (stance detection): - AtheneMLP (feature-based MLP): F1 = 0.596 (best performer) - DecompAttent: F1 = 0.534 - USE+MLP: F1 = 0.434 - Random baseline: F1 = 0.333
Evidence extraction (ranking setup, recall@5): - rankingESIM: recall = 0.507 - BilSTM: recall = 0.637 (best performer) - TF-Idf: recall = 0.601 - DecompAttent: recall = 0.627
Claim validation: - BertEmb: best performer with F1 ≈ 0.485 (macro) - extendedESIM: F1 = 0.454
The corpus is more challenging than FEVER due to heterogeneous sources and unreliable evidence. Error analysis reveals that supporting ETSs are frequently misclassified due to lexical overlap without genuine relevance, and stance is only weakly correlated with verdict (Pearson r = 0.16).
Connections¶
- FEVER dataset — compared as the most comprehensive prior resource for fact-checking
- LIAR dataset — earlier political claim corpus with limited annotations
- Nieminen — surveys fact-checking and automated fact-checking literature
- Fact-checking — core topic area
- Evidence extraction — one of the four tasks addressed
- Stance detection — key subtask evaluated
Notes¶
This is a foundational resource paper for multi-task fact-checking research. The SNOPES corpus fills an important gap by providing diverse, well-annotated claims from heterogeneous sources (unlike FEVER which is primarily Wikipedia-based). The detailed error analysis is particularly valuable, showing that the problem is genuinely challenging: even models achieving respectable scores on stance detection and evidence extraction still fail on claim validation due to the complexity of reasoning over unreliable sources. The work also highlights the trade-off between corpus size/domain coverage and annotation quality—a key constraint in building practical fact-checking systems. The public release of annotations and methodology significantly advanced the field's ability to develop and evaluate end-to-end fact-checking pipelines.