What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context¶
Authors: Ramy Baly, Georgi Karadzhov, Jisun An, Haewoon Kwak, Yoan Dinkov, Ahmed Ali, James Glass, Preslav Nakov
Venue: ACL 2020
ArXiv: 2005.04518
TL;DR¶
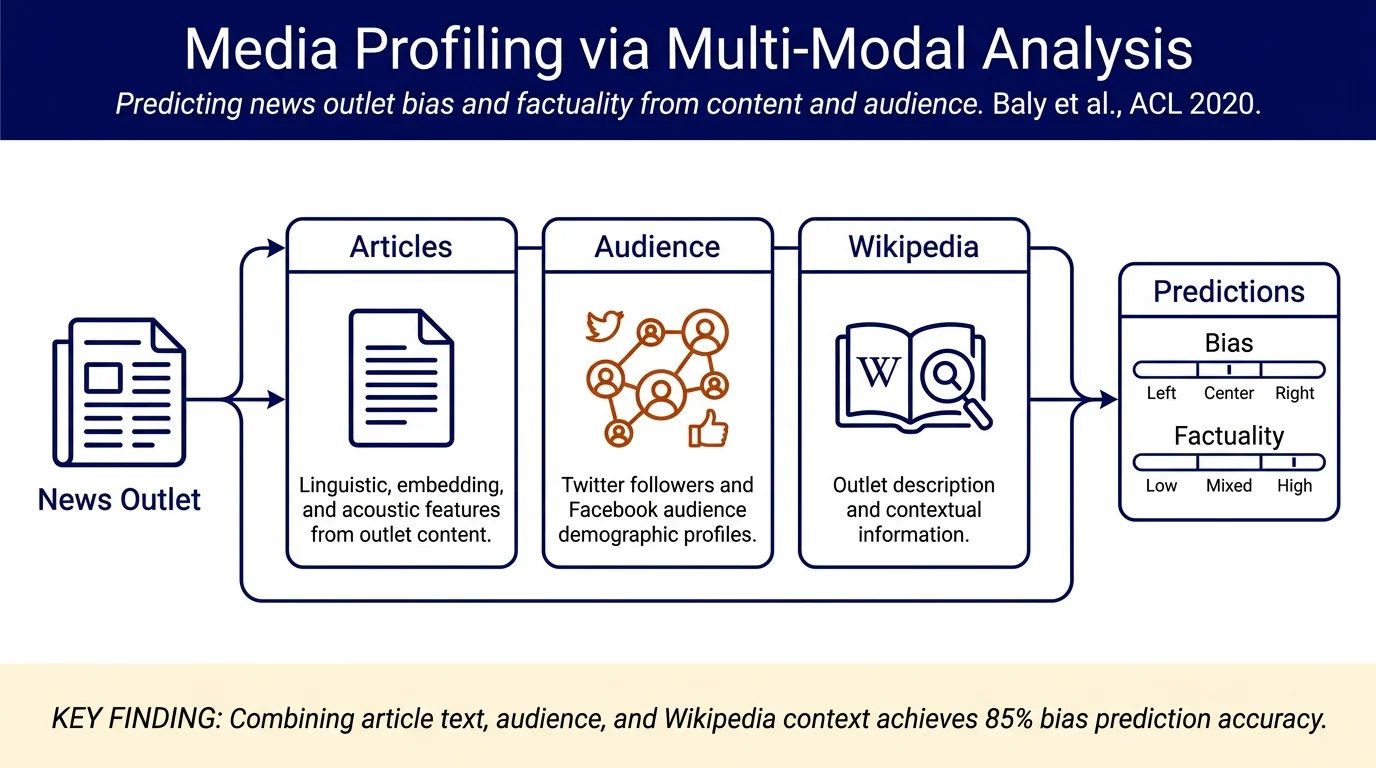
This paper predicts the political bias (left/center/right) and factuality (low/mixed/high) of news outlets by analyzing what articles they publish, who follows them on social media, and what Wikipedia says about them. The system achieves 85% accuracy on bias prediction by combining article text, YouTube video features, Twitter audience demographics, Facebook targeting data, and Wikipedia content—showing that social media context complements textual analysis.
Contributions¶
- Proposes a multi-modal approach combining three information sources: (i) textual content of news articles, (ii) social media audience demographics (Twitter followers, Facebook audience estimates), and (iii) Wikipedia descriptions of news outlets.
- Introduces methods to extract linguistic, embedding-based, and acoustic features from article text and YouTube videos; audience features from Twitter and Facebook; and contextual features from Wikipedia.
- Achieves significant improvements over baselines on the Media Bias/Fact Check (MBFC) dataset, improving political bias prediction by +6.17 macro-F1 points over prior work.
- Releases dataset, features, and code for reproducibility.
Method¶
The system models three aspects of a news outlet:
What Was Written¶
Articles published by the news outlet are analyzed for: - Linguistic features (via NELA toolkit): topic modeling, sentiment, subjectivity, complexity, bias indicators - Embedding-based features: fine-tuned BERT representations of article text, averaged across articles published by the outlet - Acoustic/multimedia features: for YouTube channels, OpenSmile LLDs (low-level descriptors) from video captions; frame-based energy features; MFCC coefficients
Who Read It¶
Audience demographics are extracted from: - Twitter followers: 5,000 followers per outlet analyzed; follower bios encoded with SBERT and averaged - Facebook audience estimates: Political leaning estimates (very conservative to very liberal) via Facebook Marketing API for audiences showing interest in each outlet - YouTube metadata: view counts, likes, dislikes, comment counts aggregated per video
What Was Written About the Medium¶
Wikipedia content about each news outlet is encoded: - First 510 tokens of the Wikipedia page for the outlet passed through pre-trained BERT to obtain outlet-level representation - Falls back to zeros if no Wikipedia page exists (61.2% coverage in dataset)
All feature representations are aggregated at the medium level and fed into SVM classifiers to predict political bias (3-class: left/center/right) and factuality (3-class: low/mixed/high).
Results¶
Political Bias Prediction (Table 2): - Best single aspect: Articles (BERT representations + probabilities) achieve 79.75% accuracy - Best combined model: Article + Twitter + YouTube features yield 85.29% accuracy (macro-F1 84.77) - Ensemble of all three aspects outperforms concatenation
Factuality Prediction (Table 3): - More difficult task; best result 68.90% accuracy - Article features remain most important; Twitter profile features hurt performance - Demonstrates that factuality requires more external/structural information
Key observations: - YouTube captions are the most useful single feature type among extracted sources - Combining "what was written" with "who read it" yields substantial improvements - Wikipedia features alone perform poorly; useful only when combined with other modalities - Ensemble methods consistently outperform feature concatenation
Connections¶
- Extends prior work on predicting media bias and factuality by incorporating social media context
- Related to Propagation-based fake news detection through use of audience information
- Uses similar BERT-based encoding methods as multimodal fake news detection systems
- Addresses media profiling research in the context of polarization and media choice
Notes¶
Strengths: - Novel approach combining three distinct information modalities without requiring redundant annotation - Careful feature engineering across multiple domains (NLP, social media, web) - Strong evaluation with explicit ablation studies showing contribution of each aspect - Addresses the often-overlooked "who reads it" dimension of media profiling
Weaknesses: - Factuality prediction significantly weaker than bias prediction, suggesting the task requires information beyond what social media and articles convey - Wikipedia coverage varies widely (only 61.2% of outlets have pages); creates a sparse feature for many outlets - Limited to outlets with sufficient social media presence; smaller outlets with less followers/audience data remain harder to profile - Evaluation limited to English-language US media; generalization to other languages/regions unclear
Future directions: - Incorporating graph structure of how claims propagate through social networks - Modeling temporal evolution of media outlets' bias and factuality - Extending to multilingual settings