Detection and Resolution of Rumours in Social Media: A Survey¶
Authors: Arkaitz Zubiaga, Ahmet Aker, Kalina Bontcheva, Maria Liakata, Rob Procter
Venue: ACM Computing Surveys, Vol. 51, No. 2, Article 32 (February 2018) — DOI | arXiv
TL;DR¶
Comprehensive survey of rumour detection and resolution in social media covering the entire pipeline: rumour definition and characterization, data collection strategies, annotation schemes, detection approaches for both emerging and long-standing rumours, tracking of rumour propagation, stance classification (support/deny/query/comment), and veracity classification (true/false/unverified). Describes four-component architecture for end-to-end rumour classification systems and reviews datasets, benchmarks, and challenges in the field.
Contributions¶
- Definition and typology: Formal definition of rumours as unverified information at posting time, distinguishing between newly emerging rumours (requiring real-time detection) and long-standing rumours (with known vocabulary)
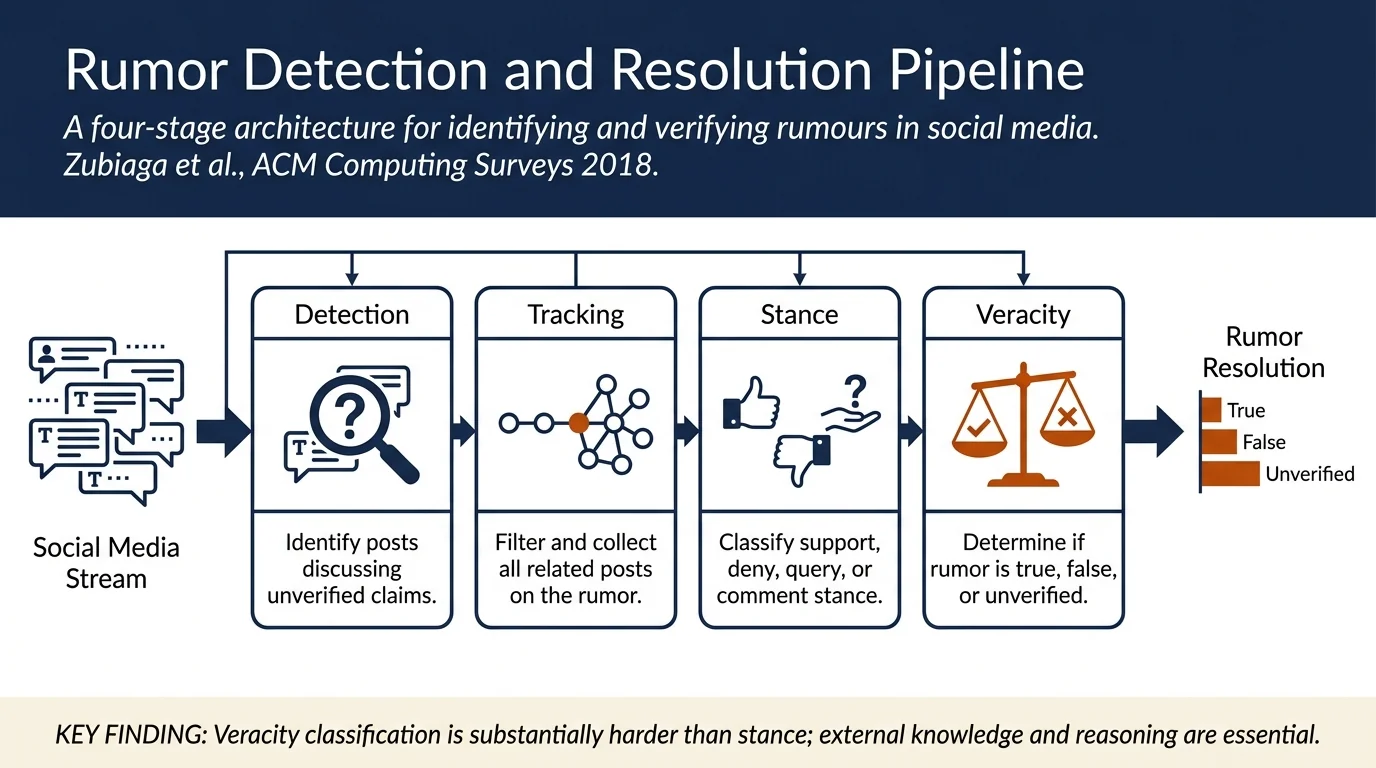
- Four-component architecture: Documents standard pipeline for rumour classification: Detection → Tracking → Stance Classification → Veracity Classification
- Data collection and annotation strategies: Reviews API-based collection (Twitter, Sina Weibo, Facebook), top-down vs. bottom-up sampling, manual annotation schemes for rumour identification, stance, and veracity
- Detection approaches: Surveys methods for both emerging and long-standing rumours, including keyword-based, context-learning, and enquiring-tweet approaches
- Tracking and stance classification: Reviews rumour tracking systems and stance annotation (support/deny/query/comment), including crowdsourcing and journalist expertise
- Veracity classification: Summarizes approaches ranging from feature engineering to deep learning, ensemble methods, and auxiliary information sources
- Benchmark datasets and evaluation: Documents public datasets (PHEME, Qazvinian et al., RumourEval) and evaluation metrics
- Synthesis and open challenges: Identifies directions for future research including cross-platform generalization, real-time detection, and handling emerging rumour vocabulary
Method¶
Definition and characterization of rumours¶
Rumours are defined as unverified information with uncertain veracity at the time of posting. The paper distinguishes rumours by temporal characteristics:
- Newly emerging rumours — appear during breaking news with unknown keywords requiring automatic detection and real-time classification; early detection and resolution are critical
- Long-standing rumours — circulate over extended periods with established vocabulary; can use retrospective classification with historical data
Four-component architecture¶
The pipeline from rumour detection to veracity classification:
-
Rumour Detection: Binary classification identifying whether a social media post is rumourous (unverified) or non-rumourous. For emerging rumours, detectors identify enquiring tweets; for long-standing rumours, keyword-based matching applies.
-
Rumour Tracking: Given a detected rumour, filtering the stream of social media posts to identify those discussing the rumour. Output: collection of posts related to the rumour with relevance filtering.
-
Stance Classification: Determining each post's stance toward the rumour's veracity. Standard four-label scheme (SDQC):
- Support (S): Author agrees the rumour is true
- Deny (D): Author refutes the rumour
- Query (Q): Author requests additional evidence
-
Comment (C): Author comments without direct veracity stance
-
Veracity Classification: Determining the rumour's truth value (true/false/unverified) using posts and external sources.
Data collection strategies¶
API access: Twitter provides most comprehensive API (streaming and historical); Sina Weibo (with admin approval); Facebook (limited to public pages and historically posted content with authentication)
Rumour sampling: - Top-down: Pre-defined rumour list, collect related posts; suits long-standing rumours with known keywords - Bottom-up: Broad event-based collection or filtered stream, annotate rumours post-hoc; identifies emerging rumours with novel vocabulary
Annotation: - Rumour identification: Binary or multi-category (true/false/unverified/irrelevant) - Stance: Four-way SDQC or reduced schemes - Veracity: True/false/unverified labels with optional confidence scores
Detection approaches¶
Emerging rumours: - Enquiring-tweet detection: Identify posts with questions/hedges, cluster by similarity (Zhao et al. 2015) - Context-learning: Sequential classifiers (CRF) learning temporal dynamics during events (Zubiaga et al. 2016b)
Long-standing rumours: - Keyword-based filtering: Pre-defined rumour keywords matched against posts - Feature-based classifiers: Content (text, unigrams), network (retweets), Twitter-specific (memes, URLs)
State-of-the-art: Context-aware approaches leveraging conversation structure outperform isolated tweet classification.
Tracking and stance approaches¶
Rumour tracking: Binary classification of post relevance to a given rumour. Features include content similarity, network structure, and temporal patterns. Tweet Latent Vector (TLV) approach more effective than traditional features.
Stance classification: Supervised classification using feature engineering or deep learning. Two-way classification (support/deny) straightforward (~67% accuracy); four-way SDQC harder due to comment class imbalance (71% of training data). Sequential models (CRFs, LSTMs) improve over bag-of-words by capturing conversation context.
Veracity classification¶
Datasets: PHEME (9 events, 297 rumours), Qazvinian et al. (5 rumours, 10K+ tweets), RumourEval 2017 (300+ rumours, annotation by journalists and crowdsourcing)
Approaches: - Feature engineering: Linguistic, network, temporal, user credibility features - Deep learning: LSTMs, CNNs on tweet embeddings; ensemble methods - Auxiliary information: Wikipedia, news articles, fact-checking databases - Confidence calibration: Assigning uncertainty scores alongside veracity predictions
Results: Stance classification achievable (78%+ accuracy); veracity remains challenging (below 64% on FEVER, RumourEval 2017), suggesting external knowledge and sophisticated reasoning required.
Key Datasets¶
- PHEME: 297 rumours across 8 newsworthy events (Charlie Hebdo, Ferguson, Germanwings, etc.), 5,599 tweets with stance/veracity annotations
- Qazvinian et al. (2011): 5 rumours with 10K+ tweets, relevance annotations
- RumourEval 2017: 325 rumours from 10 events, SDQC stance and veracity labels from 13 participating systems
- RumourEval 2018, 2019: Extended task with Reddit data, larger participant pools (22 systems in 2019)
Connections¶
- Related to Stance detection literature; builds on SemEval-2016 Task 6 frameworks
- Directly informs RumourEval shared tasks establishing benchmarks
- Precedes RumourEval 2019 extended to Reddit with pre-trained contextual embeddings
- Complements Misinformation and fake news detection and Fake news detection broader fields
- Influences Veracity Assessment approaches and systems
- Synthesis work in Rumour Verification Surveys topic
- Foundational for Temporal Rumour Evolution and Context Aware Rumour Detection research
Notes¶
Strengths: - Authoritative and comprehensive survey covering entire pipeline with unified terminology - Clearly delineates task definitions, datasets, and evaluation metrics for each component - Distinguishes emerging vs. long-standing rumours—crucial distinction often overlooked - Extensive literature review (100+ citations) spanning psychology, NLP, and social media analysis - Pragmatic guidance on data collection APIs, annotation strategies, and crowdsourcing trade-offs - Identifies temporal aspects and conversation structure as key features for tracking and stance
Limitations and open challenges: - Veracity classification remains substantially harder than stance, suggesting external knowledge and inference are bottlenecks - Most work limited to English; cross-lingual generalization under-explored - Emerging rumour detection hampered by vocabulary drift and label scarcity in early stages - Long-standing rumours may require historical context not always available - Platform-specific features (Twitter-centric); generalization to Reddit, TikTok, WhatsApp limited - Class imbalance in stance (comments dominate) impacts learning; few papers address this systematically - Confidence calibration for veracity predictions rarely studied despite practical importance
Impact and relevance: This survey became canonical in the field, cited as foundational reference for rumour detection pipelines. Its four-component architecture and distinction between rumour types shaped subsequent work. The PHEME dataset and RumourEval shared tasks (2017–2019+) directly trace to this work, establishing benchmarks that still drive research. The survey's emphasis on ensemble methods and contextual information informed the shift toward pre-trained transformer models in follow-up work (BERT, RoBERTa, GPT) that achieved state-of-the-art in RumourEval 2019.