The Clickbait Challenge 2017: Towards a Regression Model for Clickbait Strength¶
Authors: Martin Potthast, Tim Gollub, Matthias Hagen, Benno Stein Venue: arXiv:1812.10847 — arXiv
TL;DR¶
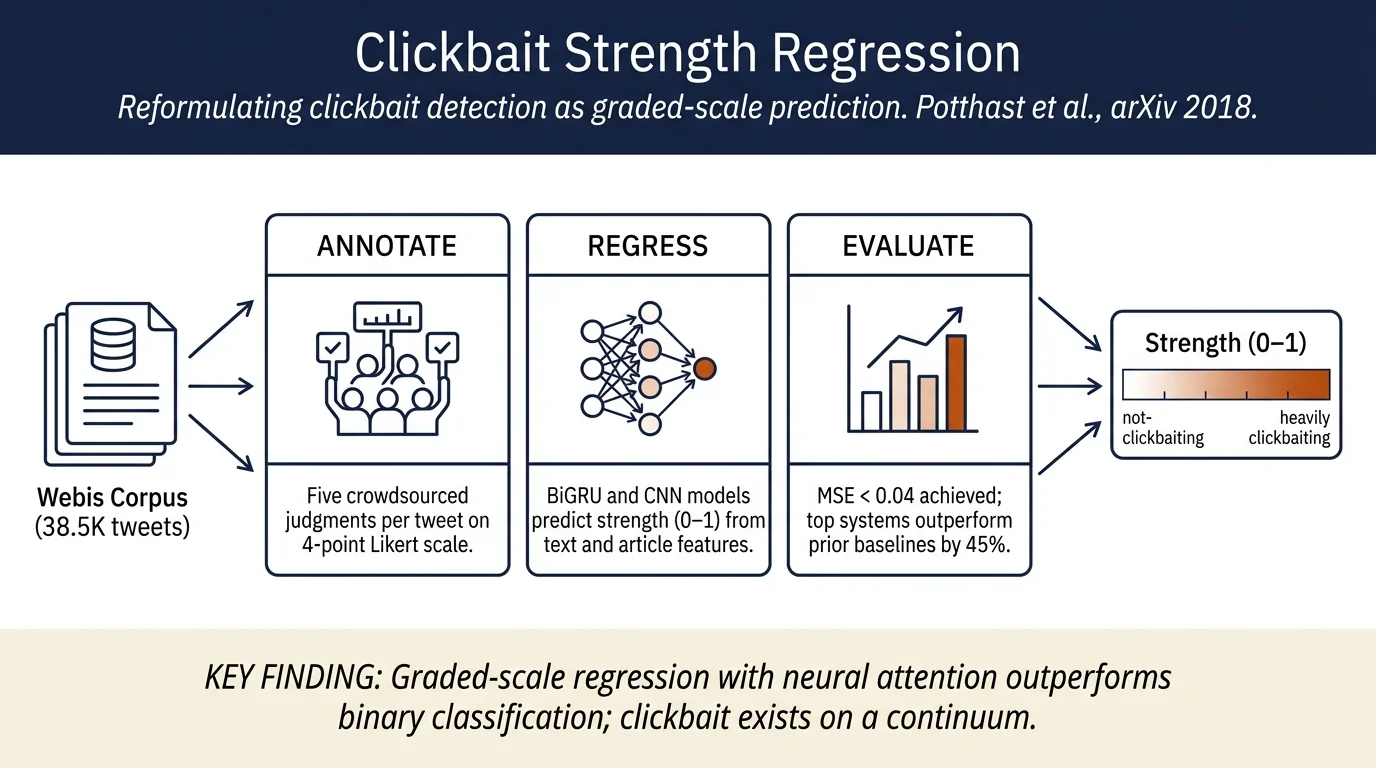
Clickbait detection is typically framed as binary classification, but teaser messages exhibit varying degrees of clickbaiting techniques. This paper organizes the Clickbait Challenge 2017, reformulating the task as regression to measure clickbait strength on a graded scale. Using the Webis Clickbait Corpus 2017 (38,517 annotated tweets), thirteen submitted approaches achieve significant improvements over prior work, with the best (zingel) reaching MSE of 0.033 using bidirectional GRU networks with attention.
Contributions¶
- Reformulation of clickbait detection from binary classification to regression-based measurement of clickbait strength
- Introduction of Webis Clickbait Corpus 2017: 38,517 tweets with graded 4-point Likert scale annotations (not/slightly/considerably/heavily clickbaiting)
- Organization of competitive shared task with 13 submitted systems, advancing state-of-the-art performance significantly over previous baselines
- Evaluation-as-a-service platform (TIRA) for reproducible, ongoing evaluation of new approaches
- Analysis of diverse approaches including neural networks, ensemble methods, and linguistic feature extraction
Method¶
The challenge reframes clickbait detection as a regression task measuring clickbait strength (continuous [0, 1]) rather than binary classification. The authors motivate this with the observation that teaser messages exist on a continuum: while some are obviously clickbait ("You won't believe what happened!"), many messages fall between extremes—containing some misleading elements but not overtly deceptive.
Dataset construction: The Webis Clickbait Corpus 2017 collects tweets from 27 top US news publishers (ranked by retweets) over December 2016—April 2017. Each tweet includes: - Tweet text and metadata (media attachments, timestamps) - Linked article content (archived via WARC format for reproducibility) - 5 crowdsourced annotations per tweet using Amazon Mechanical Turk with 4-point Likert scale (mode classification with 5th annotation as tiebreaker)
Annotation scale: 0.0 (not clickbaiting), 0.33 (slightly), 0.66 (considerably), 1.0 (heavily). Fleiss' κ = 0.21 between-group agreement; binarized κ = 0.36, matching agreement levels of expert-annotated prior corpus.
Evaluation metric: Primary metric is mean squared error (MSE) against mean annotator judgment. Secondary metrics include F1 score on binarized clickbait class, precision, recall, and runtime.
Results¶
13 teams submitted systems; 6 outperformed the strong baseline (ridge regression on prior features):
| Approach | MSE | NMSE | F1 | Architecture | Features |
|---|---|---|---|---|---|
| zingel | 0.033 | 0.452 | 0.683 | BiGRU + attention | Word embeddings (Glove) |
| emperor | 0.036 | 0.488 | 0.641 | CNN | Teaser text only |
| carpetshark | 0.036 | 0.492 | 0.638 | Ensemble SVM | Multiple text fields, image captions |
| arowana | 0.039 | 0.531 | 0.656 | — | — |
| pineapplefish | 0.041 | 0.562 | 0.631 | LSTM + dense | Linguistically-infused |
Best approaches combined: - Neural architectures: BiGRU/BiLSTM with attention mechanisms outperformed feature-engineering baselines - Multiple input modalities: Top systems leveraged teaser text, article fields (title, description, keywords, paragraphs), and sometimes image captions - Pre-trained embeddings: Glove (Wikipedia) and Google News embeddings used widely; character-level embeddings in some approaches - Semantic similarities: Siamese networks computing teaser-to-article similarity (doc2vec embeddings) improved performance
Connections¶
- Clickbait — core task of automated clickbait detection
- Shared tasks and benchmarks — benchmark for standardized evaluation
- We used Neural Networks to Detect Clickbaits: You won't believe what happened Next! — prior neural approach to clickbait detection; this challenge uses graded annotation instead of binary
- Text classification — headline/teaser classification methods
- Neural networks — deep learning approaches dominate best submissions
- Misinformation and fake news detection — clickbait often accompanies false or misleading information
Notes¶
The shift from binary to graded annotation is well-motivated and reflects linguistic reality—many messages are ambiguously clickbaiting. The Webis corpus is high-quality: crowdsourcing agreement matches expert annotation on prior smaller corpus.
The challenge's use of TIRA for reproducible deployment (participants submit executables on VMs) sets a strong standard; test data remains private, preventing overfitting and allowing reevaluation on future data.
Top approaches (zingel, carpetshark) achieved >45% error reduction compared to weak baseline (predicting average). The 0.45 NMSE for best system shows room for improvement, suggesting clickbait strength is genuinely difficult to predict—likely because human annotators themselves show moderate disagreement.
Dataset includes two classes of valuable metadata: full article archives (WARC) and platform/behavioral signals (timestamps, publishers), enabling future work on content-agnostic or temporal aspects of clickbait.