We used Neural Networks to Detect Clickbaits: You won't believe what happened Next!¶
Authors: Ankesh Anand, Tanmoy Chakraborty, Noseong Park Venue: arXiv:1612.01340 — arXiv
TL;DR¶
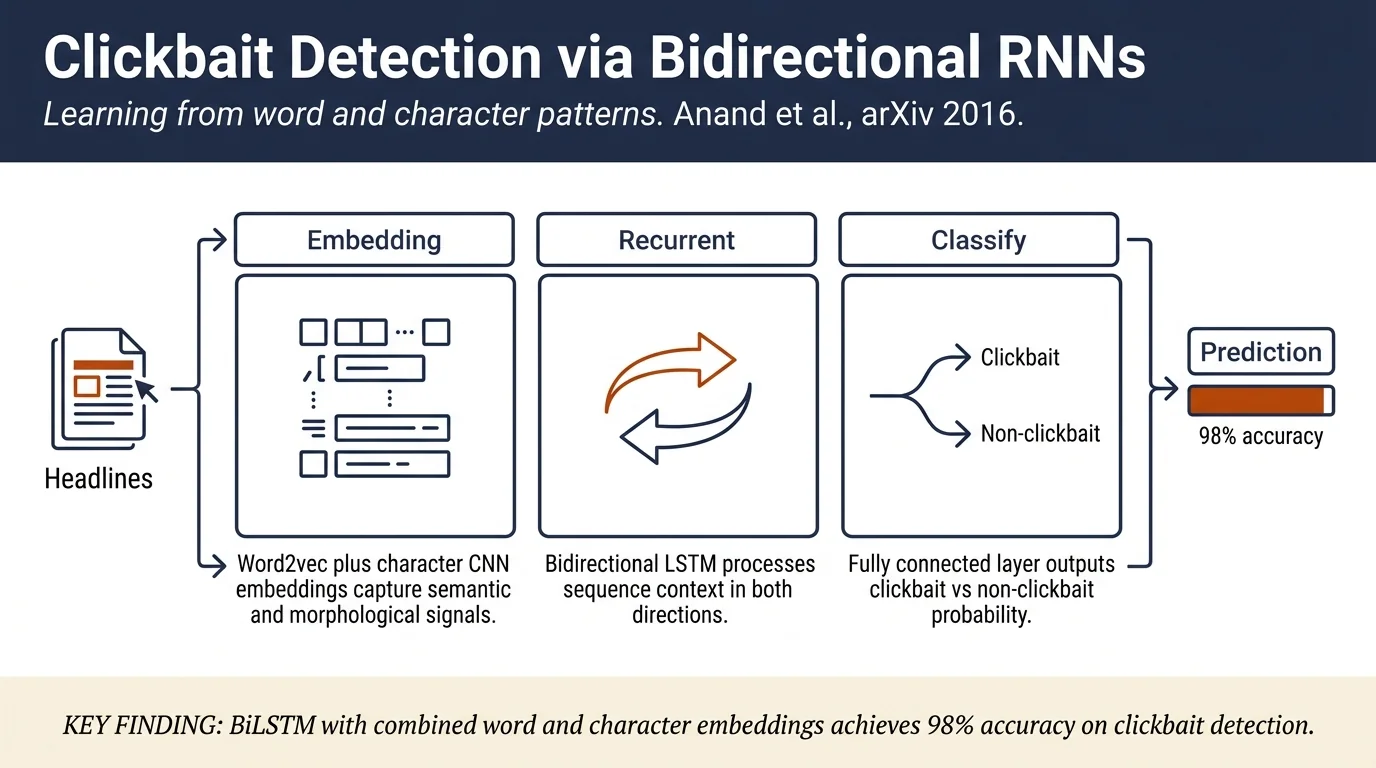
Clickbaits exploit curiosity gaps to drive clicks on disappointing content. This paper proposes bidirectional RNNs with distributed word embeddings and character-level embeddings for clickbait detection, achieving 98% accuracy on a 15,000-headline dataset — a 5% improvement over hand-crafted feature baselines.
Contributions¶
- Novel neural network architecture combining word and character embeddings for clickbait detection
- Comparison of RNN variants (standard RNN, LSTM, GRU) in bidirectional setting
- Empirical evaluation on a balanced 15,000-headline dataset with state-of-the-art results
- Demonstration that deep learning eliminates the need for heavy feature engineering in this task
Method¶
The model uses a bidirectional RNN architecture with three main components:
Embedding Layer: Each input word is embedded as a concatenation of (1) pre-trained 300-dimensional word2vec embeddings from Google News and (2) character-level embeddings learned via a 3-layer 1D CNN with ReLU activations and max-pooling. Character embeddings capture orthographic and morphological features while handling out-of-vocabulary words.
Hidden Layer: A bidirectional RNN processes the embedded sequence in both directions to capture contextual information. The paper evaluates three RNN architectures: standard RNNs, LSTMs (which use gating to preserve long-range dependencies), and GRUs (a simpler gated variant). The final hidden state becomes a fixed-size representation.
Output Layer: The RNN representation passes through a fully connected network with a sigmoid output node for binary classification (clickbait vs. non-clickbait).
The model is trained with mini-batch gradient descent (batch size 64), ADAM optimizer, binary cross-entropy loss, and dropout (rate 0.3) for regularization.
Results¶
On a balanced dataset of 15,000 headlines (7,500 clickbait from BuzzFeed/Upworthy/ViralNova, 7,500 non-clickbait from Wikinews):
| Model | Accuracy | Precision | Recall | F1 | ROC-AUC |
|---|---|---|---|---|---|
| BiLSTM (CE+WE) | 0.98 | 0.98 | 0.98 | 0.98 | 0.99 |
| Chakraborty et al. (SVM) | 0.93 | 0.95 | 0.90 | 0.93 | 0.97 |
The bidirectional LSTM with combined embeddings outperforms all baselines, achieving >5% accuracy improvement and >2% ROC-AUC improvement over the state-of-the-art SVM model.
Connections¶
- Clickbait — directly addresses clickbait detection via neural networks
- Deep learning — deep neural network methods applied to text classification
- Recurrent Neural Networks — employs bidirectional LSTM and GRU architectures
- Text classification — headline classification task
Notes¶
This paper demonstrates the effectiveness of deep learning over feature engineering for clickbait detection. The use of both word and character embeddings is well-motivated: word embeddings capture semantic content while character embeddings handle morphological cues that signal clickbait (e.g., excessive punctuation, capitalization patterns). The evaluation via 10-fold cross-validation is rigorous, though limited to English headlines. The paper promises to open-source the model weights for reproducibility, though this is now standard practice.