In Ictu Oculi: Exposing AI Generated Fake Face Videos by Detecting Eye Blinking¶
Authors: Yuezun Li, Ming-Ching Chang, Siwei Lyu Affiliation: Computer Science Department, University at Albany, SUNY Publication: arXiv preprint, 2018 — arXiv
TL;DR¶
Detects DeepFake videos by exploiting the absence of natural eye blinking patterns in AI-generated faces. Uses a Long-term Recurrent Convolutional Network (LRCN) combining CNN for feature extraction with LSTM-RNN for temporal modeling of eye state, achieving 0.99 AUC on authentic vs. synthesized videos—a forensic signal invisible to the naked eye but learnable by neural networks.
Contributions¶
- Novel physiological forensic signal: Identifies eye blinking as a reliable cue absent in synthesized faces because training datasets rarely contain images of closed eyes.
- LRCN architecture for eye blinking detection: Extends CNN-based eye-state classification with LSTM to capture temporal dependencies, improving accuracy (0.99 AUC) over frame-level CNN (0.98) and hand-crafted Eye Aspect Ratio baselines (0.79).
- Benchmark dataset: Introduces Eye Blinking Video (EBV) dataset of 50 videos (~30 seconds each) with frame-level annotation of left and right eye states.
- DeepFake detection evaluation: Demonstrates method on 49 synthetic face videos generated with the DeepFake algorithm, showing clear separation between authentic and fake videos.
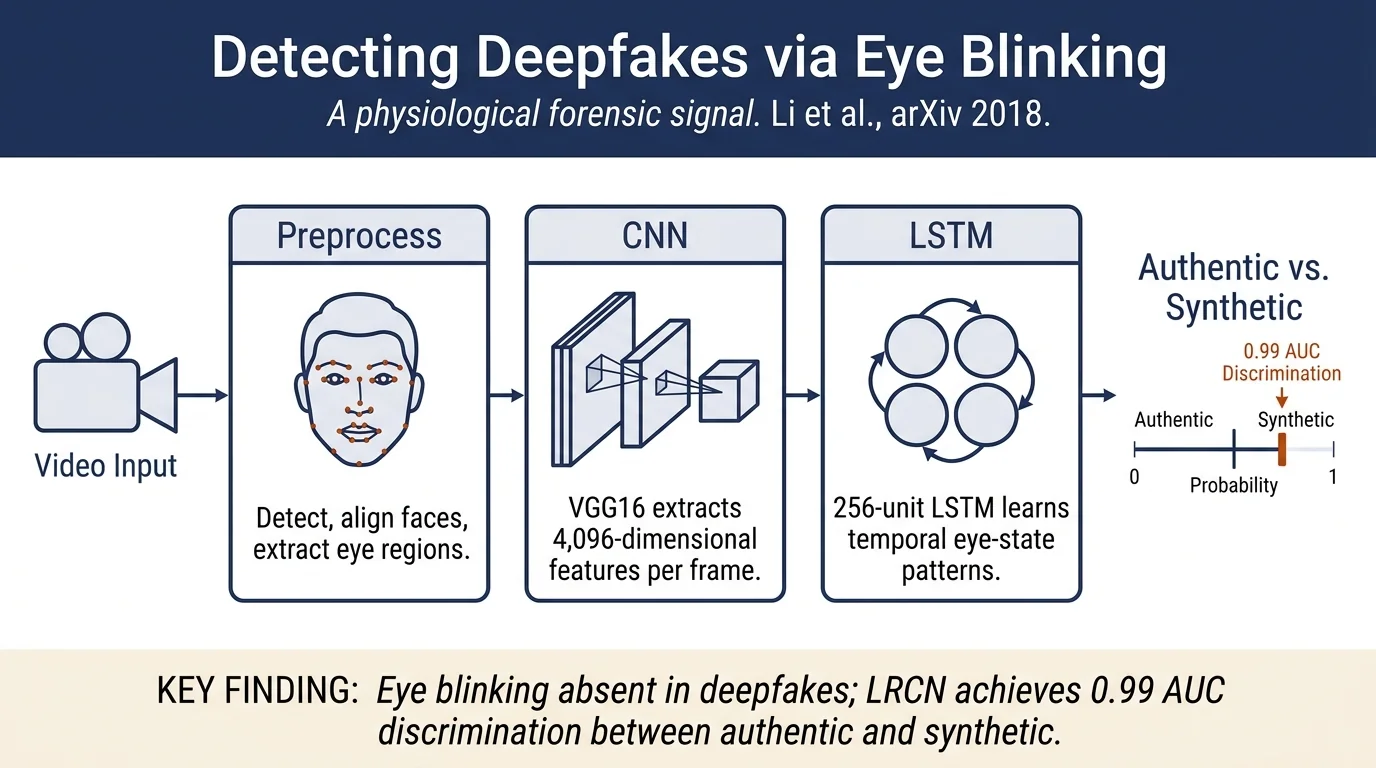
Method¶
Preprocessing: 1. Face detection and alignment via facial landmarks 2. Face alignment to normalized coordinate space 3. Eye region extraction (1.25–1.75× expansion of eye bounding boxes to ensure stable crop)
LRCN Model: The method combines three stages:
-
Feature Extraction: VGG16 CNN (conv1–5 blocks with max-pooling, fc6 layer) processes each eye region frame independently, producing 4,096-dimensional feature vectors.
-
Sequence Learning: LSTM-RNN with 256 hidden units processes the feature sequence, learning temporal dependencies via equations:
- Forget gate (controls memory discard): \(f_t = \sigma(W_{fh}h_{t-1} + W_{fx}x_t + b_f)\)
- Input gate (controls input pass): \(i_t = \sigma(W_{ih}h_{t-1} + W_{ix}x_t + b_i)\)
- Cell state: \(C_t = f_t \odot C_{t-1} + i_t \odot \tanh(W_{ch}h_{t-1} + W_{cx}x_t + b_c)\)
- Output gate: \(o_t = \sigma(W_{oh}h_{t-1} + W_{ox}x_t + b_o)\)
-
Hidden state: \(h_t = o_t \odot \tanh(C_t)\)
-
State Prediction: Fully connected layer outputs binary probability (eye open/closed).
Training: - Stage 1: Train VGG16 on CEW dataset (1,193 closed + 1,232 open eye images) with dropout (p=0.5) and stochastic gradient descent. - Stage 2: Joint LSTM+FC training on Eye Blinking Video dataset (40 videos train, 10 test) with BPTT, using ADAM optimizer, cross-entropy loss.
Results¶
Eye Blinking Detection Accuracy: - LRCN: 0.99 AUC (best) - CNN: 0.98 AUC - EAR (hand-crafted): 0.79 AUC
Key observation from ROC curves: LRCN's advantage over CNN stems from temporal smoothing—at frames with ambiguous eye state (e.g., small eye region), the LSTM leverages history to make correct predictions. CNN struggles when eye regions are small or contain motion artifacts; LRCN recovers by remembering whether a blink was underway.
Qualitative analysis: On Trump video examples, CNN shows noisy predictions even in steady-state regions (many false positive "open" detections). LRCN produces smooth, physiologically plausible blink sequences (single blink event = 4–6 consecutive closed frames at ~30fps).
DeepFake detection: Authentic videos show eye blinks within 5–6 seconds; DeepFake videos show no blinks in comparable duration—a conspicuous absence that violates the physiological expectation of ~17 blinks/min (0.283 blinks/sec).
Connections¶
- Related to Yang et al. (2018) via shared forensic approach of exploiting geometric inconsistencies in deepfake synthesis pipeline.
- Cited by Rana et al. (2022) as pioneering physiological-signal-based deepfake detection approach.
- Complements FaceForensics++ benchmark by introducing temporal behavioral cue separate from visual/noise-based detection.
- Related to deepfake detection topic and physiological forensics research direction.
Notes¶
Strengths: - Simple, interpretable forensic signal grounded in physiology rather than learned representations. - LRCN improvement over CNN clearly demonstrates value of temporal modeling for video forensics. - Dataset and method accessible for follow-on research.
Limitations: - Eye blinking may be easier for future deepfake generators to synthetically add post-hoc than other cues (acknowledged by authors). - Evaluation limited to single deepfake tool (DeepFake) and custom 50-video dataset; modern face-swap methods and larger benchmarks would strengthen claims. - Frame-rate dependent (assumes 25–30 fps); compression or rescaling could degrade eye region quality. - Assumes frontal face orientation for landmark-based eye extraction; side profiles would require extension.
Future directions (authors): 1. Explore other physiological signals (breathing, pulse). 2. Model dynamic blink patterns (e.g., physiologically implausible blinking rate) rather than just presence/absence. 3. Harden against post-processing synthesis techniques that may add blinking artifacts.