A Deep Learning Approach for Multimodal Deception Detection¶
Authors: Gangeshwar Krishnamurthy, Navonil Majumder, Soujanya Poria, Erik Cambria Venue: arXiv, 2018 — arXiv:1803.00344
TL;DR¶
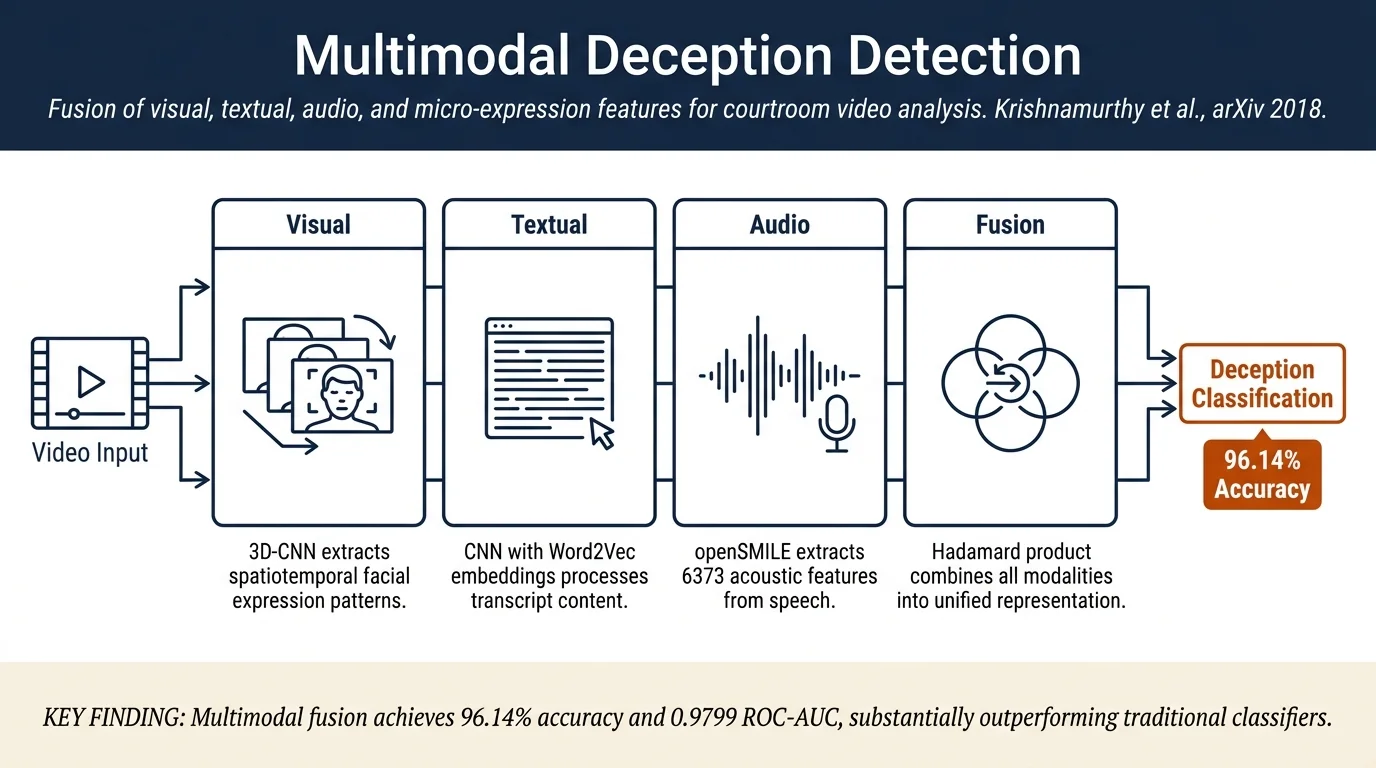
This paper proposes a multimodal neural model for detecting deception in real-life courtroom trial videos by combining visual features from 3D-CNN, audio features from openSMILE, textual features from CNN on transcripts, and manual micro-expression annotations. The model achieves 96.14% accuracy and ROC-AUC of 0.9799, substantially outperforming prior work using traditional classifiers on feature engineering-based approaches.
Contributions¶
- First neural network approach to deception classification using multimodal features
- Systematic evaluation of feature fusion strategies: simple concatenation vs. Hadamard product + concatenation
- Demonstration that visual and textual features are most important for deception detection, followed by micro-expressions and audio
- Strong empirical results on real-world courtroom trial data, outperforming baselines by significant margins
Method¶
Feature Extraction: The model extracts four types of features from each video:
-
Visual features: 3D-CNN (32 feature maps, 5×5×5 filters) applied to RGB video frames to capture spatiotemporal patterns including facial expressions (smile, fear, stress). Output: 300-dim vector.
-
Textual features: Pre-trained Word2Vec embeddings of transcript words fed to CNN with filters of size 3, 5, 8 (20 feature maps each), max-pooling window size 2, then fully connected layer with 300 neurons. Output: 300-dim vector.
-
Audio features: openSMILE toolkit (IS13-ComParE configuration) extracts 6373-dim features; background noise removed via SoX, then dimensionality reduced to 300 via fully-connected network. Output: 300-dim vector.
-
Micro-expression features: 39 binary features (frowning, smiling, eyebrows raising, etc.) from manual annotations. Output: 39-dim vector.
Fusion and Classification: Two model variants are compared:
- MLPC (Concatenation): Features concatenated to 939-dim vector → MLP with 1024-unit hidden layer (ReLU, dropout p=0.5) → softmax output.
- MLPH+C (Hadamard + Concatenation): Audio ⊙ Visual ⊙ Textual (Hadamard product) concatenated with micro-expression features → 339-dim vector → same MLP architecture.
Loss is cross-entropy with SGD optimization.
Results¶
AUC-ROC (Table 1): - MLPU (unimodal): Visual 0.9596, Textual 0.9455, Audio 0.5231, Micro-Expression 0.7512 - MLPC (all static features): 0.9033 - MLPH+C (all non-static): 0.9799 — substantially outperforms Linear SVM (0.9065) and Logistic Regression (0.9221) baselines
Accuracy (Table 2): - MLPU (unimodal): Visual 93.08%, Textual 90.24%, Audio 52.38%, Micro-Expression 76.19% - MLPC (static): 90.49% - MLPH+C (non-static): 96.14% — outperforms Decision Trees (75.20%) and Random Forests (50.41%) from Pérez-Rosas et al. [14]
Findings confirm that visual and textual features are dominant; micro-expressions and audio provide secondary signals.
Dataset and Evaluation¶
Uses 121 real-life courtroom trial video clips (61 deceptive, 60 truthful) from Pérez-Rosas et al. (2015). To prevent personality leakage between train/test, employs 10-fold cross-validation stratified by subject (not by video), following Wu et al. (2017).
Connections¶
- Related to EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection via multimodal fusion for media-integrity tasks, though EANN focuses on fake news images while this focuses on video deception cues.
- Uses 3D-CNN similar to approaches in In Ictu Oculi: Exposing AI Generated Fake Face Videos by Detecting Eye Blinking for facial analysis.
- Textual analysis parallels Linguistic style detection topic work.
- Connects to broader Deception Detection literature on behavioral cues and non-verbal communication.
Notes¶
Strengths: - Strong empirical results substantially beating baselines on a real-world task - Systematic ablation showing relative importance of each modality - Clear technical exposition of feature extraction and fusion - First deep learning approach to this specific problem
Weaknesses: - Small dataset (121 videos) raises overfitting concerns despite dropout regularization; authors acknowledge this - Limited to courtroom setting; unclear how well the approach generalizes to other deceptive scenarios or online contexts (e.g., social media) - Micro-expression features require manual annotation, limiting scalability - Paper motivates fake news applications in introduction but evaluation is on offline trials, not online content
Broader relevance: While the paper mentions fake news and social media deception as motivation, the actual methodology is specialized to courtroom trial videos. The techniques could potentially be adapted for detecting deceptive claims in video or broadcast content, but direct application to written misinformation or synthetic media detection would require substantial modification. The work is most directly relevant as a methodological reference for video-based deception cues and multimodal fusion strategies.