Topological Recurrent Neural Network for Diffusion Prediction¶
Authors: Jia Wang, Vincent W. Zheng, Zemin Liu, Kevin Chen-Chuan Chang
Venue: ICDM 2017
ArXiv: 1711.10162
TL;DR¶
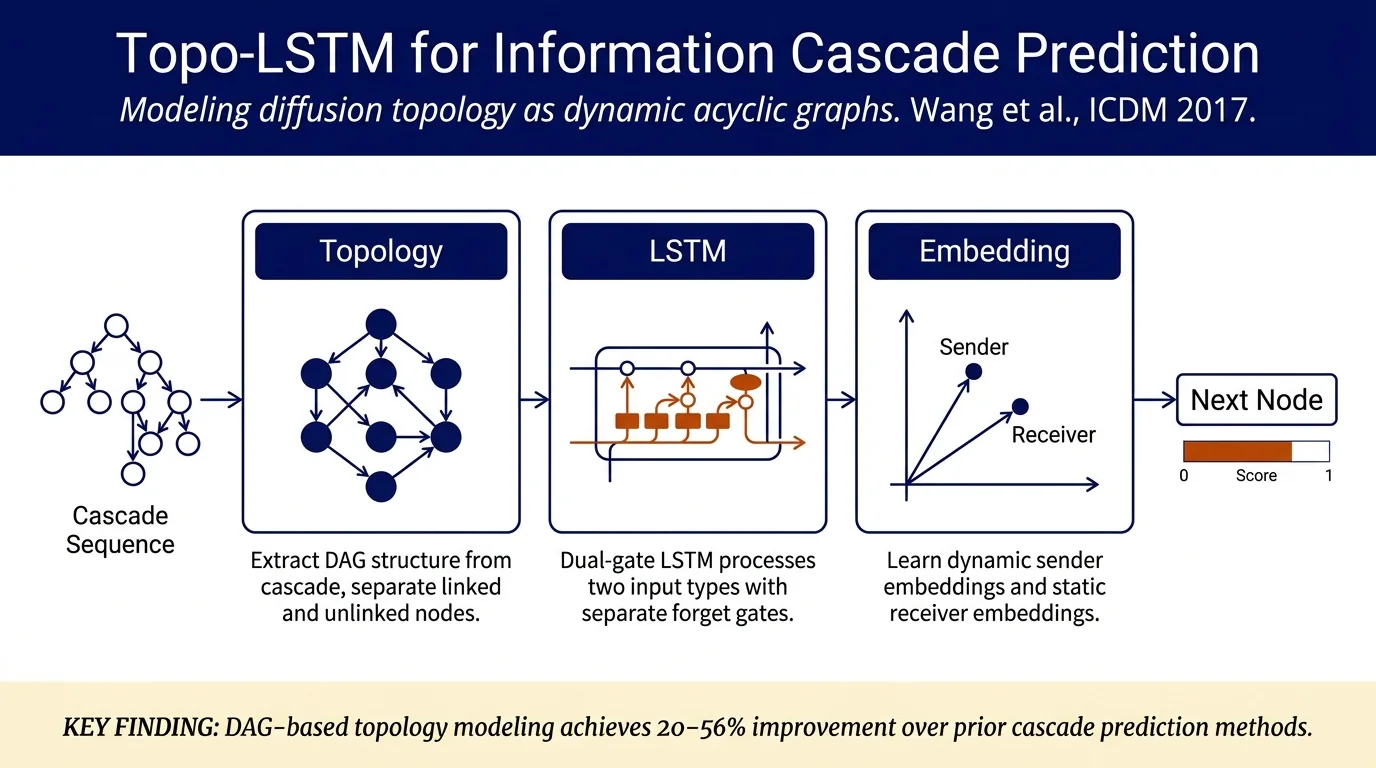
Wang et al. propose Topo-LSTM, a novel LSTM architecture for modeling dynamic directed acyclic graphs (DAGs) to predict which node will be activated next in information cascades. The key insight is that information diffusion on networks should be modeled explicitly as diffusion topologies—graphs showing how information spreads from already-active to inactive nodes—rather than as simple node sequences. Topo-LSTM extends LSTM with separate gates for handling two types of inputs (directly-linked vs. non-linked active nodes) and learns topology-aware sender embeddings that encode both node properties and cascade dynamics, achieving 20.1%–56.6% relative improvement in Mean Average Precision over prior methods (DeepCas, Embedded-IC) across three real-world networks (Digg, Twitter, Memes).
Contributions¶
- Introduces diffusion topology as a data model—a directed acyclic graph characterizing a cascade's structure at each time step, showing which active nodes can attempt to activate which inactive nodes over the underlying network.
- Proposes Topo-LSTM, the first LSTM designed to handle dynamic DAG inputs by:
- Separating two types of inputs: active nodes directly linked to the target vs. non-linked active nodes
- Introducing separate forget gates for each input type
- Aggregating multiple inputs of each type via mean pooling
- Learning dynamic sender embeddings (aware of cascade history) and static receiver embeddings
- Demonstrates that explicit modeling of cascade topology outperforms prior approaches that either treat cascades as independent node sets (Embedded-IC) or decompose them into random walk paths (DeepCas).
Method¶
Problem formulation: Given a data graph G = (V, E) and a cascade sequence {(v₁, 1), ..., (vₜ, t)}, predict which inactive node will be activated next. Learn sender embedding hₜ for each active node vₜ (encoding the node and cascade dynamics up to time t) and receiver embedding gⱼ for each inactive node vⱼ (encoding its static preference).
Diffusion topology: Formally defined as Gₜ = (V, Eₜ) where E*ₜ contains all edges (vᵢ, u) ∈ E where vᵢ is already active and u is either inactive or activated after vᵢ. Two properties hold: (1) each topology is a DAG, and (2) topologies grow monotonically over time.
Topo-LSTM architecture: Core changes from standard LSTM: 1. Aggregates sender embeddings from two input types: h'(p)ₜ aggregates embeddings of precedent nodes (directly linked), h'(q)ₜ aggregates other already-activated nodes. Uses mean pooling aggregation function φ(·). 2. Input gate: iₜ = σ(Wᵢxₜ + U(p)ᵢh'(p)ₜ + U(q)ᵢh'(q)ₜ + bᵢ) 3. Two forget gates: f(p)ₜ and f(q)ₜ control information flow from each input type separately 4. Cell state: cₜ = ĩₜ ⊙ c̃ₜ + f(p)ₜ ⊙ c'(p)ₜ + f(q)ₜ ⊙ c'(q)ₜ 5. Output: hₜ = oₜ ⊙ tanh(cₜ)
Activation prediction: Predicts score for node v as ρᵥ,ₜ₊₁ = φ({hᵢ | vᵢ ∈ Pᵥ,ₜ₊₁}) · gᵥ + bᵥ, where Pᵥ,ₜ₊₁ is v's precedent set. Extended to account for nodes that activate despite lacking edges by including all active nodes: ρᵥ,ₜ₊₁ = φ({hᵢ | vᵢ ∈ Q₁:ₜ}) · gᵥ + bᵥ.
Results¶
Datasets: Digg (279K nodes, 2.6M edges, 3,553 cascades, avg. length 30), Twitter (137K nodes, 3.6M edges, 569 cascades, avg. length 5.7), Memes (5K nodes, 314K edges, 54,847 cascades, avg. length 17).
Evaluation metrics: Hits@k (fraction of top-k predictions containing the true next node) and MAP@k (Mean Average Precision).
Comparisons with baselines: - IC-SB (static diffusion probability learned via Independent Cascade) - Embedded-IC (static node embeddings in diffusion space) - DeepCas (random walk paths + GRU + attention) - DeepWalk (node embeddings without cascade info)
Performance: | Dataset | Metric | Topo-LSTM | Best Baseline | Relative Gain | |---------|--------|-----------|---------------|--------------| | Digg | MAP@10 | 5.862 | 3.743 (DeepCas) | +56.6% | | Twitter | MAP@10 | 20.548 | 17.039 (DeepCas) | +20.6% | | Memes | MAP@10 | 29.000 | 19.564 (DeepCas) | +48.4% | | Digg | Hits@10 | 15.410 | 10.269 (DeepCas) | +50.1% | | Memes | Hits@100 | 76.850 | 74.868 (DeepCas) | +2.7% |
Hyperparameter sensitivity: Embedding dimension d = 512 achieves convergence on Twitter (d = 256) but shows continued improvement on Digg and Memes, indicating the model is not saturated on larger datasets.
Cascade length sensitivity: Prediction accuracy decreases as cascade length increases on Digg and Memes (intuitive: longer cascades = more uncertainty), but shows no trend on Twitter (higher variation in propagation paths).
Connections¶
- Li et al. — DeepCas — Prior deep learning approach to cascade prediction using random walk decomposition; Topo-LSTM's key advantage is explicit modeling of full topology rather than path sampling
- Cascade Prediction — Core application domain for this work; contributes explicit topology modeling to the field
- Information diffusion in social networks — Theoretical foundation; this work operationalizes cascade dynamics via DAG structure
- Graph Neural Networks — Topo-LSTM extends GNN concepts to dynamic DAGs; related to broader literature on DAG-RNNs and graph-structured neural networks
- Cheng et al. — Predicting cascade growth from early observations — Earlier work establishing cascade predictability; this work advances prediction via deep learning
- Shu et al. — Hierarchical propagation networks — Contemporaneous work on structural propagation models
Notes¶
Strengths:
- Novel architecture elegantly handles the unique constraints of diffusion topologies (DAG structure, dynamic growth, two input types)
- Clear motivation: diffusion topologies are an underexplored but natural data representation for cascade modeling
- Comprehensive experimental evaluation across three networks with different scales and dynamics
- Significant empirical improvements (20–56%) over strong baselines
- Model is relatively simple with few hyperparameters (embedding dimension, regularization parameter), making it practical to tune
Weaknesses:
- Limited theoretical analysis of why Topo-LSTM should outperform alternatives; improvements could be partly attributable to the richer topology representation rather than the RNN architecture itself
- Only evaluated on information diffusion tasks; generalizability to other DAG-structured sequence prediction tasks (e.g., program synthesis, molecular generation) is unclear
- Does not incorporate cascade content (text, images) or user features—modeling these as future work; this limits applicability to real-world misinformation scenarios where content is highly predictive
- Cascade length sensitivity (worse performance on longer cascades) limits utility in predicting growth of mature diffusions; most valuable for short-term prediction
- Comparison to DeepCas somewhat limited by their experimental setup (different embedding dimensions, different hyperparameter tuning regimes); direct implementation comparison would strengthen claims
Open questions:
- How does Topo-LSTM scale to very large networks (millions of nodes) where computing all pairwise potential edges becomes expensive?
- Does the model capture the types of diffusion dynamics that are relevant to misinformation specifically (e.g., coordinated inauthentic behavior, bot amplification)?
- Can the learned representations be interpreted to understand why certain users are influential in certain cascade contexts?