DeepCas: an End-to-end Predictor of Information Cascades¶
Authors: Cheng Li, Jiaqi Ma, Xiaoxiao Guo, Qiaozhu Mei
Institution: University of Michigan
Venue: arXiv — 1611.05373
TL;DR¶
DeepCas predicts the future size of information cascades (e.g., how many people will eventually retweet a post or cite a paper) using an end-to-end deep learning model that represents cascade graphs as sets of random walk paths. Instead of relying on hand-crafted network features, the model learns cascade representations automatically through a GRU network with attention, achieving significantly better prediction accuracy than feature-based and graph kernel baselines on both Twitter and citation cascades.
Contributions¶
- First end-to-end deep learning approach for cascade size prediction that avoids hand-crafted feature engineering
- Novel cascade graph representation as random walk paths, analogous to treating documents as collections of sentences
- Automatic learning of random walk path counts and lengths via attention mechanism (previously fixed hyperparameters in DeepWalk)
- Empirical demonstration that cascade graph-level representations outperform node embedding approaches
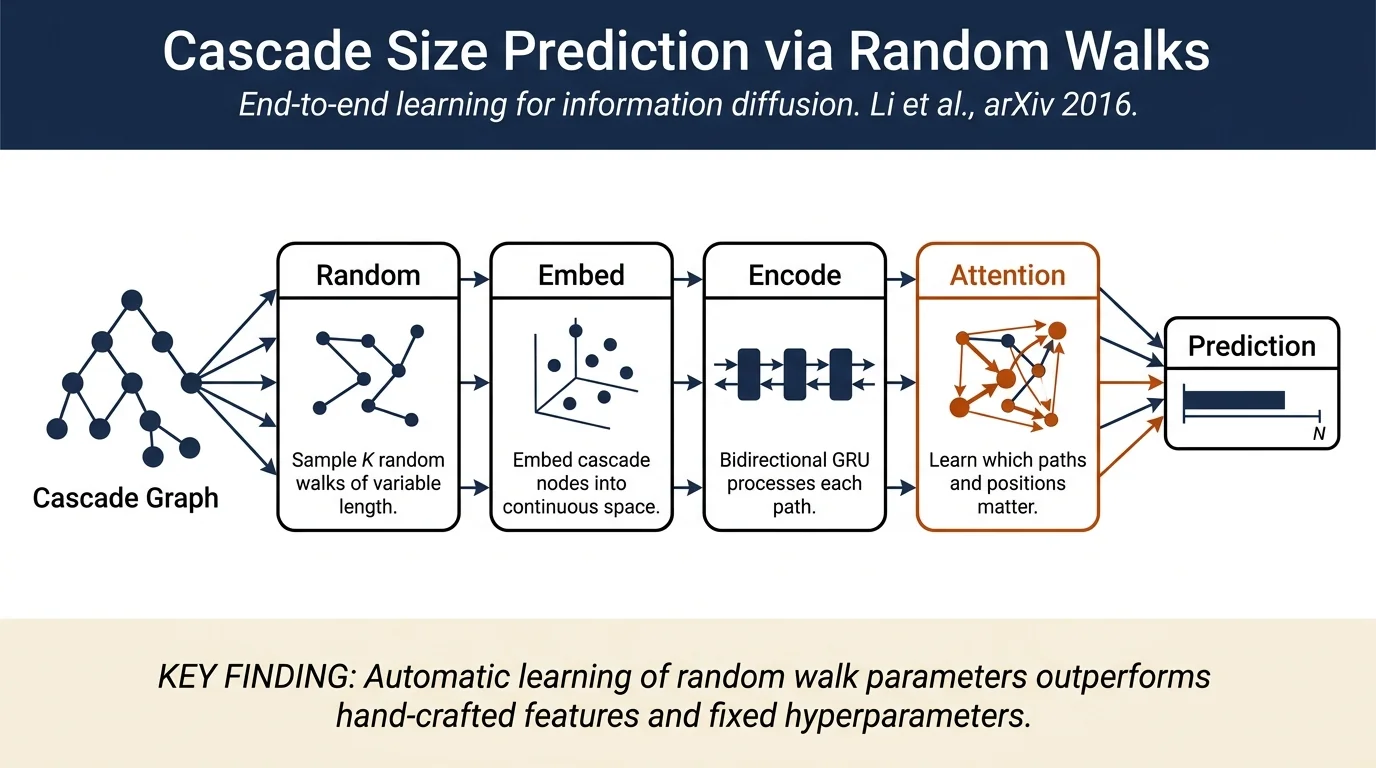
Method¶
The core insight is that a cascade graph (who adopted information and their network relationships) can be represented as a set of random walk paths. This preserves both node identities and structural information while enabling the use of sequence models.
Architecture pipeline:
-
Random walk sampling: Generate K paths of length T from the cascade graph using a Markov chain with transitions based on node degree (in cascade or global network) or edge weights. The authors learn optimal parameters (how many paths, how long) rather than fixing them.
-
Node embedding: Each node is embedded into a continuous vector space using a shared embedding matrix.
-
Sequence encoding: Bidirectional GRU processes each sampled path, producing forward and backward hidden states that are concatenated.
-
Graph representation via attention: The model learns to assemble K variable-length sequences into a single graph representation. Two attention mechanisms:
- Geometric distribution over mini-batches of sequences (learns how many sequences to use; conditioned on cascade size)
-
Multinomial distribution over node positions within sequences (learns which positions matter)
-
Output prediction: A multi-layer perceptron predicts the cascade size increment (log-transformed).
The key innovation is the attention mechanism, which automatically decides the effective number and length of random walk paths for each cascade, analogous to learning how many sentences and how long each sentence should be per document.
Results¶
Datasets: - Twitter: 25K–35K cascades per configuration; retweet chains from June 2016 Decahose API; 354K users, 28M edges - AMINER: 3K–35K cascades; citation cascades from DBLP (1992–2007 citations; papers 2003–2009); 131K authors, 843K edges
Metrics: Mean squared error on log-transformed cascade increment (log₂(Δs + 1))
Baselines: Features-linear, Features-deep (MLP on hand-crafted features), OSLOR, Node2Vec, Embedded-IC, PSCN, WL-degree, WL-id
Key findings: - DeepCas variants (DeepCas-edge, DeepCas-deg, DeepCas-DEG) consistently outperform all baselines across both datasets and all time configurations - On Twitter 1-day prediction: DeepCas achieves MSE ~1.48–1.49 vs. Features-deep 1.644 and Node2Vec 1.759 - Variants of DeepCas (GRU-bag, GRU-fixed, GRU-root) degrade performance, confirming importance of: (1) path-based representation over node bags, (2) learned vs. fixed path counts/lengths, (3) random jumps vs. root-only sampling - Larger, denser graphs benefit more from deep learning; simple features work better for sparse cascades
Connections¶
- Related to Cascade Prediction via shared regression objective; extends Cheng 2014 Cascades Predicted which used hand-crafted features
- Builds on Deepwalk and node embedding methods but applies them at the graph (cascade) level rather than node level
- Part of broader trend toward Graph Neural Networks for social network analysis
- Addresses misinformation spread prediction in Information diffusion in social networks contexts
Notes¶
Strengths: - Clear motivation: eliminating arbitrary feature design is compelling for social network analysis where domain knowledge is rich but feature choices often appear "magical" - Strong empirical results across two distinct domains (Twitter vs. academic citations) - Careful ablation studies (GRU-bag, GRU-fixed, GRU-root) validate each architectural choice - Interpretability analysis (Figure 4) shows learned representations align with known network properties (triangles, communities, degree) without explicit instruction
Weaknesses: - Representation uses only network structure; content and temporal features are excluded (though authors note content features are weaker predictors) - Static network assumption; real social networks evolve; the paper controls for cascade-induced edges but this is artificial - Limited to early-stage prediction settings; focus on predicting Δt hours/days/years after observation, not long-term popularity - No discussion of computational cost beyond training time; inference-time complexity unclear - The geometric attention parameterization (conditioned on log₂(cascade size)) feels ad hoc; unclear if this is the right conditioning
Future work: - Incorporating temporal and content signals when available - Learning multiple random walk strategies (contagion processes) rather than fixed transition rules - Extension to other cascade types (memes, videos, academic concepts)