A Survey on Hate Speech Detection using Natural Language Processing¶
Authors: Anna Schmidt, Michael Wiegand
Venue: Fifth International Workshop on Natural Language Processing for Social Media, 2017 — ACL Anthology
TL;DR¶
This survey systematically reviews automatic hate speech detection methods, covering feature extraction techniques (surface features, embeddings, sentiment analysis, lexical resources, linguistic features, knowledge bases), classification approaches (mostly supervised learning with SVMs and neural networks), annotation practices, and key challenges including the need for benchmark datasets and multilingual perspectives.
Contributions¶
- Comprehensive taxonomy of features used in hate speech detection systems
- Systematic review of classification methods (supervised learning, semi-supervised bootstrapping, multi-step approaches)
- Discussion of data annotation challenges and corpus collection practices
- Identification of key remaining challenges: lack of standardized definitions, limited non-English work, insufficient use of contextual features
Method¶
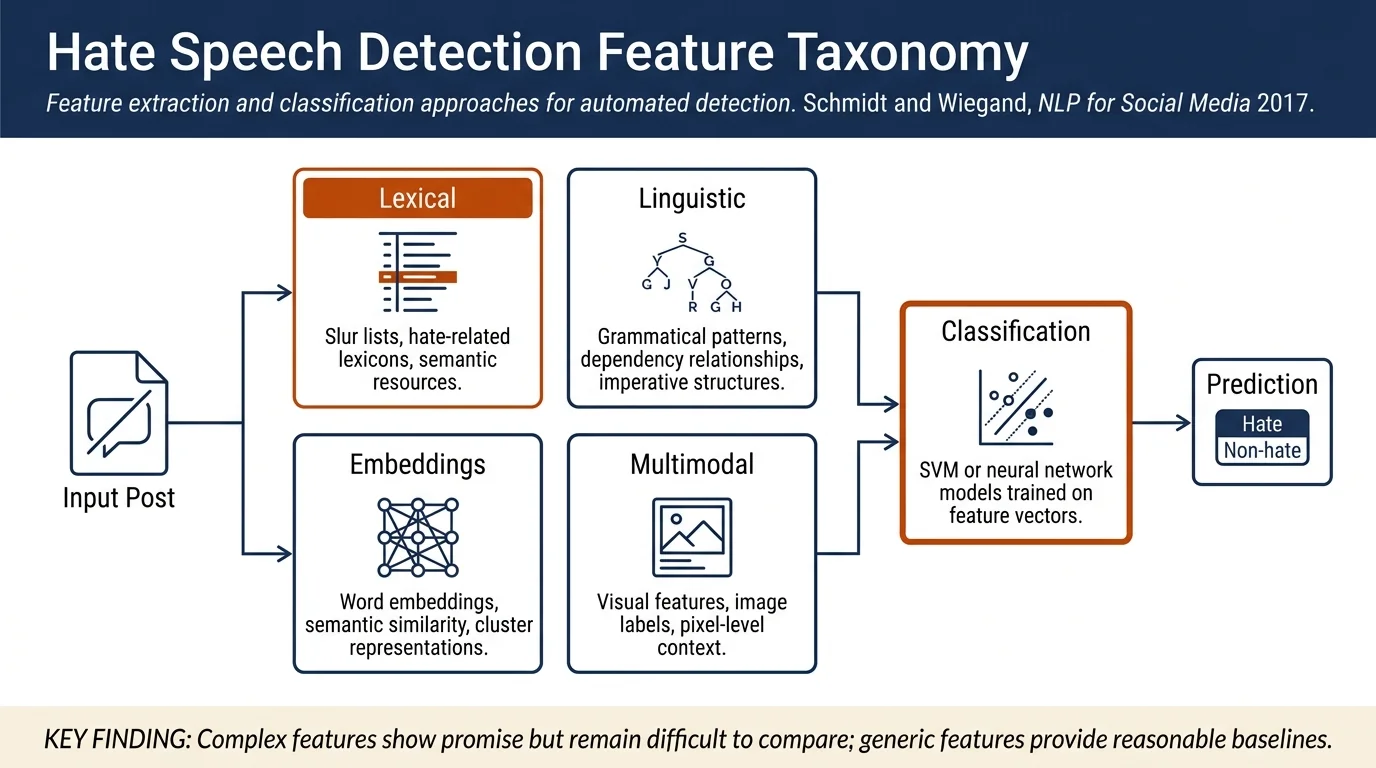
The survey organizes hate speech detection into eight feature categories:
Surface features: Character and token n-grams are highly predictive; character-level approaches better handle spelling variations common in social media.
Word generalization: Brown clustering, LDA, and word embeddings (including paragraph embeddings) help address data sparsity by representing semantic similarity.
Sentiment analysis: Hate speech often exhibits high negative polarity; classifiers detecting polarity intensity can help isolate hate speech from merely negative utterances.
Lexical resources: Slur lists and manually compiled hate-related lexicons improve performance but only when combined with other features; context matters significantly.
Linguistic features: Dependency relationships capturing long-distance syntactic connections between offensive terms and targets; imperative statements; politeness markers.
Knowledge-based features: ConceptNet-based approaches with stereotype knowledge (demonstrated for anti-LGBT hate) show promise but require extensive manual engineering per hate subtype.
Meta-information: User history, gender, post frequency, and reply counts; effectiveness varies by platform and account type.
Multimodal information: Image labels and pixel-level features when combined with captions; visual context often plays a major role in hateful posts.
Classification methods are predominantly supervised (SVMs most common), with emerging use of recurrent neural networks. Semi-supervised approaches like bootstrapping acquire additional training data or build lexicons iteratively.
Results¶
The survey does not report empirical numbers but synthesizes findings across 40+ papers. Key observations:
- Generic features (bag-of-words, embeddings) yield reasonable baseline performance
- Character-level approaches outperform token-level ones
- Complex features (linguistic, knowledge-based, multimodal) show promise but are difficult to compare across heterogeneous datasets
- No clear winner emerges for best classification method
Connections¶
- Related to Stance Detection as a related NLP task for understanding user positions
- Uses techniques from word embeddings and information extraction
- Connected to content moderation workflows and NLP methods more broadly
- Related to empirical hate speech detection papers that apply these methods
Notes¶
Strengths: - Well-structured taxonomy of features; helpful for researchers new to the field - Honest discussion of limitations: complex context cues (sarcasm, allusion, stereotype activation) remain difficult - Acknowledges the cost of annotation (data sparsity in hate speech) and platform-specific variations
Weaknesses: - Published in 2017; many cited works are from 2012–2015; limited coverage of deep learning (RNNs mentioned only briefly) - No empirical comparison across datasets/methods; conclusions about feature effectiveness are often weak - Limited discussion of bias in annotation and how annotator disagreement affects conclusions
Gaps: - Very limited work on non-English languages (only Dutch and German mentioned) - Insufficient exploration of contextual knowledge (though the paper identifies this need) - No discussion of real-time deployment challenges or platform-specific constraints
Impact: This survey is a canonical reference for hate speech detection methodology and would be cited by researchers building misinformation or harmful content detection systems that incorporate hate speech components. The feature taxonomy remains relevant for understanding NLP-based content moderation.