Efficient Estimation of Word Representations in Vector Space¶
Authors: Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean Venue: NIPS 2013 — arXiv
TL;DR¶
Proposes two efficient neural network architectures (CBOW and Skip-gram) for learning word embeddings from large corpora; achieves state-of-the-art word similarity performance while reducing training time by orders of magnitude compared to prior neural language models; word vectors capture syntactic and semantic regularities enabling simple vector arithmetic (e.g., king − man + woman ≈ queen).
Contributions¶
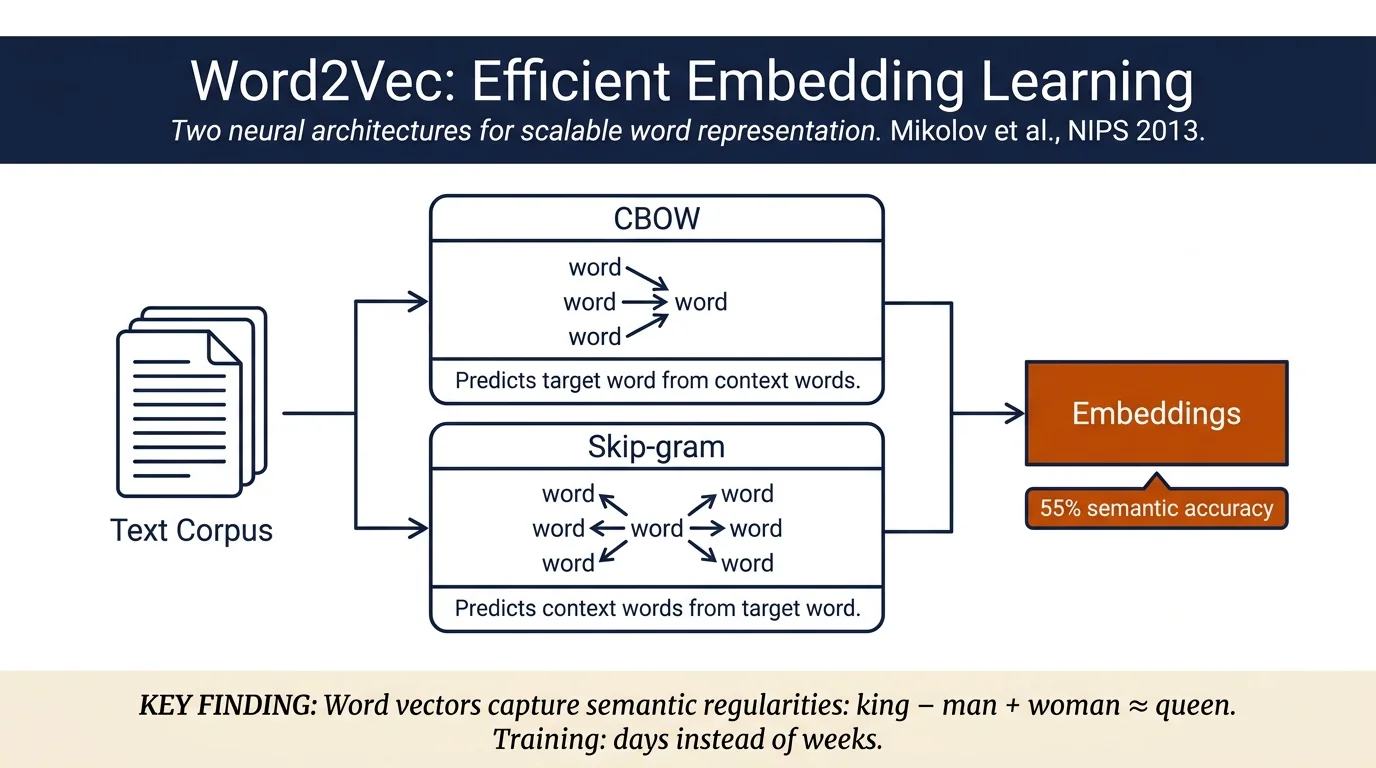
- Two novel model architectures for computing continuous word representations: CBOW (Continuous Bag-of-Words) and Skip-gram
- Comprehensive semantic-syntactic test set with 8,869 semantic and 10,675 syntactic questions for evaluating word vector quality
- Demonstration that high-quality word vectors can be trained from 1.6 billion words in less than a day
- Evidence that word vectors capture linguistic regularities amenable to vector arithmetic
Method¶
Continuous Bag-of-Words (CBOW). Projects context words to a fixed-size representation (shared for all word positions), then predicts the target word via a log-linear classifier. Training complexity: O(N × D + D × log₂(V)), where N is projection layer dimensionality, D is word vector dimensionality, and V is vocabulary size. Uses a projection layer with shared weights across context positions, drastically reducing computational cost compared to NNLM.
Continuous Skip-gram. Inverts the CBOW objective: given a word, predicts context words within a maximum distance C. Each context word is predicted independently using the same output projection. Training complexity: O(C × (D + D × log₂(V))). Less dependent on nearby words due to distance-based sampling.
Both architectures use a hierarchical softmax or negative sampling to avoid computing probabilities over the full vocabulary. The paper demonstrates that low-dimensional vectors (50–300 dimensions) trained on large data substantially outperform higher-dimensional vectors on word similarity tasks.
Results¶
Semantic-Syntactic Test Set Performance: - Skip-gram achieves 55% semantic accuracy and 59% syntactic accuracy on the full test set - CBOW achieves 24% semantic and 64% syntactic accuracy - Both substantially outperform existing NNLM (23% semantic, 53% syntactic)
Computational Efficiency: - Skip-gram trained on 783M words (full Google News data) reaches competitive results in a single epoch (0.6–2.5 days on a single CPU) - CBOW trained on 783M words reaches comparable accuracy in 1 day - Prior NNLM-based approaches required 8+ weeks on the same data
Vector Arithmetic: Words vectors exhibit linear structure supporting vector operations: - France − Paris + Berlin ≈ Germany - Einstein − scientist + Picasso ≈ painter - king − man + woman ≈ queen - Microsoft − Windows + Linux ≈ IBM (approximately)
Downstream Task Performance: - Microsoft Sentence Completion Challenge: Skip-gram + RNNLM ensemble achieves 58.9% accuracy, best published result at the time
Connections¶
- Forms the foundation of text embeddings used across NLP applications
- Extends earlier neural language modeling work (Bengio et al. 2003) with dramatic computational efficiency gains
- Used downstream in many fake news detection systems as input features via text classification pipelines
- Related to pre-trained language models as a static embedding baseline preceding contextual models like BERT
Notes¶
This foundational paper introduced efficient word embedding methods that have become essential infrastructure for NLP systems. The architectural innovations (removing the hidden layer, using hierarchical softmax) were crucial—prior neural language models were prohibitively expensive to train on large corpora. While later contextual embedding methods (BERT, GPT) address limitations of static embeddings, the word2vec architectures remain computationally efficient and widely used. The semantic-syntactic test set remains a standard benchmark for embedding quality, though limitations include inability to represent polysemy and out-of-vocabulary words. The paper's code availability and simplicity contributed significantly to its widespread adoption.