Turing at SemEval-2017 Task 8: Sequential Approach to Rumour Stance Classification with Branch-LSTM¶
Authors: Elena Kochkina, Maria Liakata, Isabelle Augenstein
Affiliation: University of Warwick, Alan Turing Institute, University College London
Venue: Proceedings of the 11th International Workshop on Semantic Evaluations (SemEval-2017), August 3–4, 2017
arXiv: 1704.07221
TL;DR¶
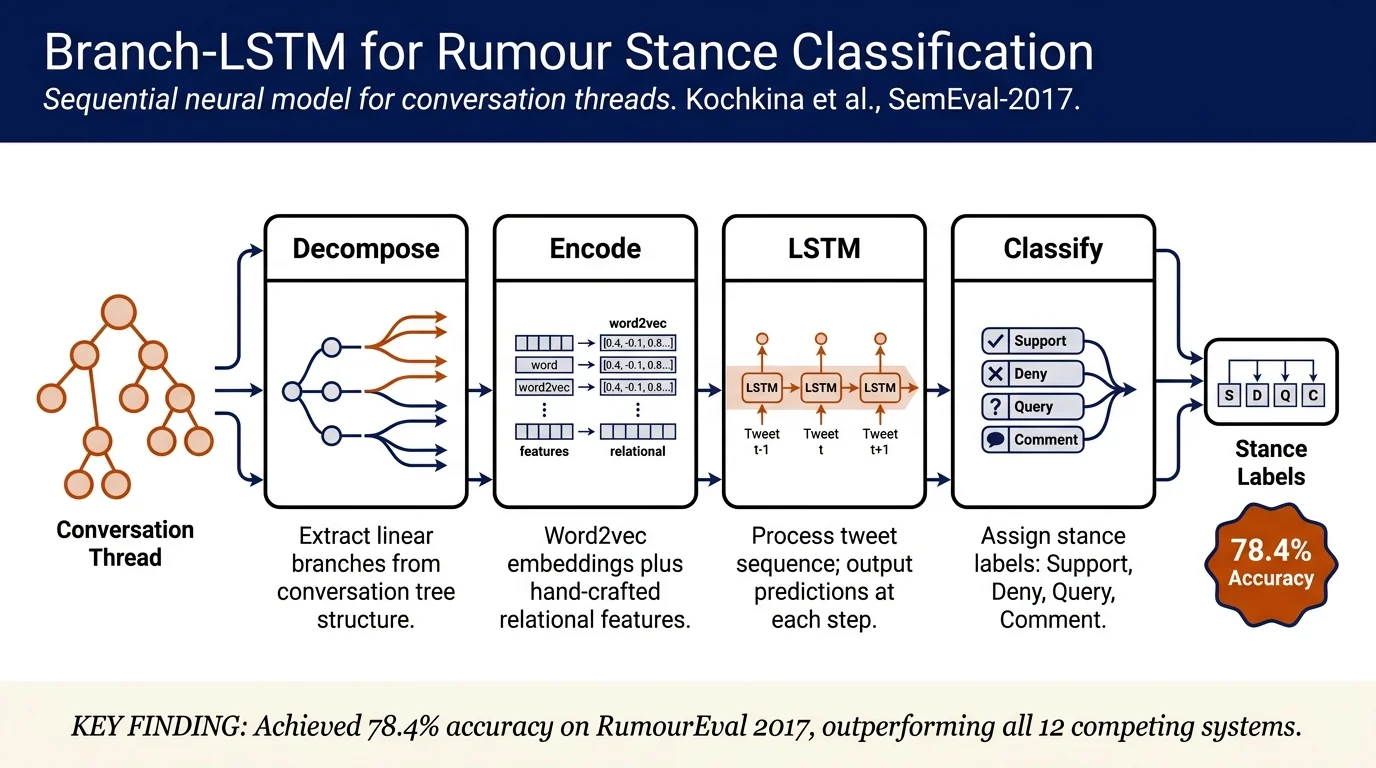
This paper proposes Branch-LSTM, a sequential neural model for rumour stance classification in Twitter conversations. By decomposing conversation threads into linear branches and modeling them with LSTM layers, the approach captures conversational context while assigning stance labels (Support/Deny/Query/Comment) to each tweet. The system achieved 78.4% accuracy on RumourEval 2017 Subtask A, outperforming all 12 competing systems.
Contributions¶
- Branch-LSTM architecture: A novel LSTM-based approach that decomposes tree-structured conversations into linear branches to exploit sequential structure
- State-of-the-art performance: Achieves 78.4% accuracy on RumourEval 2017 test set, setting the best results in Subtask A
- Feature engineering: Combines word2vec embeddings with hand-crafted lexical, syntactic, and relational features (negation counts, punctuation, URL presence, similarity to source/preceding tweets)
- Systematic analysis: Detailed error analysis showing strengths on majority classes (commenting: 87.3% F-score) and challenges with imbalanced classes (denying: 0% F-score)
Method¶
Architecture¶
The branch-LSTM processes tweet sequences within conversation branches:
-
Branch decomposition: Each conversation thread is a tree structure. A branch is defined as a chain from a leaf tweet back through its parent chain to the source tweet. Overlapping tweets are masked at training to avoid duplicate loss computation.
-
Tweet representation: Each tweet is represented as the mean of its word2vec embeddings (pre-trained on Google News, 300d) concatenated with hand-crafted features:
- Lexical: negation word count, swear word count
- Syntactic: period, exclamation mark, question mark, capital letter ratio
- Attachments: URL presence, image presence
- Relational: cosine similarity to source tweet, preceding tweet, and entire thread (using word2vec)
- Content: word count, character count
-
Role: whether the tweet is the source tweet
-
Sequential modeling: Input at each time step is a tweet representation vector. The LSTM layer processes the sequence and outputs predictions at each step. Outputs feed through dense ReLU layers (1–4 layers), 50% dropout, and softmax to produce class probabilities.
-
Training: Categorical cross-entropy loss with class masking to handle branch overlap. Hyperparameters optimized via Tree of Parzen Estimators (TPE) over 100 trials.
Dataset¶
RumourEval 2017 dataset (Derczynski et al. 2017):
- Training: 272 threads, 3,030 branches, 4,238 tweets
- Development: 25 threads, 215 branches, 281 tweets
- Test: 28 threads, 772 branches, 1,049 tweets
- Class distribution: Comments (66%), Support (18%), Deny (8%), Query (8%)
Results¶
| Metric | Development | Testing |
|---|---|---|
| Accuracy | 0.782 | 0.784 |
| Macro F | 0.561 | 0.434 |
Per-class F-scores (test set):
- Support: 0.403
- Deny: 0.000
- Query: 0.462
- Comment: 0.873
Error analysis¶
- Strong performance on source tweets (depth 0): 92.9% accuracy; source tweets are predominantly supporting
- Declining performance at deeper depths: Supporting tweet classification at non-root positions drops significantly
- Deny class failure: 68 denying tweets misclassified as commenting; only 1 misclassified as querying, 2 as supporting. Indicates severe class imbalance challenge.
- Comments dominate: 760/1,049 test predictions are comments; model overrelies on majority class despite focal losses explored
Comparison to participating systems¶
The Turing submission (78.4%) outperformed 12 other systems in Subtask A, with the second-place UWaterloo system achieving 78.0%.
Connections¶
- SemEval-2017 Task 8: RumourEval — the shared task that defined the SDQC stance framework and datasets
- Stance classification — the broader topic covering stance detection across different targets and domains
- Tree structured neural networks — related work on modeling hierarchical/tree conversation structures
- A Survey on Stance Detection for Mis- and Disinformation Identification — later survey of stance detection methods including conversation-aware approaches
- Detection and Resolution of Rumours in Social Media: A Survey — comprehensive review of rumour detection including stance classification
- RumourEval 2019: Determining Rumour Veracity and Support for Rumours — follow-up RumourEval shared task extending to Reddit data
Notes¶
Strengths: - Effective architecture for exploiting conversation structure; sequential branching is intuitive and practical - Thorough hyperparameter tuning via TPE; reproducible methodology - Detailed per-depth performance analysis revealing architectural strengths/weaknesses - Strong empirical results with clear state-of-the-art performance - Feature combinations well-motivated: relational features (similarity to source/preceding tweets) are particularly relevant for stance in context
Limitations: - Severe class imbalance prevents learning of minority classes (denying class F-score is 0.0) - Limited to single-branch decomposition—tree structure information beyond linear chains is discarded - Hand-crafted features may not generalize; no ablation study on feature importance - Bidirectional LSTM variants offered no improvement, but analysis is limited - No cross-event generalization analysis; all evaluation is in-domain - Post-hoc fixes for class imbalance (masking) are modest; authors note more labeled data would help - Unclear why query class (F: 0.462) performs better than deny despite similar train/test representation
Follow-up directions: - The denying class remains a challenge for subsequent work; later RumourEval editions continue to struggle with this minority class - Tree-structured models (e.g., Tree-LSTMs, GNNs) might better capture the full conversation structure than linear branching - Joint learning with veracity prediction (Subtask B) could provide auxiliary signals to help stance detection