DNA-Inspired Online Behavioral Modeling and Its Application to Spambot Detection¶
Authors: Stefano Cresci, Roberto Di Pietro, Marinella Petrocchi, Angelo Spognardi, Maurizio Tesconi
Venue: IEEE Intelligent Systems, 2016 — arXiv:1602.00110
TL;DR¶
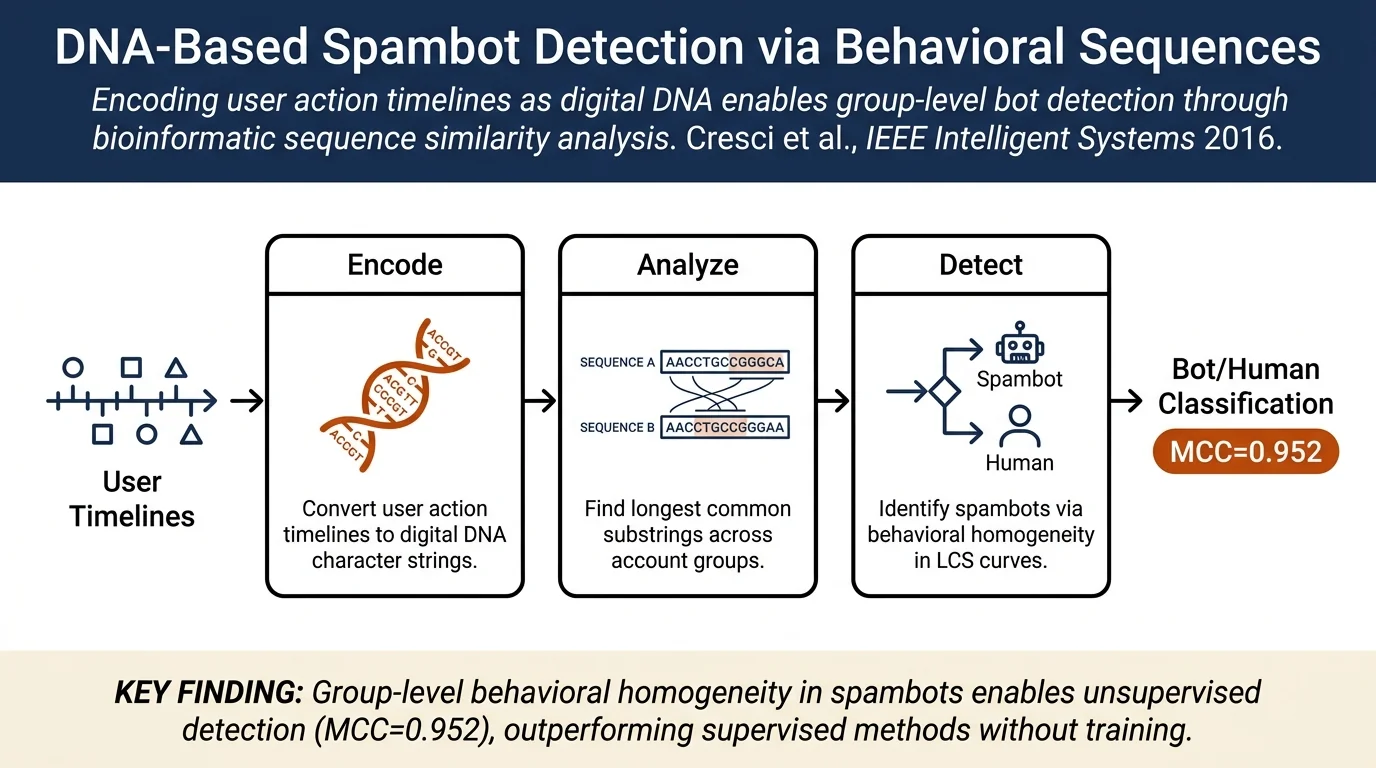
Proposes a novel methodology to characterize online user behavior using DNA-inspired digital sequences, where each user action (tweet type, content features) is encoded as a character in a string. Applies standard bioinformatic DNA analysis techniques—specifically longest common substring (LCS) analysis—to detect spambots on Twitter by identifying groups of accounts with suspiciously similar behavioral sequences. Achieves MCC = 0.952 on political retweet bots and 0.867 on Amazon product-spam bots, outperforming supervised and unsupervised baselines.
Contributions¶
- Novel behavioral encoding paradigm: introduces digital DNA as a flexible, platform-agnostic method to represent sequences of online actions as character strings, enabling transfer of decades of bioinformatic tools to social media analysis
- Unsupervised group-level detection: demonstrates that automated discovery of behavioral similarities among accounts (via LCS analysis) is more effective for detecting evolved spambots than supervised account-level classification
- Empirical paradigm shift: provides evidence that sophisticated bots evade account-centric detection methods but exhibit group-level homogeneity that becomes detectable through sequence analysis
- Practical detection framework: demonstrates digital DNA fingerprinting outperforms existing approaches (Yang et al. 2013, Miller et al. 2014, Ahmed & Abulaish 2013) without requiring training phase or complex feature engineering
Method¶
Digital DNA Encoding¶
Users' online actions are encoded as character sequences analogous to biological DNA. For Twitter, two encoding schemes are evaluated:
- Tweet type DNA: encodes action type (A = simple tweet, T = reply, C = retweet)
- Tweet content DNA: encodes content features (A = contains URLs, T = contains hashtags, C = contains mentions, G = contains media, X = combination of features, N = plain text)
Each user's timeline (up to 3,200 tweets) becomes a single string of characters.
Similarity Analysis via LCS¶
The methodology uses longest common substring (LCS) analysis to quantify behavioral similarity among groups of accounts. Given m accounts, a linear-time algorithm identifies the longest substring common to at least k accounts. The key insight: if a long LCS persists even as k (group size) grows, those accounts exhibit suspiciously homogeneous behavior characteristic of automation.
Spambot Detection via LCS Curves¶
LCS curves plot substring length against group size. Two patterns distinguish spambots from genuine users:
- Plateaux in LCS curves: regions where substring length remains practically constant despite increasing group size, indicating homogeneous account clusters
- Steep drops in derivatives: sudden decreases in LCS length signal boundaries between distinct groups
The derivative of LCS curves (∆LCS / ∆accounts) identifies splitting points via negative peaks, enabling hierarchical top-down partitioning of accounts.
Experimental Setup¶
- Bot datasets: Italian political retweet bots (Bot1, ~1,000 accounts, 50% verified as bots); Amazon product-spam bots (Bot2, ~520 accounts, 89% verified)
- Genuine accounts: 3,474 human accounts verified via direct contact
- Total: 4,929 accounts with behavioral data (timelines crawled)
Results¶
Behavioral Homogeneity¶
Figure 1 demonstrates stark differences between spambots and humans: - Bot1 tweet-type DNA: LCS of ~400 characters shared among 400+ accounts - Bot2 tweet-type DNA: LCS of ~1,750 characters sustained up to 400 accounts - Genuine accounts: exponential decay in LCS, reaching minimal values at small group sizes
Tweet content DNA shows lower LCS values overall; effectiveness varies by bot type (strong signal for Bot2, weak for Bot1).
Detection Performance¶
Comparison against three state-of-the-art approaches on mixed test sets:
Test-set1 (political retweet bots + humans): - Yang et al. (supervised): MCC = 0.043 (supervised approach fails) - Miller et al. (DenStream): MCC = 0.059 (unsupervised clustering weak) - Ahmed & Abulaish (graph mining): MCC = 0.886 - DNA fingerprinting: MCC = 0.952 (Precision = 0.982, Recall = 0.972, F1 = 0.977)
Test-set2 (product-spam bots + humans): - Yang et al.: MCC = 0.287 - Miller et al.: MCC = −0.043 - Ahmed & Abulaish: MCC = 0.847 - DNA fingerprinting: MCC = 0.867 (Precision = 1.000, Recall = 0.858, F1 = 0.923)
DNA fingerprinting achieves the best performance with zero false positives on Test-set2 (perfect precision).
Connections¶
- Closely related to Cresci et al. 2017 which extends group-level detection and provides foundational evidence of sophisticated bot evolution
- Part of a broader shift toward group-level bot detection methods documented in Cresci et al. 2020's longitudinal review
- Methodologically distinct from content and propagation-based detection; inspired by propagation structure analysis but applies sequence similarity rather than graph mining
- Relevant to understanding spambot detection paradigm shifts and limitations of supervised learning approaches
Notes¶
Strengths: - Genuinely novel application of bioinformatic techniques to social media; opens new directions for behavioral analysis - Unsupervised methodology (no training phase required) makes it readily deployable - Strong empirical results, particularly on evolved bots designed to evade existing detectors - Outperforms sophisticated baselines including graph-mining approaches - Platform and technology agnostic design enables generalization beyond Twitter
Limitations: - Evaluated on relatively small, verified bot datasets; unclear how results generalize to larger, more diverse bot populations - Requires full timeline data (3,200 tweets) for good performance; early detection capability not explicitly evaluated - Comparison baseline (Ahmed & Abulaish) uses only 7 features vs. DNA's implicit use of temporal structure; unclear if gains are purely from novel encoding or from implicit feature richness - Limited exploration of tweet content DNA; tweet type DNA substantially more effective but less interpretable - Real-world deployment would require determining optimal LCS threshold and splitting point detection in practice
Future directions: - Ensemble methods combining tweet-type and content DNA with different encoding schemes - Application to other bot types (follower fraud, political coordination) and platforms (Facebook, Instagram) - Online/streaming variants for real-time detection - Theoretical analysis of why group-level behavioral homogeneity emerges in automated systems