Community detection in graphs¶
Author: Santo Fortunato Affiliation: Complex Networks and Systems Larange Laboratory, ISI Foundation, Turin, Italy arXiv: 0906.0612
TL;DR¶
This comprehensive review surveys community detection methods in graphs—the problem of partitioning vertices into clusters with high internal connectivity. It covers traditional approaches (hierarchical clustering, spectral methods, graph partitioning), modern techniques (modularity optimization, random walks, spectral algorithms), and applications across biological networks, social networks, citation networks, and the Web. The paper emphasizes that community detection lacks a universally accepted definition, making algorithm comparison and quality assessment fundamental challenges.
Contributions¶
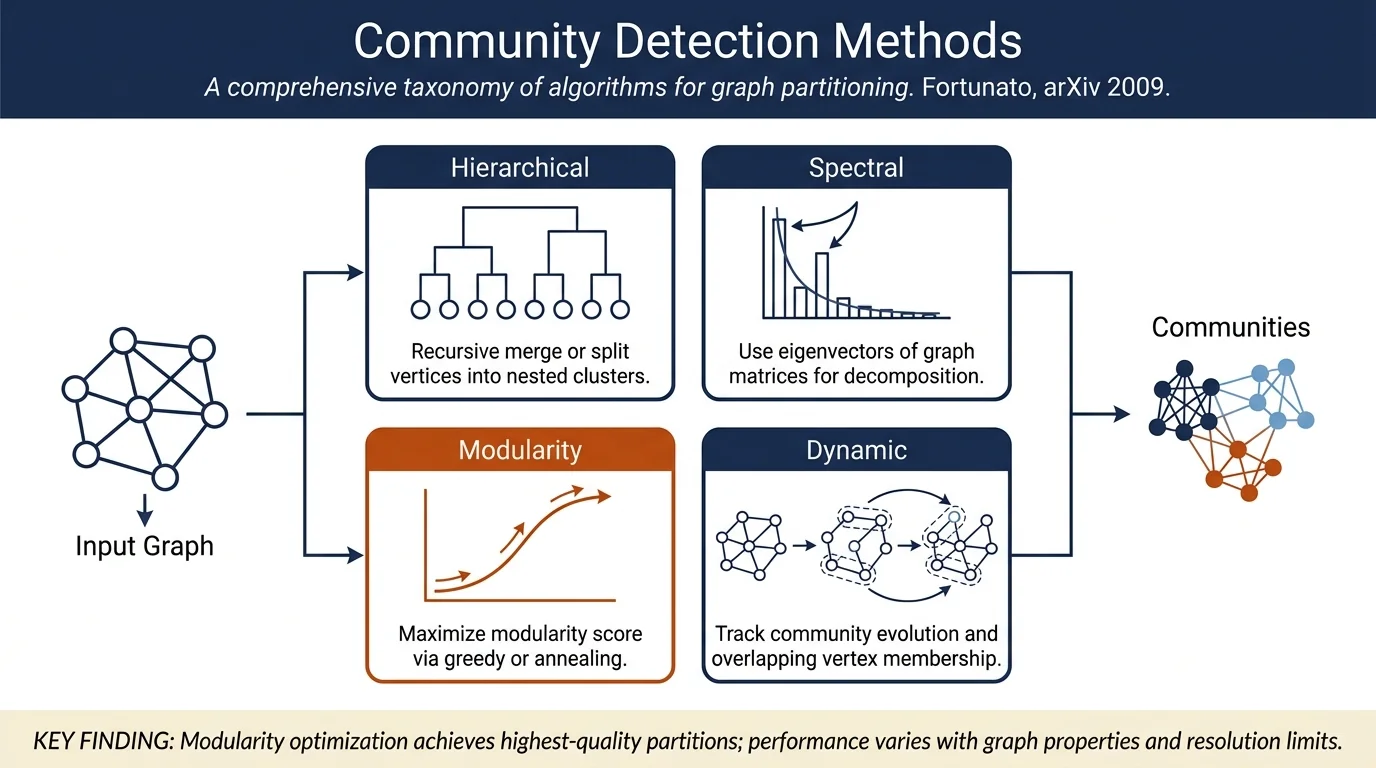
- Unified taxonomy of community detection methods across multiple classes: graph partitioning, hierarchical clustering, spectral methods, modularity-based approaches, divisive algorithms, and spectral clustering
- Theoretical foundations covering computational complexity (NP-hardness), rigorous definitions of community structure via modularity and other quality functions, and graph theory concepts (cliques, cliques percolation)
- Algorithm comparison via benchmarking on the Karate club network, random graphs, and real networks across different scales; analysis of computational complexity and performance tradeoffs
- Real-world applications in biological networks (protein interactions, metabolic networks, gene co-occurrence networks), social networks (collaboration networks, friendship networks, mobile phone communications), citation networks, technological networks (web graphs, the Internet), and other domains
- Open problems including definition of null models, handling of weighted/directed edges, detection of overlapping communities, and discovery of hierarchical community structure
Method¶
The survey is organized into 18 sections covering:
Definitions and complexity (Sections III–IV): Formal definitions of communities through internal/external density, vertex similarity measures, and quality functions like modularity. Discussion of NP-hardness and approximation algorithms. The modularity measure, introduced by Newman and Girvan, quantifies whether a partition has more internal edges than expected by chance.
Traditional approaches (Sections IV–V): Hierarchical clustering (agglomerative and divisive), spectral clustering via eigenvalue decomposition of adjacency or Laplacian matrices, and graph partitioning methods. Hierarchical methods recursively merge or split clusters; spectral methods use eigenvectors of graph matrices to reveal cluster structure.
Modularity optimization (Section VI): Greedy algorithms, simulated annealing, extremal optimization, spectral optimization, and other strategies to maximize modularity. The section emphasizes that modularity optimization via simulated annealing yields the best results on benchmark graphs.
Spectral algorithms (Section VII): Detailed treatment of spectral methods including Fiedler vector approaches for graph bisection and extensions to multiresolution techniques.
Dynamic algorithms (Section VIII): Methods for tracking community evolution over time, including spin models and synchronization approaches.
Methods for overlapping communities (Section XI): Clique percolation methods and other techniques allowing vertices to belong to multiple communities.
Multiresolution methods (Section XII): Hierarchical clustering and resolution-limit approaches addressing how algorithm resolution affects detected community sizes.
Testing and benchmarking (Section XV): Comparative analysis using benchmarks with known community structure (Danon et al., Lancichinetti and Fortunato benchmarks), performance measures (modularity, information theory metrics), and algorithm evaluation on graphs of varying size and structure.
Applications (Section XVII): Detailed case studies on protein-protein interaction networks, social networks (karate club, mobile phone calls, Facebook), citation networks of scientific journals, collaboration networks, and other real systems.
Results¶
Key findings from algorithm comparisons and applications:
- Modularity optimization via simulated annealing produces high-quality partitions, outperforming many other methods; algorithms by Roswall and Bergstrom also perform very well
- Spectral methods are fast and effective for large graphs but may have poorer resolution at detecting very small or very large communities
- Algorithm performance varies with graph properties: on benchmark graphs with known communities, some algorithms recover planted partitions nearly perfectly, while others fail as mixing parameter increases
- Community sizes follow power-law distributions in real networks; small communities coexist with large ones, challenging single-resolution detection methods
- Biological networks show community structure corresponding to functional modules (e.g., protein complexes in PPI networks)
- Social networks exhibit communities aligned with social groups, geography, or interests; overlapping communities reflect multiple group memberships
- Citation networks form communities around scientific disciplines and interdisciplinary research areas
- Computational complexity: Highly varies; some exact algorithms run in exponential time; approximation algorithms scale to large graphs with polynomial complexity
Connections¶
- Foundational for algorithmic community detection in studying misinformation network structure and information propagation patterns
- Provides theoretical grounding for network structure analysis in studying information spread and community formation
- Directly relevant to community detection methods used in social network analysis and misinformation campaign detection
- Cited by papers applying community structure concepts, such as hierarchical information propagation studies
- Informs echo chamber detection which relies on identifying tightly connected communities in online discourse networks
Notes¶
Strengths: - Exceptionally thorough coverage of methods, theory, and applications across 103 pages with 17 sections - Provides historical perspective, tracing community detection from Weiss & Jacobson (1955) to modern algorithms - Clear exposition of fundamental concepts (modularity, cliques, density) with mathematical precision - Extensive benchmarking and comparative analysis of algorithm performance across different graph sizes and structures - Practical guidance on algorithm selection for different problem domains and scales - Real-world case studies illustrate applicability to diverse network types (biological, social, technological)
Weaknesses: - Published in 2009; misses important recent developments in deep learning-based community detection and large-scale streaming algorithms - Lack of universally accepted definition for communities acknowledged but not fully resolved; comparisons across algorithms sometimes conflate different notions of what constitutes a community - Limited discussion of computational cost-benefit tradeoffs in selecting algorithms for real applications with budget constraints - Overlapping community detection covered only briefly; hierarchical structure treatment limited - Weighted/directed graph treatment scattered; not systematically organized
Follow-up opportunities: - Integration of community detection with language models or embedding methods for richer feature representations - Extension to temporal/dynamic networks with evolving community structure - Development of hybrid approaches combining multiple methods for robustness - Application to emerging domains like misinformation spreading networks and bot detection - Theoretical work on resolution limits and fundamental definitional boundaries of community structure