Advancing Graph Representation Learning with Large Language Models: A Comprehensive Survey of Techniques¶
Authors: Qiheng Mao, Zemin Liu, Chenghao Liu, Zhuo Li, Jianling Sun
Venue: arXiv, February 2024 — arxiv:2402.05952
TL;DR¶
This comprehensive survey analyzes the integration of Large Language Models (LLMs) with Graph Representation Learning (GRL), breaking down the design space into two primary components—knowledge extractors and organizers—plus operation techniques for integration and training. The work provides a novel taxonomy for understanding how LLMs can enhance GRL through textual and semantic information, addressing a significant gap in systematic reviews of graph foundation models. The survey identifies key challenges and future research directions for building effective LLM-enhanced graph models.
Contributions¶
The paper makes three primary contributions:
- Comprehensive analysis of research integrating LLMs into GRL as unified models, with detailed breakdown of essential components and operations from a technical perspective.
- Novel taxonomy categorizing models into two components (knowledge extractors and organizers) and two operation techniques (integration and training strategies), offering readers a framework for designing graph foundation models.
- Future research directions aligned with the organizational framework, suggesting paths for advancement in LLM-enhanced GRL.
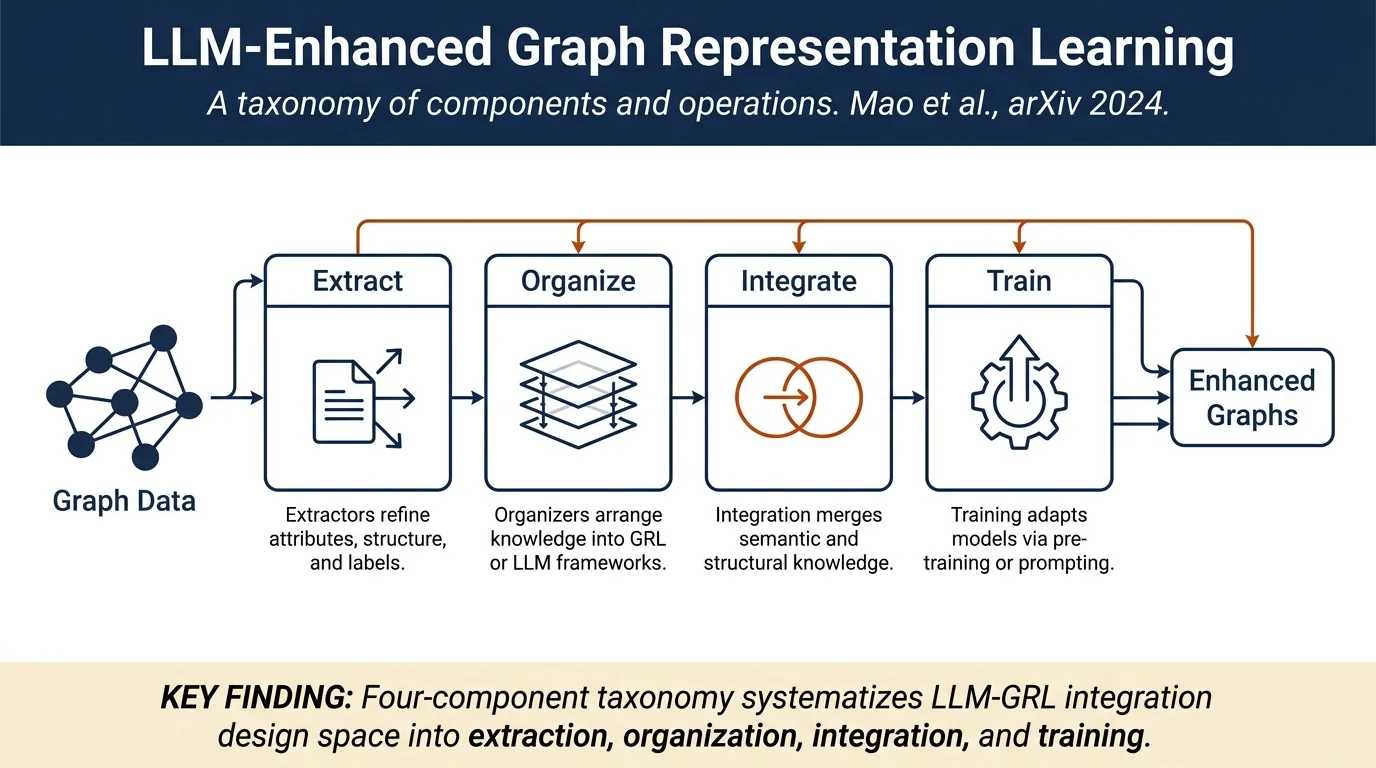
Method¶
The survey decomposes GRL-LLM integration into primary components and operation techniques:
Knowledge Extractors handle extraction of information from graph data: - Attribute extractors (text-level and feature-level) enhance node/edge attributes using LLM capabilities. - Structure extractors refine noisy graph structures and convert graph information into natural language descriptions. - Label extractors leverage LLM zero-shot capabilities to annotate scarce labeled data.
Knowledge Organizers arrange extracted knowledge: - GNN-centric organizers use LLMs as auxiliary modules to initialize features or optimize structures. - LLM-centric organizers make LLMs the sole backbone by converting graphs to text sequences. - GNN+LLM organizers combine both architectures to leverage strengths of each modality.
Integration strategies merge semantic and structural knowledge: - Input-level integration amalgamates data at the input stage. - Hidden-level integration merges representations at latent processing stages. - Alignment-based integration (contrastive, iterative, distillation) transfers knowledge between modalities.
Training strategies enhance LLM adaptability: - Model pre-training captures general patterns from graph and language corpora. - Prompt-based training (prompting and prompt tuning) guides model outputs for graph tasks. - Instruction tuning integrates pre-trained models with task-specific instructions.
Results¶
The paper does not report empirical results; rather, it systematizes 20+ recent approaches through its taxonomy. Key findings include:
- Input-level integration is widely adopted for its simplicity in handling both modalities.
- Alignment-based integration offers principled knowledge transfer but faces efficiency challenges from LLM training.
- Few studies focus on injecting graph structure knowledge into LLMs during pre-training—a promising but underexplored direction.
- Most approaches treat LLMs as plug-and-play modules; deeper integration remains an open problem.
Connections¶
- Related to A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities via shared use of graph and text features for detection tasks.
- Related to Neural Network Architectures through GNN design space exploration.
- Relevant to Multimodal Learning as it bridges graph and language modalities.
- Builds on foundational graph representation work: Graph Neural Networks, Graph Embedding.
Notes¶
Strengths: - First systematic taxonomy bridging GRL and LLM integration from a technical standpoint rather than by application or LLM role (as in prior surveys). - Clear decomposition into components and operations enables researchers to design novel architectures. - Identifies genuine gaps: non-textual graph adaptation, training efficiency, unified theoretical framework.
Limitations: - Purely taxonomic; no empirical comparison of approaches or best practices. - Scope limited to GNNs as the primary graph learning model, excluding recent graph Transformers. - Limited discussion of computational cost tradeoffs between integration strategies.
Future work: - Pre-training paradigms blending GNN and LLM knowledge at the model level (InstructGLM hints at this). - Unified theory for analyzing GNN, Graph Transformer, and LLM architectures. - Efficient training strategies that do not require full LLM retraining.