The Science of Detecting LLM-Generated Texts¶
Authors: Ruixiang Tang, Yu-Neng Chuang, Xia Hu
Affiliation: Department of Computer Science, Rice University
Venue: arXiv, 2023 — arxiv:2303.07205
TL;DR¶
This survey comprehensively reviews techniques for detecting LLM-generated text, a critical problem given concerns about misinformation, academic dishonesty, and unauthorized use. The authors categorize detection approaches into black-box (API-level access) and white-box (full model access) methods, discuss watermarking strategies, benchmark datasets, and highlight future challenges including adaptive attacks and the threat of open-source LLMs.
Contributions¶
- Systematic categorization of black-box and white-box detection methodologies
- Overview of black-box approaches: data collection, feature selection (statistical disparities, linguistic patterns, fact verification), and classification models
- Coverage of white-box approaches: post-hoc watermarking (rule-based and neural-based) and inference-time watermarking
- Review of benchmark datasets (HC3, Neural Fake News, TweepFake, GPT-2-Output, TURINGBENCH)
- Analysis of adaptive attacks (paraphrasing attacks) against detection systems
- Identification of critical limitations: dataset bias, confidence calibration, comprehensive evaluation metrics, and threats from open-source LLMs
Method¶
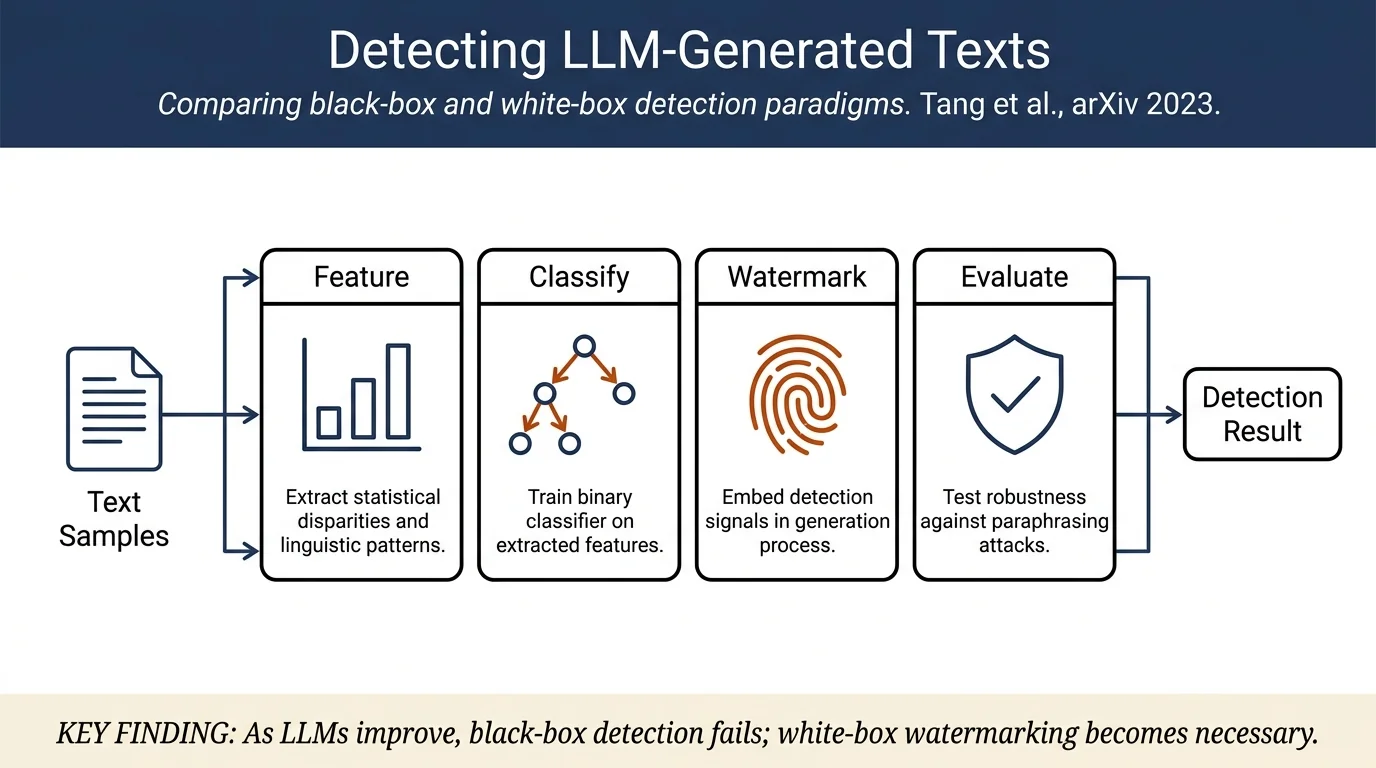
The survey is organized around two main detection paradigms:
Black-box Detection: External entities with API-level access build binary classifiers to distinguish human from machine-generated text. The approach follows a data analytics lifecycle: (1) acquiring paired human and LLM-generated text samples, (2) extracting discriminative features from three categories—statistical disparities (perplexity, word ranking, Zipfian coefficients), linguistic patterns (vocabulary, part-of-speech, sentiment, stylometry), and fact verification (hallucination detection)—and (3) training classifiers (traditional algorithms like SVM/random forests or deep learning models like fine-tuned RoBERTa).
White-box Detection: LLM developers with full model access embed watermarks to trace generated content. Post-hoc watermarks are applied after text generation (rule-based methods modify syntactic/semantic structure; neural-based methods use encoder-decoder-discriminator networks). Inference-time watermarks modify the decoding process by using hash functions to partition vocabulary into "green" and "red" lists, constraining token sampling to embed traceable signals.
Results¶
The survey documents representative datasets and baseline performances: the HC3 dataset achieved 99.79% F1 for paragraph-level ChatGPT detection and 98.43% at sentence level using RoBERTa. However, paraphrasing attacks significantly degrade detector accuracy—reducing inference-time watermark detection from 97% to 80% and black-box detector TPR from 100% to 80%. The paper emphasizes that as LLM quality improves, black-box detection signals diminish, making white-box watermarking increasingly necessary.
Connections¶
- Related to DetectGPT via shared focus on zero-shot detection signals
- Extends hallucination research by discussing fact verification as a detection feature
- Overlaps with other surveys on LLM-generated misinformation in addressing misuse concerns
- Cited by and informs work on LLM disinformation capabilities
Notes¶
Strengths: Comprehensive, well-organized taxonomy of detection methods. Clear exposition of the limitations driving the field toward white-box solutions. Explicit discussion of threats from open-source LLMs and the arms race between attackers and detectors.
Weaknesses: The survey's scope (arxiv June 2023) predates newer detection techniques and larger LLMs. Limited empirical comparison across detectors on unified benchmarks; most evaluation is inherited from cited papers. Confidence calibration and low-FPR regimes—critical for high-stakes applications—receive less treatment than needed for practitioners.
Follow-up questions: How do detection methods generalize across LLMs (GPT-3, GPT-4, Llama, etc.)? Can watermarking withstand fine-tuning or distillation attacks? How should low false-positive requirements be balanced against detection recall in safety-critical domains like education?