3HAN: A Deep Neural Network for Fake News Detection¶
Authors: Sneha Singhania, Nigel Fernandez, Shrisha Rao Affiliation: International Institute of Information Technology - Bangalore, India arXiv: 2306.12014
TL;DR¶
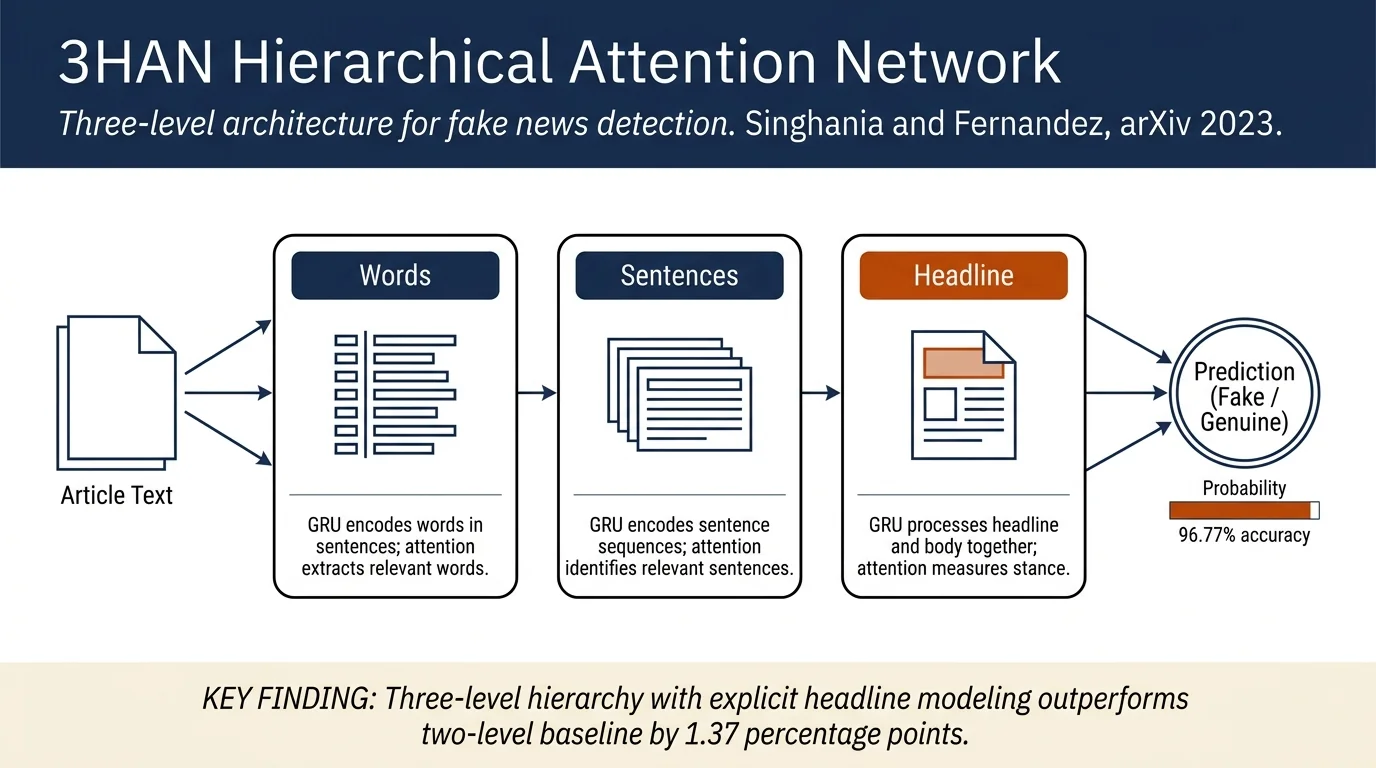
Proposes 3HAN, a three-level hierarchical attention network for fake news detection that models articles as a hierarchy of words, sentences, and headlines. The model assigns differential importance weights to different parts via attention mechanisms, achieving 96.77% accuracy while providing interpretable attention visualizations showing which words and sentences drive fake news predictions. The headline is treated as a distinguishing feature of fake news via a third hierarchical level not present in prior work.
Contributions¶
- Three-level hierarchical architecture: Extends the two-level HAN model with a third level specifically designed to model the stance of headlines relative to article bodies, based on the observation that headlines are a distinctive feature of fake news.
- Headline premise: Proposes that headlines contain distinctive signals (distinctiveness, conciseness, stance) useful for fake news detection; validates this via supervised pre-training on headlines alone.
- Interpretability via attention visualization: Unlike opaque neural models, 3HAN provides attention weights for words, sentences, and headlines that can be visualized in heatmaps, enabling human fact-checkers to focus verification efforts on high-attention elements.
- Strong empirical results: Achieves 96.77% accuracy on a balanced dataset of ~41K articles; outperforms strong baselines including HAN and attention variants.
Method¶
Architecture: Three-level hierarchical encoding with attention at each level:
-
Word level (Layer 1): Bidirectional GRU encodes word sequences within sentences using GloVe embeddings, producing word annotations. Attention layer extracts relevant words via a learned relevance vector, outputting sentence representations.
-
Sentence level (Layer 2): Bidirectional GRU encodes sentence sequences within article bodies, capturing coherence between sentences. Sentence-level attention identifies relevant sentences, producing a body vector.
-
Headline-body level (Layer 3): Bidirectional GRU processes headline words and the body vector together (body appended as final token), capturing the stance of the headline with respect to the body. Headline-body attention produces the final news vector.
Training: GRU units use 50 dimensions; combined annotation 100 dimensions; relevance vectors 100 dimensions. SGD optimizer with learning rate 0.01, momentum 0.9, batch size 32. Standard binary cross-entropy loss.
Pre-training: Headlines alone are used to supervise Layer 1 (word encoder + attention), initializing 3HAN with better weights before full-model training.
Results¶
Evaluated on a balanced dataset: 19 fake news sites (20,372 articles), 9 genuine sites (20,932 articles). 70% test split; 10% validation; 20% training (neural models use 20/10/70, word-count models use 30/70).
| Model | Accuracy |
|---|---|
| 3HAN | 96.24% |
| 3HAN+PT (pre-trained) | 96.77% |
| HAN | 95.4% |
| HAN-Ave | 94.91% |
| GRU-Ave | 95.65% |
| Bag-of-ngrams+TFIDF | 92.47% |
| Bag-of-words+TFIDF | 91.92% |
3HAN outperforms all baselines. The 3HAN+PT variant (with headline pre-training) achieves the best result; the improvement from 96.24% to 96.77% demonstrates the value of headline-focused initialization.
Insights¶
Hierarchical structure exploits article organization: Models the natural three-level composition of articles (words → sentences → article). Explicitly handling headlines as a separate level outperforms two-level HAN (95.4%), validating the headline premise.
Attention is more effective than pooling: 3HAN (attention) achieves 96.24% vs. 3HAN-Ave (mean pooling) at 94.81% and 3HAN-Max (max pooling) at 95.25%, showing that learned attention mechanisms capture differential relevance better than fixed pooling strategies.
Word-count models perform surprisingly well: Baseline word-count models achieve 90–92% accuracy, indicating that vocabulary and word usage patterns are strong distinguishing signals between fake and genuine news independent of word order.
Inverted pyramid structure in fake news: The paper observes that fake news articles are repetitive, and that improvement plateaus with larger padding window sizes, suggesting that fake news concentrates information in the opening sentences (inverted pyramid style), a pattern that limits the utility of longer article representations.
Attention visualization¶
The paper includes a heatmap example showing attention weights for words and sentences in a fake news article with headline "Trump Defies Left with Brilliant Move - You Will Cheer." Sentence 5 ("Even refugee welcoming Canada levies a 12 percent penalty on immigrant money") receives the highest attention (0.287), and this sentence is indeed factually incorrect. The visualization demonstrates that attention weights correlate with veracity-relevant elements, enabling human fact-checkers to prioritize verification of high-attention sentences.
Connections¶
- Related to Propagation-based fake news detection through multi-level feature aggregation, though 3HAN is purely content-based.
- Extends DeepCas and prior hierarchy models by adding explicit headline modeling.
- Compared against stylometric detection approaches; shows attention-based learning outperforms hand-crafted features.
- Similar in architecture to CSI but focuses on article structure rather than temporal engagement patterns.
- Related to Linguistic style detection via implicit learning of linguistic patterns through attention.
Notes¶
Strengths: - Simple, interpretable architecture that directly models article hierarchy. - Strong empirical results; pre-training technique is practical and effective. - Attention visualization provides actionable insights for human fact-checkers. - Balanced dataset avoids class imbalance issues present in some benchmarks.
Limitations: - Evaluated only on a single dataset; generalization to other domains unclear. - Website-level labels (all articles from a site share one label) are noisier than article-level fact-checking; ignores potential diversity within sites. - No comparison against more recent pre-trained transformer models (BERT, RoBERTa) which were available in 2023. - The headline pre-training requires labeled headlines; applicability to datasets without headlines unclear. - Limited error analysis; no investigation of failure cases or adversarial robustness.