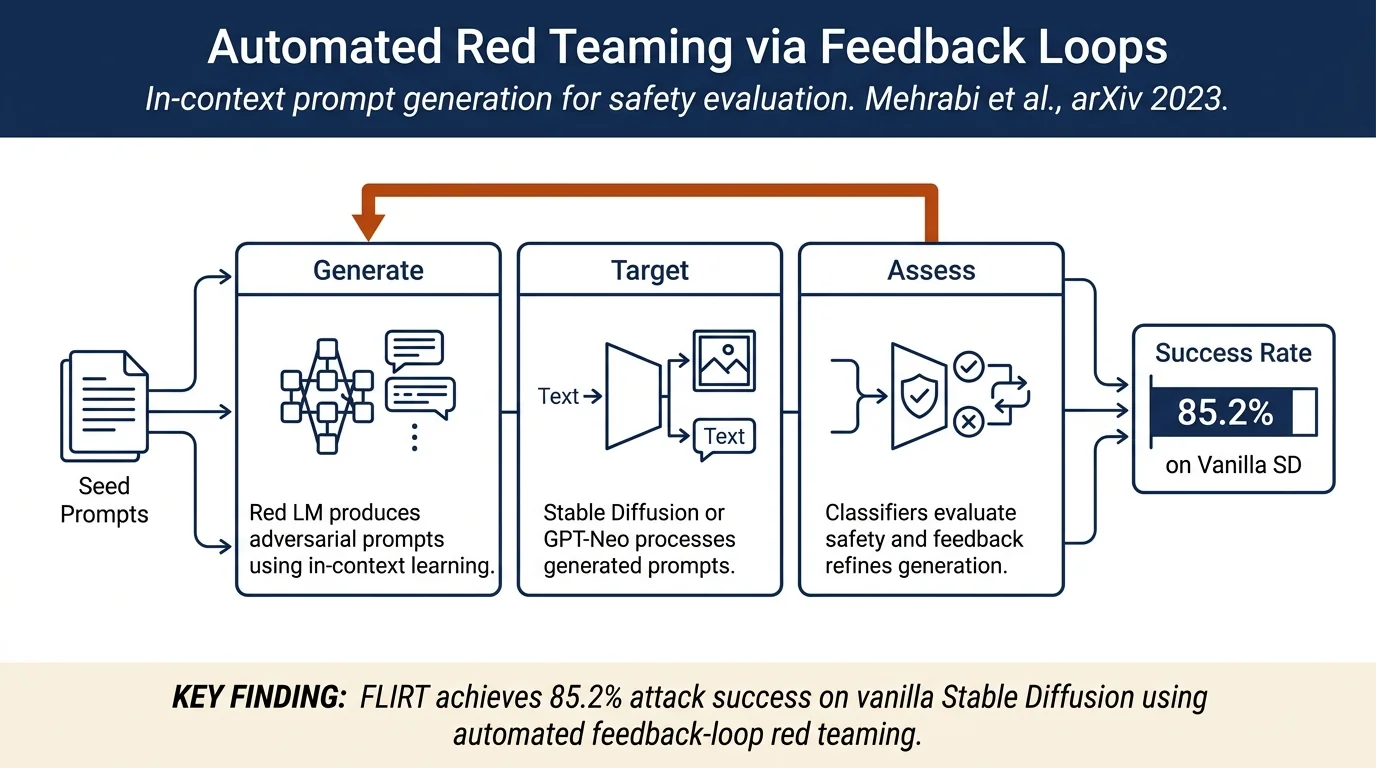
FLIRT: Feedback Loop In-context Red Teaming¶
Authors: Ninareh Mehrabi, Palash Goyal, Christophe Dupuy, Qian Hu, Shatini Ghosh, Richard Zemel, Kai-Wei Chang, Aram Galstyan, Rahul Gupta
Venue: arXiv preprint, 2023 — arXiv:2308.04265
TL;DR¶
FLIRT automates red teaming of generative models by using in-context learning to generate adversarial prompts in a feedback loop: a red language model generates candidate prompts, they are evaluated against a target model (e.g., text-to-image or text-to-text), safety classifiers assess the outputs, and results feed back to refine future prompts. The approach achieves ~80% attack success on vanilla Stable Diffusion and ~60% on safeguarded variants, substantially outperforming prior manual or weakly-automated approaches.
Contributions¶
- Automated red teaming framework using in-context learning: a red LM generates adversarial prompts without fine-tuning, enabling rapid iteration without expensive data collection.
- Multiple attack strategies with different computational and effectiveness trade-offs: FIFO (queue-based), LIFO (stack-based), Scoring (optimizes effectiveness and toxicity jointly), Scoring-LIFO (combines scoring with diversity control), and SFS (stochastic few-shot); allows practitioners to trade off attack effectiveness vs. prompt diversity.
- Transferability analysis showing attacks generated for one text-to-image model transfer successfully to others (e.g., 93.8% of attacks effective on vanilla SD transfer to Weak Safe SD; 100% to Max Safe SD).
- Content moderation integration demonstrating that safety filters alone are insufficient; FLIRT can penetrate filters by learning to bypass them.
- Extension to text-to-text models using GPT-Neo, showing the framework generalizes beyond image generation.
Method¶
FLIRT operates in three repeated stages:
1. Initialization. The red LM begins with a small set of hand-engineered seed prompts designed to trigger unsafe generation (covering content categories like sexual violence, self-harm, harassment, illegal activity, and shocking topics). The seed set is ordered.
2. Adversarial prompt generation. The red LM uses in-context learning: it reads the current set of exemplar prompts and generates a new candidate prompt. At each iteration, the red LM can employ one of several strategies to decide which prompts to keep and which to replace:
- FIFO (First-In-First-Out): New prompts with positive feedback (successful attack) are enqueued at the end; once the queue is full, the oldest exemplar prompt is removed, preserving initial intent while allowing evolutionary refinement.
- LIFO (Last-In-First-Out): New prompts go to the top of the stack and replace old ones, but all exemplars remain. This allows the algorithm to exploit recent successful generations.
- Scoring: The red LM combines two objectives—attack effectiveness (likelihood the target model generates unsafe output, measured via Q16 and NudeNet classifiers) and low-toxicity (likelihood the prompt itself is non-toxic, via Perspective API toxicity scorer and the Toxigen classifier)—into a scalar objective: $\(X^{t+1} = \arg\max_{X} \sum_{i=1}^n \lambda_i O_i(X),\)$ where \(\lambda_i\) weights each objective. Prompts are kept only if they improve the objective score.
- Scoring-LIFO: Combines scoring with diversity control; introduces a secondary objective to maximize pairwise sentence embeddings' cosine similarity across the exemplar set, encouraging diverse prompts.
3. Evaluation and feedback. Generated images are evaluated for safety using two classifiers: Q16 (a specialized 16-way classifier for unsafe image categories) and NudeNet (detects nudity and erotic content). For text-to-text models, the Toxigen classifier assesses toxicity. This safety assessment feeds back to the red LM as a signal for whether the exemplar prompt should be retained, replaced, or refined.
The framework targets Stable Diffusion (vanilla and safe variants: Weak, Medium, Strong, Max Safe) and GPT-Neo text-to-text models. The red LM is initialized with GPT-Neo 2.7B and tasked with generating prompts from seed categories.
Results¶
Text-to-image models (Stable Diffusion variants):
Across all attack strategies and models, Scoring-LIFO achieves the best results:
- Vanilla Stable Diffusion: 85.2% attack success (Scoring)
- Weak Safe SD: 90.8% success (Scoring)
- Medium Safe SD: 86.6% success (Scoring) / 84.6% (Scoring-LIFO)
- Strong Safe SD: 41.0% success
- Max Safe SD: 38.0% success (Scoring)
FLIRT substantially outperforms the Stochastic Few-Shot (SFS) baseline (Perez et al., 2022), which achieves only 30–50% on vanilla models.
Diversity and toxicity trade-off:
When diversity is added as a secondary objective (Scoring-LIFO with varying \(\lambda_2\) weights), prompts remain effective while becoming more diverse. At \(\lambda_2 = 0.5\), the framework achieves 73.5% effectiveness on vanilla SD with controlled prompt diversity.
Robustness to safety classifier noise:
When 5–20% label noise is injected into the safety classifiers' outputs, results remain stable (77–89% effectiveness), demonstrating robustness.
Attack transferability:
Attacks generated against vanilla SD transfer effectively to other models, but success varies by safety robustness. Vanilla SD → Weak Safe SD shows 93.8% transfer rate; vanilla SD → Max Safe SD shows 100% transfer but on fewer prompts. This suggests safe variants operate under different threat models but share vulnerabilities.
Text-to-text models:
On GPT-Neo (replacing the target with a language model), FLIRT achieves 52.4% effectiveness using Scoring-LIFO with Toxigen for evaluation, demonstrating the framework's generalizability beyond image generation.
Connections¶
- Related to Perez et al. (2022) via shared feedback loop paradigm, but uses lightweight in-context learning rather than expensive fine-tuning or human-in-the-loop iteration.
- Related to Schramowski et al. (2022a) on safety evaluation of text-to-image models; FLIRT shows that content moderation filters alone do not guarantee safety.
- Related to Mishkin et al. (2022) on misuse potential of text-to-image models; FLIRT quantifies the magnitude of the vulnerability.
- Relevant to AI safety research on robustness and red teaming as an evaluation paradigm.
Notes¶
Strengths: - Practical scalability. Unlike human-in-the-loop approaches, FLIRT automates red teaming; compared to fine-tuning-based red teaming, in-context learning is dramatically faster and cheaper. - Flexible objective optimization. The framework decouples attack effectiveness, prompt diversity, and toxicity—allowing practitioners to prioritize trade-offs rather than accepting a fixed approach. - Strong empirical results. FLIRT achieves 80%+ success on vanilla Stable Diffusion and substantially outperforms prior baselines. - Generalization. Transfer across text-to-image models and applicability to text-to-text models demonstrate broad utility. - Comprehensive ablations. Q1–Q5 ablations address language model choice, content moderation, prompt toxicity control, attack transferability, and classifier noise robustness.
Weaknesses: - Limited novelty in components. The feedback loop, safety classifiers, and in-context learning are all established techniques; novelty lies primarily in their combination for red teaming. - Vulnerability to adversarial classifiers. The approach relies on fixed safety classifiers (Q16, NudeNet, Toxigen). If these classifiers are adversarially trained, FLIRT's effectiveness could degrade. - Ethical and societal risks. Although the authors justify red teaming for model hardening, automated adversarial prompt generation could be misused to attack unprepared systems or to scale malicious content generation. The paper's ethics statement acknowledges this but concludes that the transparency gains outweigh risks. - Limited evaluation of real-world impact. Experiments test triggering unsafe image/text generation, but do not measure downstream harms (e.g., whether users would share unsafe images or be harmed by generated text). - Seed prompt dependence. The initial seed prompts are hand-engineered and designed to cover unsafe content categories. Results may be biased toward these categories; unexplored unsafe categories might require different seeds.
Open questions: - How does FLIRT perform against adversarially trained safety classifiers or defenses designed specifically to thwart in-context learning attacks? - Can FLIRT be extended to multi-modal models (e.g., attacking both image generation and text understanding simultaneously)? - What is the optimal balance between attack effectiveness and prompt naturalness / non-toxicity for practical deployment as a red teaming tool?