A Multi-Modal Method for Satire Detection using Textual and Visual Cues¶
Authors: Lily Li, Or Levi, Pedram Hosseini, David A. Broniatowski Venue: arXiv, 2020 — arXiv:2010.06671
TL;DR¶
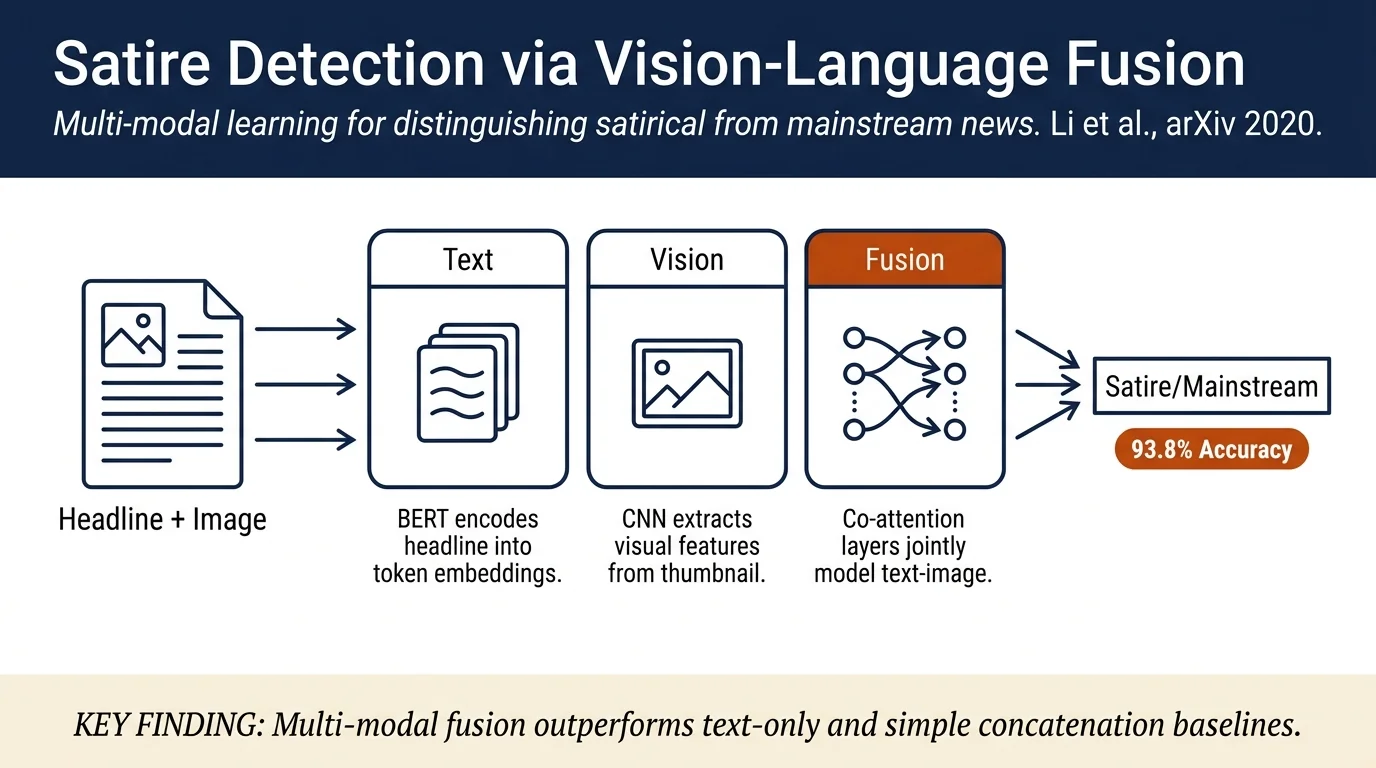
Satirical news articles are often misinterpreted as legitimate news. This work proposes a multi-modal approach using ViLBERT to detect satire by jointly analyzing headline text and thumbnail images, achieving 93.8% accuracy on a new dataset of 10,000 articles (4000 satirical, 6000 mainstream).
Contributions¶
- Created a new multi-modal satire detection dataset with images and headlines from 4 satirical sources (Babylon Bee, Clickhole, Waterford Whisper News, DailyER) and 6 mainstream news outlets
- Proposed a ViLBERT-based approach that performs early fusion of visual and textual representations, outperforming uni-modal and simple fusion baselines
- Explored image forensics via Error Level Analysis (ELA) combined with CNNs to detect image tampering as a satire indicator (though this approach underperformed)
Method¶
The authors use Vision & Language BERT (ViLBERT), a state-of-the-art visiolinguistic model with two parallel transformer streams (one for images, one for text) connected by co-attentive layers. The model processes article thumbnail images and headlines jointly, with multi-head attention computed between visual and textual modalities at each layer. ViLBERT was pre-trained on the Conceptual Captions dataset and fine-tuned on the satire detection task.
They also implemented an ELA+CNN model: images were preprocessed with Error Level Analysis (a lossy JPEG compression-based forensics technique) to highlight manipulation artifacts, then fed through a two-layer CNN (32 kernels, 5-width filters) to classify as forged or authentic.
Training used 80%–20% train-test split, batch size 32, Adam optimizer. ViLBERT was fine-tuned for 12 epochs at 5e-6 learning rate; ELA+CNN trained for 7 epochs at 1e-5.
Results¶
ViLBERT achieved 93.80% accuracy, 92.16 F1 score, and 98.03 AUC-ROC, outperforming text-only BERT (91.33%) and simple fusion baselines (92.53–92.74%). Surprisingly, the ELA+CNN approach performed poorly (44.20% accuracy, worse than random), likely because ELA cannot reliably detect tampering in internet images that have been resaved multiple times or detect what manipulation technique was used.
The authors analyzed 20% of misclassifications and identified three failure modes: headline misinterpretation (e.g., metaphorical language interpreted literally), lack of political knowledge (failing to recognize incongruence in context), and bizarre-but-true stories mistaken as satire.
Connections¶
- Related to Multimodal fake news detection for joint image-text analysis
- Extends prior work on satire detection by adding visual modality to textual analysis
- Complements Image forensics approaches for detecting media manipulation
- Relevant to broader Misinformation and fake news detection via multi-modal fusion
Notes¶
This is a solid contribution to satire detection, a relatively understudied subtask of fake news. The ViLBERT-based fusion approach is well-motivated: satirical news often uses absurd or spliced images to reinforce the joke. The multi-modal dataset is valuable. However, the ELA forensics approach's failure is instructive—it highlights that image-level tampering cues alone may not suffice for satire (many genuine images are edited for minor adjustments, and satirical images may not always be detectably forged). The paper's main limitation is that performance depends heavily on the headline; the model struggles with implicit sarcasm or knowledge-dependent satire. Future work incorporating political knowledge and more sophisticated image forensics methods is promising.