A Survey of the State of Explainable AI for Natural Language Processing¶
Authors: Marina Danilevsky, Kun Qian, Ranit Aharonov, Yannis Katsis, Ban Kawas, Prithviraj Sen
Affiliation: IBM Research – Almadem
Publication: arXiv, October 2020 — arXiv:2010.00711
TL;DR¶
Recent neural NLP models achieve strong performance but are often opaque. This survey systematically reviews explainable AI (XAI) research in NLP across 50 papers from major conferences (2013–2019), categorizing explanations by scope (local vs. global) and generation (self-explaining vs. post-hoc), detailing five major techniques (feature importance, surrogate models, example-driven, provenance-based, induction), and identifying gaps in evaluation methodology.
Contributions¶
- Provides the first XAI survey focused specifically on the NLP domain, establishing a taxonomy of explanation approaches.
- Categorizes explanations along two primary dimensions:
- Local vs. Global: explanations for individual predictions versus the model's overall behavior.
- Self-Explaining vs. Post-Hoc: explanations embedded in the prediction process versus generated after prediction.
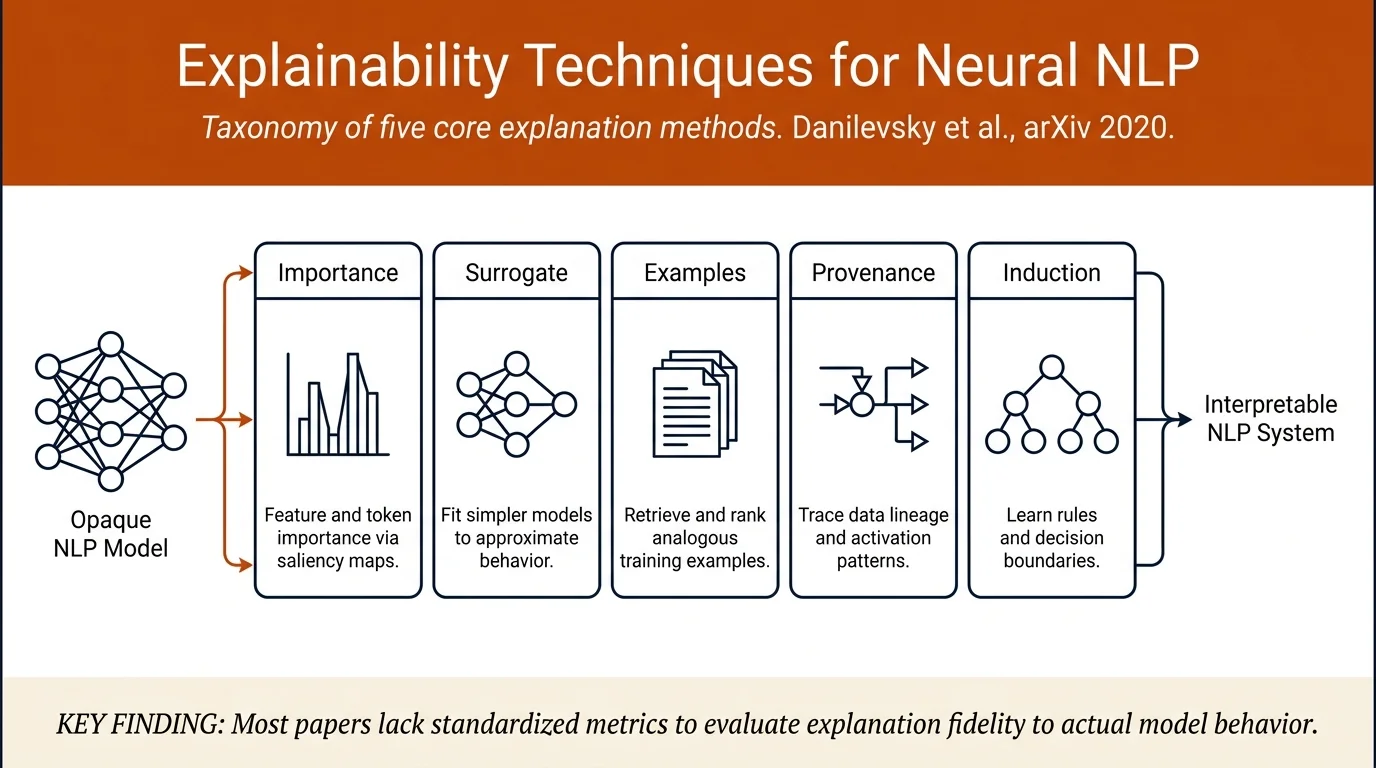
- Identifies and describes five core explainability techniques: feature importance, surrogate models, example-driven approaches, provenance-based methods, and induction-based rules.
- Reviews visualization techniques for presenting explanations: saliency maps, raw declarative representations, and natural language explanations.
- Discusses evaluation approaches and identifies major gaps: lack of standardized metrics, underutilization of human evaluation, and limited clarity on what aspects of model behavior explanations should cover.
- Provides a resource for model developers seeking to build explainable NLP systems.
Method¶
Literature Identification and Filtering. The authors searched major NLP conferences (ACL, EMNLP, NAACL, COLING) for papers published between 2013 and 2019 using keywords related to explainability (e.g., "explainability," "interpretability," "transparent," "interpretable"). Papers were manually reviewed and classified by at least two reviewers; disagreements were resolved by consulting additional reviewers.
Categorization Framework. Papers were grouped by two independent dimensions (local/global and self-explaining/post-hoc), then further organized by the explainability techniques they employ and the visualization methods used to present explanations.
Results¶
The survey analyzed 50 papers, categorized as follows: - 46 of 50 papers employ local explanations; only 4 provide global explanations. - 46 of 50 papers use self-explaining approaches; 4 papers use post-hoc techniques. - Feature importance-based and surrogate model-based approaches dominate, appearing in 29 and 8 papers respectively. - Saliency-based visualization is the most common presentation technique, used across multiple approaches. - Most papers (32 of 50) lack standardized evaluation; only 18 papers include formal evaluation of explanation quality (ground-truth comparison, human evaluation, or both).
Major Findings: - White-box models (decision trees, rule-based systems) are less frequently studied in modern NLP literature, where neural networks dominate. - Attention mechanisms are widely adopted for explainability but their fidelity for true model explanation remains debated. - Few papers systematically evaluate whether explanations are faithful to model behavior versus merely plausible to humans.
Connections¶
- Related to NLP Interpretability via shared focus on understanding model behavior.
- Cites canonical methodology in word embeddings for embeddings and LSTM Gating Signals for sequential model interpretation.
- Foundational for explainable fake news detection approaches and interpretable news ranking systems.
- Relevant to Neural Network Transparency as a broader topic in AI interpretability.
Notes¶
Strengths: - First comprehensive taxonomy of explainability in NLP; fills a critical gap in the literature. - Well-structured categorization (local/global, self-explaining/post-hoc) provides a clear mental model for reasoning about explanation strategies. - Extensive literature review across major venues ensures good coverage of contemporary approaches. - Honest about methodological gaps—most papers lack rigorous evaluation of explanation quality.
Weaknesses: - Limited discussion of trade-offs between explainability and model performance; many real deployments accept lower accuracy for interpretability. - Evaluation section is largely descriptive; limited guidance on how practitioners should choose among techniques for their use case. - Survey's own categorization (local/global) sometimes conflates different concerns—a model can provide local explanations that collectively reveal global behavior, or vice versa.
Significance: This survey is essential reading for anyone building explainable NLP systems, including fake-news detectors. The taxonomy and gap analysis directly inform the design of dEFEND and similar explainability-aware architectures in the misinformation detection literature.
Open Questions: - Can attention weights be reliably used as explanations, or do they primarily reflect statistical patterns? (Jain & Wallace, 2019 suggests caution.) - How do we measure fidelity of explanations without ground truth on what a model "should" attend to? - Which explainability techniques generalize across different NLP tasks?