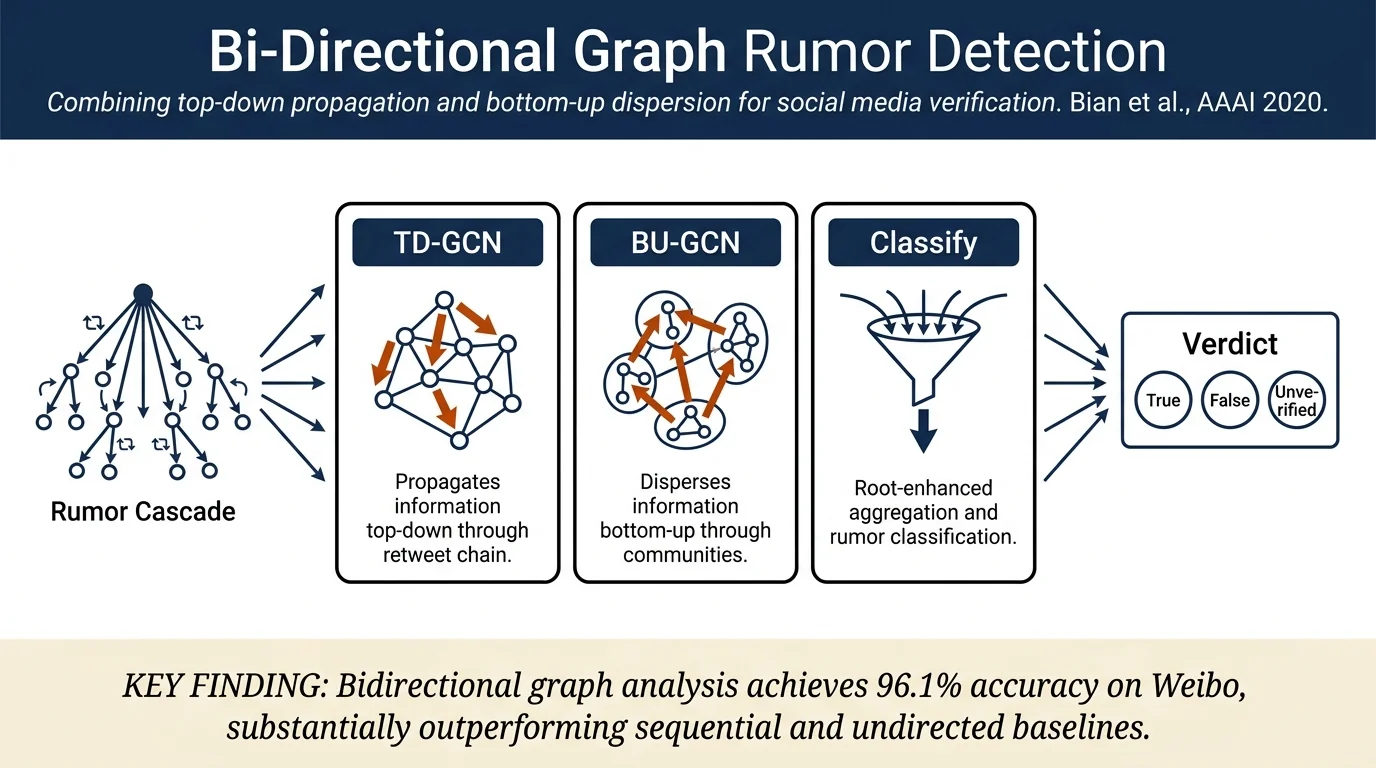
Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks¶
Authors: Tian Bian, Xi Xiao, Tingyang Xu, Peilin Zhao, Wenbing Huang, Yu Rong, Junzhou Huang Venue: AAAI 2020 — arXiv:2001.06362
TL;DR¶
Proposes Bi-GCN, a graph convolutional network approach for rumor detection that models both top-down propagation patterns (how rumors spread from source) and bottom-up dispersion patterns (how rumors diffuse within communities). By capturing both directional characteristics jointly and incorporating source post features at each layer, Bi-GCN achieves state-of-the-art accuracy on Weibo (96.1%), Twitter15 (88.6%), and Twitter16 (88.0%), with particular strength in early detection.
Contributions¶
- First application of graph convolutional networks to social media rumor detection, replacing prior temporal-sequential models (RNN/LSTM/RvNN) that ignore global propagation structure.
- Bi-GCN architecture combining TD-GCN (top-down propagation) and BU-GCN (bottom-up dispersion) to jointly model spread characteristics that existing methods treat separately.
- Root feature enhancement technique: concatenating source post features at each GCN layer amplifies the influence of early information, improving detection and early-detection performance.
- Empirical validation on three benchmarks (Weibo, Twitter15, Twitter16) demonstrating 5–20% accuracy improvement over RvNN and CNN-RNN hybrid baselines.
Method¶
The model constructs a propagation/dispersion graph from retweet and response relationships, where nodes are posts and edges represent causality. The graph is represented as an adjacency matrix A with edges only from parent to child nodes (top-down direction).
Key components:
-
TD-GCN (Top-Down): Applies graph convolution with adjacency matrix A to capture how rumors propagate downward through retweet chains. Uses two GCN layers with normalized adjacency matrix  and learnable weight matrices.
-
BU-GCN (Bottom-Up): Applies graph convolution with transposed adjacency matrix A^T to capture how rumors disperse upward within communities. Represents information aggregation from child nodes (many replies) to parent nodes.
-
Root Feature Enhancement: At each GCN layer k, concatenates the root node's (source post's) hidden features with all other node features: H̃k = concat(H_k, (H)_root). This ensures the model continuously references the original source information.
-
DropEdge Regularization: Randomly drops p=20% of edges during training to reduce overfitting, following the approach of Rong et al. (2019).
-
Aggregation and Classification: Applies mean pooling to TD-GCN and BU-GCN outputs independently to get S^TD and S^BU, concatenates them, passes through fully-connected layers and softmax to produce final predictions.
Results¶
Evaluated on three real-world datasets with 5-fold cross-validation:
Weibo (binary classification): 96.1% accuracy; 96.1% F1 for both False and True rumors. Substantially outperforms RvNN (90.8%), PPC RNN+CNN (91.6%), and all hand-crafted feature baselines (DTC, SVM variants).
Twitter15 (4-way classification): 88.6% overall accuracy; F1 scores of 0.891 (Non-rumor), 0.860 (False), 0.930 (True), 0.864 (Unverified). Demonstrates robustness to multi-class formulation.
Twitter16 (4-way classification): 88.0% overall accuracy with F1 scores of 0.847, 0.869, 0.937, 0.865 respectively.
Early detection: Bi-GCN maintains high accuracy at very early detection deadlines (within 2 hours post), significantly outperforming RvNN, SVM-TS, and other baselines. Reaches ~80% accuracy on Twitter datasets within the first hour.
Ablation study: Shows that: - Root feature enhancement consistently improves all variants (UD-GCN, TD-GCN, BU-GCN) by ~0.01–0.02 accuracy. - Bi-GCN (TD+BU combined) outperforms single-direction models, confirming both propagation and dispersion contribute distinct signals. - Even the worst GCN variant substantially outperforms prior non-GCN baselines, validating the importance of structured graph learning.
Connections¶
- Extends Detect Rumors in Microblog Posts Using Propagation Structure via Kernel Learning which used tree kernels on propagation structure; Bi-GCN replaces hand-crafted kernels with end-to-end learnable graph convolutions.
- Improves upon Rumor Detection on Twitter with Tree-structured Recursive Neural Networks by capturing both propagation and dispersion; RvNN only uses leaf-node aggregation and is sensitive to late noisy posts.
- Related to Fake News Detection on Social Media using Geometric Deep Learning which applies GCN to cascades but models graph structure without direction; Bi-GCN's bidirectional design captures causal and diffusion asymmetries.
- Cited by subsequent works on Propagation-based fake news detection and Graph Neural Networks for rumor verification.
Notes¶
Strengths:
- Clear motivation: the paper articulates why standard GCN (undirected) misses directionality, and why sequential RNN models miss global structure—this is a genuine architectural gap.
- Thorough experimental design: 5-fold CV, comparison to 7 baselines, ablation study across four model variants, early-detection analysis.
- Strong empirical results across all three datasets with consistent improvements, and particularly impressive early-detection performance (crucial for real-world deployment).
- Root feature enhancement is simple but effective, and the paper shows it's critical across all variants.
Weaknesses:
- Limited novelty: Bi-GCN combines existing techniques (first-order ChebNet from Kipf & Welling 2017, DropEdge from Rong et al. 2019). The core contribution is applying directionality to rumor graphs, which is somewhat incremental.
- No theoretical analysis of why bidirectionality helps; insights are purely empirical.
- Weibo dataset dominates the paper; Twitter results, while good, are lower in absolute accuracy (88% vs. 96%), and Twitter's class imbalance and smaller size may explain this gap.
- No comparison to other directed GCN variants beyond UD-GCN; e.g., graph attention networks (GAT) or other message-passing architectures could have been explored.
- Text/linguistic features completely absent; model operates only on propagation structure + TF-IDF features. Hybrid approaches (content + structure) are not explored.
Follow-ups:
- Incorporating textual content alongside structure could further improve detection.
- Exploring attention mechanisms to weight parent/child contributions differently across layers.
- Cross-domain transfer learning: does a model trained on Weibo transfer to Twitter?
- Theoretical analysis of why bidirectional information aggregation reduces false-negative rate in early detection.