Fact-Checking Meets Fauxtography: Verifying Claims About Images¶
Authors: Dimitrina Zlatkova, Preslav Nakov, Ivan Koychev
Venue: arXiv, 2019 — arXiv:1908.11722
TL;DR¶
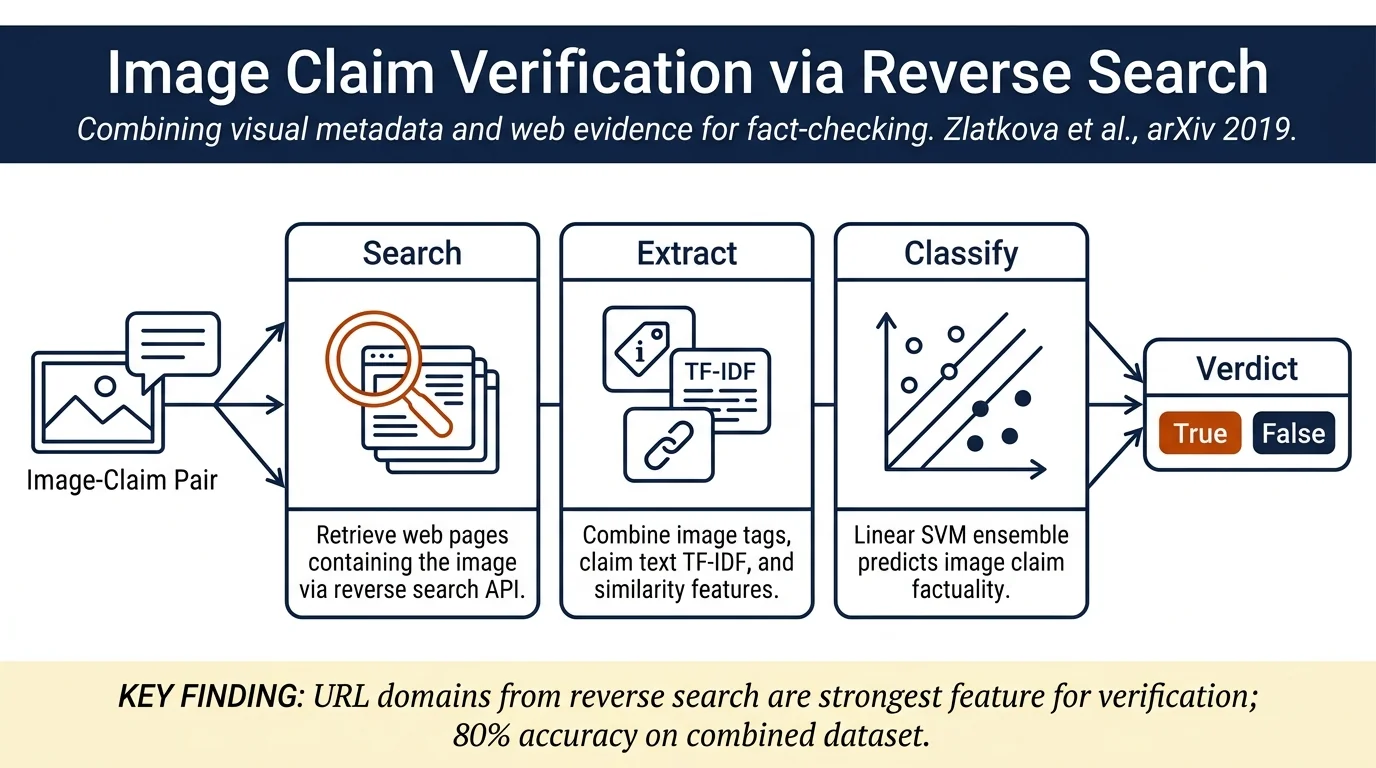
This paper introduces the problem of verifying claims made about images and creates a dataset of 1,233 image-claim pairs labeled as true or false. Using features from reverse image search (media source credibility, article titles), image metadata (Google tags), and claim-article similarity, a linear SVM classifier achieves 80% accuracy, substantially above the 50% baseline.
Contributions¶
- Formulates the novel task of predicting factuality of image-claim pairs, distinct from manipulated image detection.
- Releases two curated datasets: 838 examples from Snopes Fauxtography section (imbalanced, 197 true / 641 false) and 395 true examples from Reuters Pictures of the Year (2015–2018).
- Explores three feature classes: image-based (Google tags, URL domains, media source credibility), claim-based (TF-IDF), and relationship-based (cosine and embedding similarity between claim and reverse image search results).
- Demonstrates sizable improvements over majority baseline; top features are URL domains (89.7% AP on combined test set) and claim-article similarity metrics.
Method¶
The system uses reverse image search (Google Vision API) to retrieve web pages containing the image. For each image:
Image features: Google's automatic tags associated with the image; domain names and categories of URLs from reverse search results; factuality ratings of news sources (from Media Bias/Fact Check database), classified as True/False/Mixed media.
Claim features: TF-IDF vector representation of the claim text.
Relationship features: Cosine similarity and Universal Sentence Encoder embedding similarity between claim text and article titles from trustworthy media sources returned by reverse image search. Similarities are smoothed by averaging.
Classification uses a linear SVM trained separately for each feature group, then predictions are normalized via softmax and averaged to form the final decision.
Results¶
Snopes-only test: 63.2% accuracy, 73.0% average precision (AP) over 10 random folds with 50-example test sets.
Snopes + Reuters combined: 80.1% accuracy, 90.3% AP over balanced 100-example test sets.
Top-performing features: - URL domains: 78.6% accuracy (S) / 89.7% AP (S+R) - True media percentage: 74.6% accuracy (S+R) - Embedding similarity: 74.0% accuracy (S+R) - Claim text: 74.9% accuracy (S+R)
Weak features: false media percentage, false media titles (near-baseline performance).
On unseen data from Snopes Fauxtography (Feb–Apr 2019, 28 balanced examples), top-1 feature (URL domains) achieved 71.7% AP.
Connections¶
- Related to Propaganda detection and Misinformation and fake news detection via claim verification framework.
- Distinct from Image forensics — focuses on false claims about real images rather than detecting digital manipulation.
- Uses reverse image search as a primary information source, similar to automated fact-checking methods that consult the Web.
- Extends Multimodal fake news detection by addressing the image-claim relationship via web-based evidence.
Notes¶
Strengths: - Clearly articulates a gap: prior fact-checking work ignores image-related claims despite visual content's influence. - Well-motivated dataset combining Snopes (abundant false examples) and Reuters (high-quality true examples). - Thorough feature engineering across image, claim, and relationship dimensions; transparent about failure modes (image splice detection, EXIF metadata extraction). - Larger improvements on combined dataset (80% vs 63%) underscore the value of the Reuters data.
Weaknesses: - Class imbalance in Snopes (641 false vs 197 true) reflects real distribution but complicates evaluation; Reuters examples are longer and from a narrow domain (award-winning photography). - Reverse image search depends on Google's API; results are noisy and may exclude niche or newly uploaded images. - Feature engineering is heuristic; embedding similarity relies on sentence encoders trained on general text, not claim-specific semantics. - No comparison to FauxBuster (prior social-media-based approach) due to unavailable dataset. - Image forensic approaches (splice detection, error-level analysis) failed empirically, suggesting the task may be heavily skewed toward web-based textual features.
Open questions: - How does performance generalize to non-English claims or less mainstream image sources? - Can the method scale to real-time claim verification pipelines?