SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media¶
Authors: Marcos Zampieri, Shervin Malmasi, Preslav Nakov, Sara Rosenthal, Noura Farra, Ritesh Kumar
Venue: Proceedings of the 13th International Workshop on Semantic Evaluation (SemEval) at NAACL 2019 — arXiv
TL;DR¶
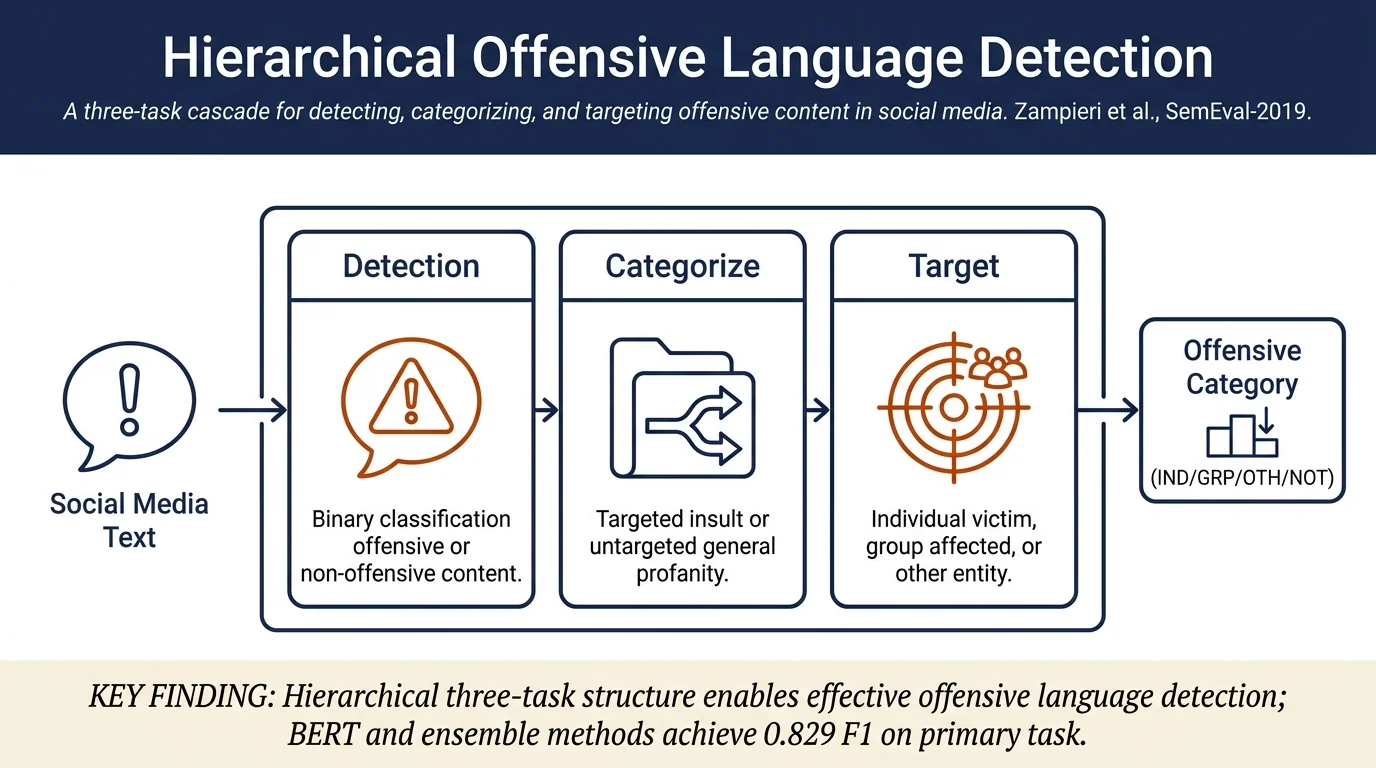
SemEval-2019 Task 6 reports on a shared task competition for identifying and categorizing offensive language in social media using the OLID dataset. Approximately 800 teams registered and 115 submitted results across three sub-tasks: offensive language detection (104 teams), offense type categorization (71 teams), and offense target identification (66 teams). Best-performing systems used BERT and ensemble methods, with task A achieving F1 scores up to 0.829, while task C (target identification) proved more challenging at 0.660 F1 for the top team.
Contributions¶
- Shared task competition infrastructure evaluating offensive language identification and categorization at scale
- Assessment of 115 participating team submissions across three hierarchical classification sub-tasks
- Systematic analysis of model approaches: deep learning dominates (BERT, RNN, CNN), with ensemble methods and transfer learning proving most effective
- Benchmark results and baselines for future offensive language detection research
- Demonstration that three-level annotation hierarchy effectively captures distinctions between offensive detection, offense type, and target identification
Method¶
The task builds on the Offensive Language Identification Dataset (OLID), previously introduced by Zampieri et al. (2019), with 14,100 English tweets divided into 13,240 training examples and 860 test examples. The three sub-tasks are:
Sub-task A: Offensive Language Identification — Binary classification of tweets as NOT (non-offensive) or OFF (contains offensive content). Evaluation metric: macro-averaged F1-score across both classes.
Sub-task B: Categorization of Offensive Type — For offensive posts, classify as TIN (Targeted Insult — insult/threat directed at individual or group) or UNT (Untargeted — general profanity/swearing). Training data: 2,407 TIN and 395 UNT examples.
Sub-task C: Offense Target Identification — For targeted insults, classify target as IND (Individual — including cyberbullying), GRP (Group — corresponding to hate speech), or OTH (Other — organization, situation, event, issue). Training data: 2,407 IND, 1,074 GRP, and 395 OTH examples.
Evaluation across all sub-tasks uses macro-averaged F1 as the official metric to account for severe class imbalance, particularly in sub-tasks B and C.
Results¶
Sub-task A (Offensive Detection): - Top team (NULI): F1 = 0.829 - CNN baseline: F1 = 0.800 - BiLSTM baseline: F1 = 0.750 - SVM baseline: F1 = 0.690 - 104 participating teams; top-10 range: 0.798–0.829
Sub-task B (Offense Type Categorization): - Top team (NULI): F1 = 0.755 - CNN baseline: F1 = 0.690 - BiLSTM baseline: F1 = 0.660 - SVM baseline: F1 = 0.640 - 71 participating teams; top-10 range: 0.692–0.755
Sub-task C (Target Identification): - Top team (NULI): F1 = 0.660 - BiLSTM baseline: F1 = 0.470 - CNN baseline: F1 = 0.470 - SVM baseline: F1 = 0.450 - 66 participating teams; top-10 range: 0.586–0.660
Model Analysis: - BERT-based approaches dominated sub-task A, with 7 of the top-10 systems using BERT variants or ensemble methods - Ensemble methods (combining multiple models) achieved strong results across all sub-tasks - Deep learning approaches (BERT, BiLSTM, CNN) significantly outperformed traditional machine learning (SVM) - Best overall systems (NULI, vradichev_anikolov) used multiple independent models combined with soft voting classifiers - Pre-training and transfer learning proved essential; most top systems leveraged pre-trained embeddings (GloVe, FastText) or BERT
Connections¶
- Benchmark evaluation of Predicting the Type and Target of Offensive Posts in Social Media (the original OLID dataset paper)
- Shared task competition framework for Offensive language detection in social media
- Related to Davidson 2017 Hate Speech on hate speech detection infrastructure
- Dataset and task structure influenced later multilingual offensive language tasks (HASOC, OffensEval 2020–2021)
- Demonstrates effectiveness of Content moderation approaches based on hierarchical classification
Notes¶
Strengths: - Large-scale evaluation with 800+ registrants across 115 final submissions provides robust benchmark - Hierarchical task structure naturally decomposes the problem: detect → categorize → identify target - Diversity of participating systems (traditional ML, deep learning, ensembles) allows comparative analysis of methods - Clear improvement trajectory from baselines through top systems demonstrates challenge difficulty - OLID dataset and SemEval results became standard benchmarks, spawning multilingual extensions and follow-up shared tasks
Weaknesses: - Task C (target identification) shows substantial performance drop compared to A and B, suggesting this problem remains difficult - Severe class imbalance in B and C (particularly OTH with only 395 training instances) makes all-OTH baseline achieve 0.0 F1 - Twitter-only scope limits platform generalizability - Keyword-biased data collection may overrepresent politically charged offensive speech relative to other offensive content types - Limited error analysis or qualitative study of failure modes across the top systems - Test set size (860 examples) modest relative to training (13,240), especially for low-resource classes in tasks B and C