Predicting the Type and Target of Offensive Posts in Social Media¶
Authors: Marcos Zampieri, Shervin Malmasi, Preslav Nakov, Sara Rosenthal, Noura Farra, Ritesh Kumar
Venue: Proceedings of NAACL 2019 — arXiv
TL;DR¶
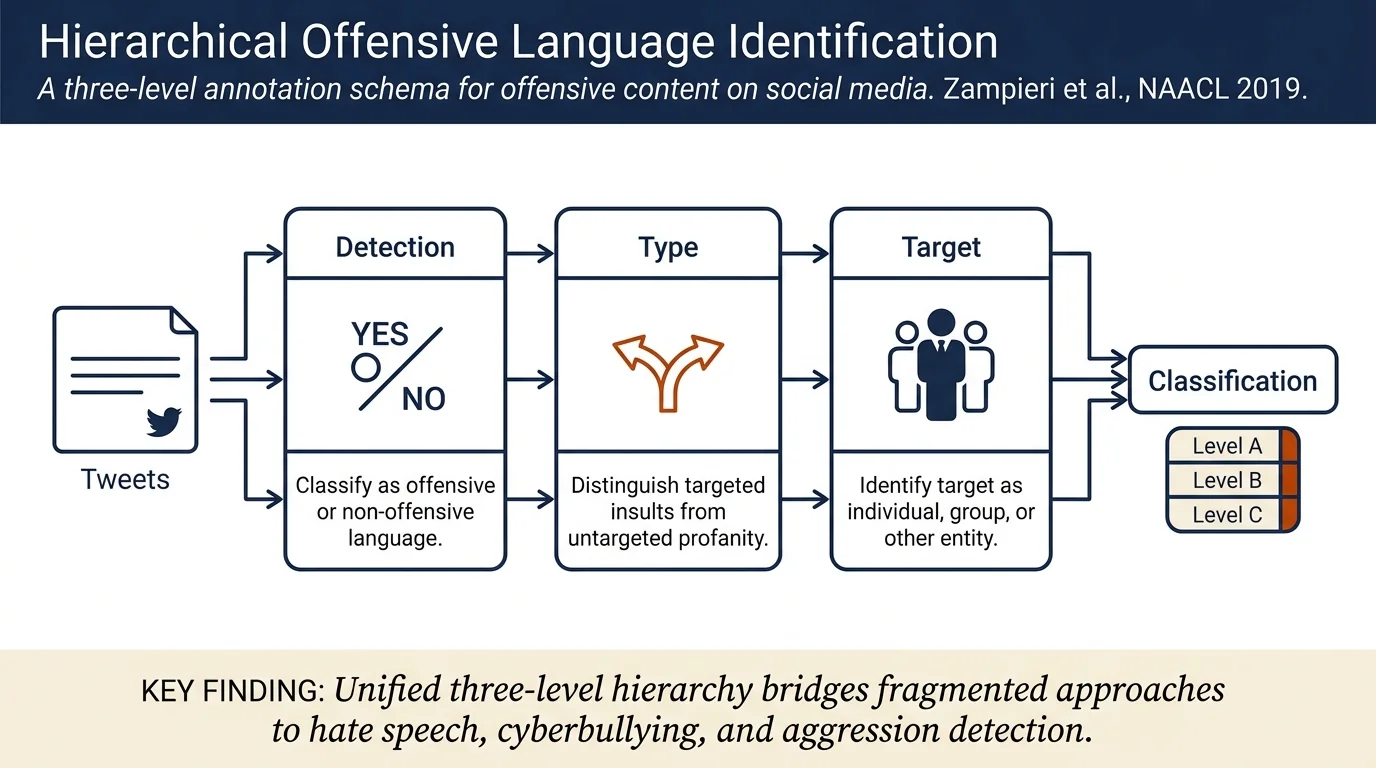
This paper introduces OLID (Offensive Language Identification Dataset), a large-scale dataset of 14,100 English tweets annotated with a three-level hierarchical schema for detecting offensive content. The hierarchy distinguishes offensive from non-offensive posts (Level A), categorizes offense type as targeted insults or untargeted profanity (Level B), and identifies targets as individual, group, or other (Level C). Baseline experiments using SVM, BiLSTM, and CNN models achieve macro-F1 scores of 0.80, 0.75, and 0.80 respectively on Level A classification.
Contributions¶
- Novel three-level hierarchical annotation schema that unifies approaches previously fragmented across hate speech detection, cyberbullying identification, and aggression detection
- OLID dataset with 14,100 tweets annotated at all three levels, with high inter-annotator agreement (Fleiss' κ = 0.83 for Level A)
- Baseline experiments and performance benchmarks using multiple machine learning models (SVM, BiLSTM, CNN)
- Recognition that offensive language targeting requires separate attention from just detecting that offense exists
Method¶
The paper proposes a three-layer hierarchical annotation scheme:
Level A: Offensive Language Detection — Binary classification of tweets as NOT (non-offensive) or OFF (containing any form of non-acceptable language, profanity, insult, or threat).
Level B: Categorization of Offensive Language — Classification of offensive posts into TIN (Targeted Insult/threat to individual or group) or UNT (Untargeted profanity and swearing).
Level C: Offensive Language Target Identification — Classification of targeted insults into IND (individual, including cyberbullying), GRP (group, corresponding to hate speech), or OTH (organization, situation, event, or issue).
Data collection employed keyword-based retrieval from Twitter API, targeting keywords associated with offensive content (e.g., political terms, profanity filters). Keywords were selected to achieve ~30% offensive content distribution. The full dataset balances political keywords (50%) and non-political keywords (50%) evenly.
Annotation was conducted via crowdsourcing (Figure Eight platform) with quality control through experienced annotators and test questions. Multiple annotators were assigned to each instance; ~60% of tweets received full agreement on first two annotations. For disagreements, a third annotation was requested and majority voting was applied. Final inter-annotator agreement measured κ = 0.83 for Level A.
The paper experiments with three model architectures: - SVM on word unigrams - BiLSTM with pre-trained FastText embeddings and learnable embeddings, average pooling, and dense layer - CNN with multi-channel embeddings (pre-trained and learnable) following Kim (2014)
Models are evaluated using macro-averaged F1 due to class imbalance, with additional per-class metrics.
Results¶
Level A (Offensive Detection): - CNN achieves best macro-F1 of 0.80 (P=0.87, R=0.93 for NOT; P=0.78, R=0.63 for OFF) - BiLSTM: 0.75 macro-F1 - SVM: 0.69 macro-F1 - All models substantially outperform baselines
Level B (Offense Type): - CNN: 0.69 macro-F1 (P=0.94, R=0.90 for TIN; P=0.32, R=0.63 for UNT) - Models consistently perform better at identifying TIN than UNT - Class imbalance (1,152 TIN vs. 551 UNT instances) contributes to performance gap
Level C (Target Identification): - CNN and BiLSTM: 0.47 macro-F1 - Strong performance on GRP (F1=0.67) and IND (F1=0.75) classes - OTH class achieves 0 F1 due to heterogeneity (targets organizations, situations, events) and data sparsity (only 395 training instances vs. 1,075 GRP and 2,407 IND)
The paper notes that the hierarchical structure captures relationships: cyberbullying = targeted insult at individual; hate speech = targeted insult at group.
Connections¶
- Foundational dataset for content moderation in social media
- Extends prior work on hate speech detection by incorporating target information Davidson et al. 2017
- Related to cyberbullying detection and offensive language detection more broadly
- Benchmark dataset for multilingual offensive language work (authors later extended OLID to multiple languages)
Notes¶
Strengths: - Addresses a genuine gap in prior work: previous datasets focused on hate speech, aggression, or cyberbullying in isolation; this unifies them under a coherent hierarchy - Rigorous annotation methodology with inter-annotator agreement measures - Clear hierarchical framing makes intuitive sense: detect, categorize, then identify target - Balanced keyword sampling (political/non-political) avoids skew - Released publicly, enabling reproducibility and follow-up work (became official dataset for SemEval 2019 Task 6)
Weaknesses: - Level B and C suffer from severe class imbalance; OTH class in Level C is nearly unlearnable - Twitter-only scope limits generalizability to other platforms - Keywords used for data collection may introduce bias toward politically charged offensive speech - Models relatively simple by modern standards (this was 2019, but SVM + basic RNNs/CNNs already dated) - No error analysis or qualitative examination of what models learn