Findings of the NLP4IF-2019 Shared Task on Fine-Grained Propaganda Detection¶
Authors: Giovanni Da San Martino, Alberto Barrón-Cedeño, Preslav Nakov Venue: NLP4IF Workshop at EMNLP-IJCNLP, 2019 — arXiv
TL;DR¶
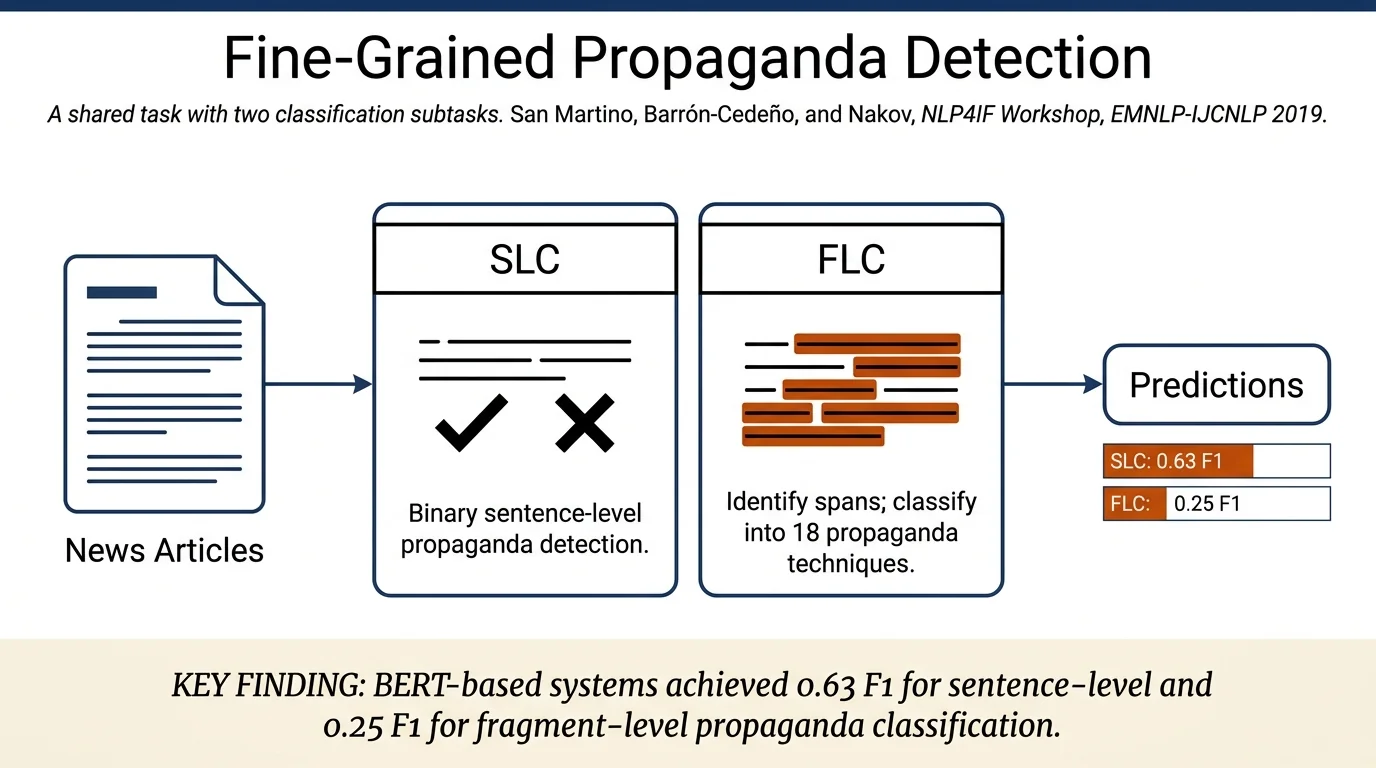
This paper reports findings from a shared task on fine-grained propaganda detection in news articles, featuring two subtasks: fragment-level identification and classification into 18 propaganda techniques, and sentence-level binary propaganda detection. The task attracted 90 registered teams with 39 making submissions; winning systems primarily used BERT-based approaches, achieving 0.63 F1 for sentence-level and 0.25 F1 for fragment-level classification on the test set. The shared task corpus and leaderboard became valuable resources for research at the intersection of propaganda, argumentation, and sentiment analysis.
Contributions¶
- Corpus design: 497 annotated news articles (350 training, 61 development, 86 test) with fragment-level annotations for 18 propaganda techniques and sentence-level propaganda labels, created using professional annotators.
- Fine-grained propaganda taxonomy: Formal definition and operationalization of 18 propaganda techniques including loaded language, name calling, repetition, exaggeration, doubt, appeal to fear/prejudice, flag-waving, causal oversimplification, slogans, appeal to authority, black-and-white fallacy, thought-terminating clichés, whataboutism, reductio ad Hitlerum, red herring, bandwagon, obfuscation, and straw man.
- Shared task organization: Two-phase competition (development and test phases) with live leaderboard and 527 submissions for fragment-level task, 2,538 for sentence-level task, demonstrating community interest.
- Baseline systems and evaluation methodology: Simple baselines (logistic regression for SLC, random span selection for FLC) and modified F1 metric accounting for partial span matching between predicted and gold fragments.
- Participant system analysis: Overview of 14 teams submitting system description papers, with most successful approaches using transfer learning (fine-tuned BERT, ELMo) and data augmentation strategies.
Tasks¶
Fragment-Level Classification (FLC): Identify minimal text spans where propaganda techniques appear and classify each into one of 18 techniques. This is formulated as a composition of two subtasks: span identification and multi-class (18-way) technique classification.
Sentence-Level Classification (SLC): Binary classification determining whether a sentence contains at least one propagandist fragment. This is a standard binary classification task with class imbalance on the development/test data.
Data¶
Articles collected from 36 propagandist and 12 non-propagandist news outlets (labels from Media Bias Fact Check), annotated by professional annotators using a consistent protocol. Total of 497 articles: - Training: 350 articles, 16,965 sentences - Development: 61 articles, 2,235 sentences - Test: 86 articles, 3,526 sentences
Annotation reveals class imbalance; loaded language (35.1% of training) and name calling/labeling (18.0%) dominate, while bandwagon, straw man, and obfuscation are rare (<0.25%).
Propaganda Techniques¶
The 18 techniques are grounded in psychological and rhetorical strategies:
- Loaded language — emotionally charged words/phrases
- Name calling or labeling — dehumanizing or pejorative labels
- Repetition — message repetition for acceptance
- Exaggeration or minimization — distorting magnitude or importance
- Doubt — questioning credibility without proof
- Appeal to fear/prejudice — instilling anxiety toward an alternative
- Flag-waving — appeals to nationalism or group identity
- Causal oversimplification — single-cause attribution; scapegoating
- Slogans — brief, striking phrases with stereotyping
- Appeal to authority — claims true because authority supports them
- Black-and-white fallacy, dictatorship — false binary choice
- Thought-terminating cliché — phrases discouraging critical reflection
- Whataboutism — discrediting via hypocrisy charge without refutation
- Reductio ad Hitlerum — associating idea with hated groups
- Red herring — introducing irrelevant material
- Bandwagon — "everyone else is doing it" persuasion
- Obfuscation, intentional vagueness — deliberately unclear language
- Straw man — refuting a distorted version of opponent's position
Results¶
Sentence-Level Classification (SLC) — Test Set: - Winning system (ltuorp) achieved 0.6323 F1 (0.6028 precision, 0.6648 recall) - Baseline (logistic regression on sentence length) achieved 0.4347 F1 - Most systems beat baseline; top 20 systems scored 0.51–0.63 F1 - General F1 decline from development to test set suggests overfitting on development set
Fragment-Level Classification (FLC) — Test Set: - Winning system (newspeak) achieved 0.2488 F1 (0.2862 precision, 0.2200 recall) - Baseline (random spans, random technique) achieved 0.0000 F1 - FLC substantially harder than SLC; only top 3 teams achieved above 0.15 F1 - More stable performance across development and test sets than SLC
Key Approaches¶
For SLC: Most successful systems employed fine-tuned BERT or other pre-trained contextual embeddings (ELMo, RoBERTa), often combined with ensemble methods, hand-crafted linguistic features (LIWC, readability, sentiment), and data augmentation (oversampling of minority class). Context-aware representations (including title or previous sentence) showed benefits.
For FLC: Winning system (newspeak) used 20-way word-level BERT classification (18 techniques + null + auxiliary class); unsupervised fine-tuning and oversampling of rare classes proved crucial. Other approaches used LSTM-CRF architectures with character and word embeddings, or BERT with Continuous Random Fields. Linguistic feature engineering (adjectives, adverbs) correlated with performance.
Common strategies: - Handling class imbalance via oversampling, cost-sensitive learning, or ensemble methods - Transfer learning from general and task-specific pre-trained models - Sentence-level and fragment-level models applied jointly for FLC - Attention mechanisms and contextual representations
Connections¶
- Related to stance detection frameworks which also classify speaker positions on contentious claims; propaganda techniques often exploit stance differences.
- Connects to Computational Argumentation research on fallacy detection and logical argument analysis; many propaganda techniques (appeal to authority, straw man, red herring) are logical fallacies.
- Overlaps with Sentiment Analysis on emotional appeals; techniques like loaded language and appeal to fear rely on emotion-evoking language similar to opinion and sentiment targets.
- Foundational work for state-sponsored propaganda analysis which applies propaganda technique understanding to real-world propaganda campaigns.
- Related to Media manipulation and Information operations at the technique taxonomy level.
Notes¶
The shared task's fine-grained approach (identifying minimal fragments and specific techniques rather than article-level binary labels) enables interpretability and understanding of how propaganda works, not just whether content is propagandist. Sentence-level classification proved more tractable than fragment-level, suggesting that aggregating propaganda signals at the sentence level may be easier than pinpointing exact technique spans.
The significant performance gap between development and test sets in the SLC task indicates challenge in generalization to temporally or thematically distinct data. The FLC task's low absolute scores (<0.25 F1 for winners) despite systems beating random baselines demonstrates the difficulty of multi-label span-level classification, particularly with rare classes.
The techniques' connection to rhetorical fallacies and emotional appeals positions this work at the interface of NLP, argumentation, and psychology—relevant to researchers in misinformation, media literacy, and communication. Follow-up work includes SemEval 2020 Task 11, which split the shared task into separate binary sequence labeling (Task 1) and multi-class classification (Task 2) subtasks.