RoBERTa: A Robustly Optimized BERT Pretraining Approach¶
Authors: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov
Venue: arXiv:1907.11692, July 2019
URL: https://arxiv.org/abs/1907.11692
TL;DR¶
A replication and improvement study of BERT pretraining showing that BERT was significantly undertrained. RoBERTa introduces four key improvements—training longer with larger batches and more data, removing the next-sentence-prediction objective, training on longer sequences, and dynamically masking tokens—to achieve state-of-the-art results on GLUE, RACE, and SQuAD benchmarks, matching or exceeding post-BERT methods published after BERT's original release.
Contributions¶
- Systematic empirical evaluation of BERT pretraining design choices and hyperparameters, demonstrating that BERT was undertrained relative to training data and compute available
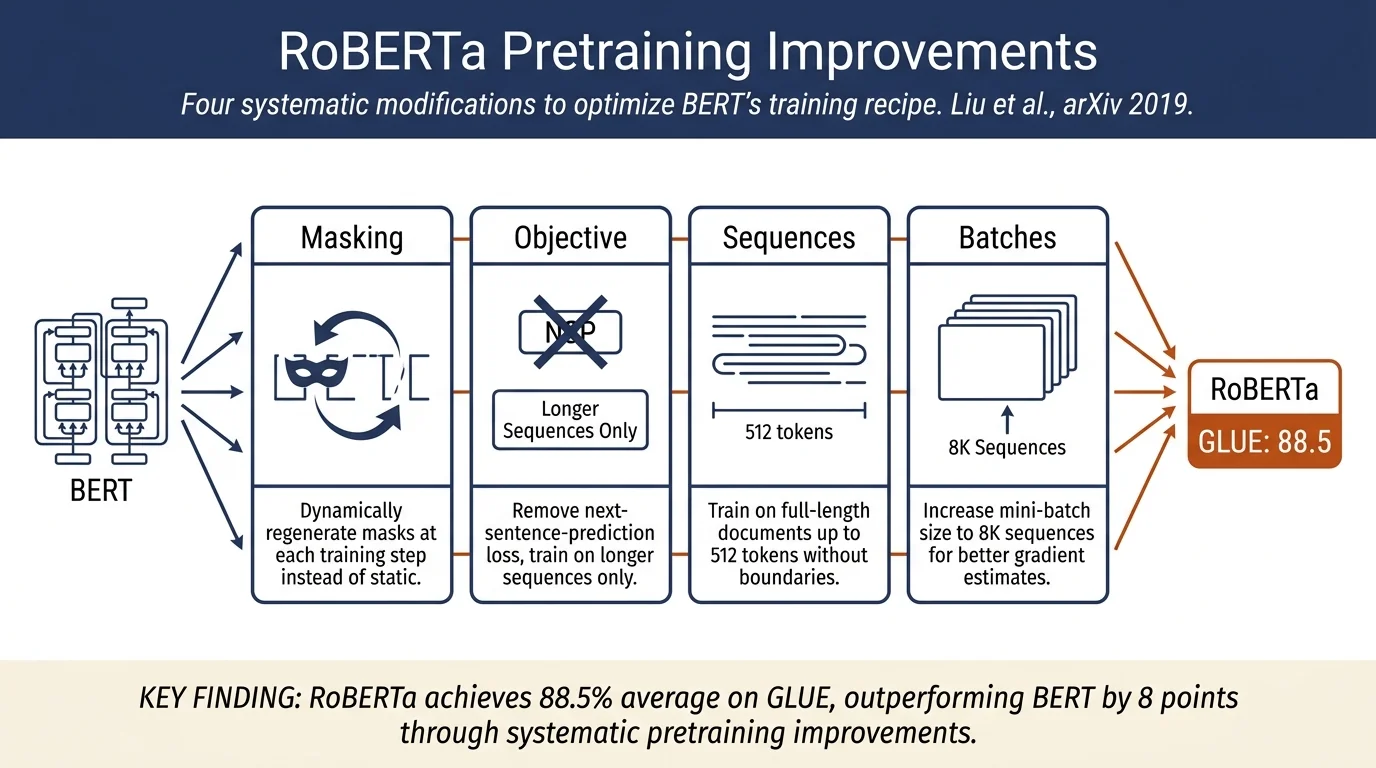
- Improved training recipe (RoBERTa) combining four key modifications: dynamic masking, removal of NSP loss, training on longer sequences, and larger mini-batches
- Introduction of CC-News, a new large-scale pretraining corpus of 76GB of English news articles to complement BookCorpus and Wikipedia
- Comprehensive ablation studies isolating the impact of each modification on downstream task performance
- Public release of pretrained models and code, establishing RoBERTa as a foundation for downstream fine-tuning in NLP
Method¶
Pretraining data: BookCorpus + Wikipedia (16GB) plus three additional large corpora: CC-News (76GB from CommonCrawl), OpenWebText (37GB), and Stories (31GB from CommonCrawl filtered for story-like content). Total: 160GB of uncompressed text.
Model architecture: Transformer-based masked language model, using BERT's 24-layer architecture with 1024 hidden size, 16 attention heads, and 355M parameters. Pretrained for 100K update steps on a cluster of Nvidia V100 GPUs.
Key training modifications:
-
Dynamic masking: Original BERT performs static masking once at preprocessing (10 duplications of the dataset with different masks). RoBERTa applies dynamic masking during each training step, regenerating masks for every input sequence.
-
Removal of Next Sentence Prediction (NSP): Original BERT includes an auxiliary NSP classification objective. RoBERTa removes this, training only on the masked language modeling objective and longer sequences (up to 512 tokens).
-
Longer sequences: Instead of maximum 512 tokens, RoBERTa trains on full-length sequences (up to 512 tokens) without artificial sentence boundaries, and evaluates training/evaluation with variable-length sequences (DOC-SENTENCES format that preserves document boundaries).
-
Larger mini-batches: Experiments with batch sizes of 256, 2K, and 8K sequences. Results show training with large batches (8K) improves both masked language modeling perplexity and downstream task performance.
-
Byte-Pair Encoding (BPE) vocabulary: Uses 50K subword units instead of BERT's 30K, implemented without additional preprocessing or heuristic tokenization rules.
Evaluation: Fine-tuned and evaluated on GLUE (9 language understanding tasks), RACE (reading comprehension), and SQuAD (question answering). Results reported on both single-task and multi-task ensemble setups, with median over 5 random initializations.
Results¶
Development set performance (single-task fine-tuning): - GLUE: RoBERTa achieves 88.5 average score, outperforming BERT (80.5), XLNet (88.4), and matching ALICE (88.3) - RACE: 83.2% accuracy on middle-school, 86.5% on high-school reading comprehension (state-of-the-art) - SQuAD v1.1: 88.9 EM / 94.6 F1 (dev set); 86.8 EM / 89.8 F1 (test set via public leaderboard)
Key findings from ablations: - Dynamic masking: Comparable or slightly better than static masking with the right implementation - Removal of NSP: Removing NSP with longer sequences matches or exceeds original BERT, contradicting Devlin et al.'s (2019) findings—subsequent follow-up work confirms NSP is not necessary - Training longer: Training for 300K and 500K steps progressively improves performance on all downstream tasks; even longest-trained RoBERTa does not overfit - Batch size effects: Increasing batch size from 256 to 8K improves both pretraining perplexity and end-task accuracy; large batches enable stable learning and better gradient estimates - Data size: Using additional data (CC-News, OpenWebText, Stories) consistently improves downstream performance; combining all datasets achieves best results
Comparison to post-BERT methods: On the public SQuAD v2.0 leaderboard (July 2019), RoBERTa matches or exceeds state-of-the-art: XLNet 89.1 / 90.5, RoBERTa 88.9 / 89.8 (near identical performance without additional external training data, unlike some concurrent methods).
Connections¶
- Builds directly on Devlin et al. (2018) BERT by replicating and improving the BERT pretraining approach, demonstrating the impact of design choices
- Related to concurrent transformer-based language models including XLNet (autoregressive approach, contemporary) and T5 (encoder-decoder architecture for transfer learning)
- Forms the backbone for numerous downstream applications in fake-news and misinformation detection cited in A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities
- Establishes the foundation for RoBERTa-based fine-tuning in fact-checking and claim verification pipelines
Notes¶
Strengths: Rigorous empirical methodology—each design choice is ablated independently with multiple random seeds, isolating the true contribution of each modification. Large-scale experiment on massive pretraining corpora (160GB) with clear documentation of hyperparameters. Replication of BERT finding it was undertrained is important for the community; results have been validated by subsequent work. Simple improvements (dynamic masking, removing NSP, longer sequences, larger batches) are easy to implement and widely adopted. Public release of models and code enabled rapid adoption across the field.
Limitations: Primarily empirical; limited theoretical explanation for why these design choices matter. English-only pretraining data; no exploration of multilingual or code-switching scenarios. Computational cost (1024 GPUs for 100K steps) makes replication inaccessible to many labs. NSP removal findings are presented empirically but lack deeper analysis of what the model learns without this auxiliary objective. No analysis of domain transfer or robustness to out-of-distribution data.
Impact and relevance: RoBERTa became the de facto standard pretrained language model in NLP after publication, widely adopted for fine-tuning on downstream tasks. In the misinformation detection literature, RoBERTa serves as the foundation for numerous fact-checking, claim verification, and stance detection systems. The paper's insistence on controlled ablations and public reproducible results set a high bar for subsequent pretraining work and influenced how the community evaluates design choices in language models.