FakeCatcher: Detection of Synthetic Portrait Videos using Biological Signals¶
Authors: Umur Aybars Cifci, Ilke Demir, Lijun Yin
Venue: IEEE Transactions on Pattern Analysis and Machine Intelligence, July 2020 — arXiv:1901.02212
TL;DR¶
FakeCatcher detects deepfakes by analyzing biological signals (photoplethysmography—blood flow patterns) extracted from facial regions. The key insight is that generative models fail to preserve spatial coherence and temporal consistency of these signals in authentic videos, making biological signal analysis a powerful forensic tool complementary to visual artifacts. The method achieves 91%+ accuracy on benchmark datasets.
Contributions¶
- A novel approach to deepfake detection exploiting biological signal inconsistencies in synthetic videos, independent of the generative model used
- Comprehensive analysis of signal transformations (temporal, frequency, wavelet) to capture spatial coherence and temporal consistency
- A practical system combining SVM and CNN classifiers with probabilistic video-level aggregation
- The Deep Fakes Dataset: 140 diverse "in the wild" videos with realistic conditions (compression, illumination, motion, occlusion)
- Extensive evaluation across multiple datasets (Face Forensics++, CelebDF, UADFV, DF-TIMIT) and generative models
Method¶
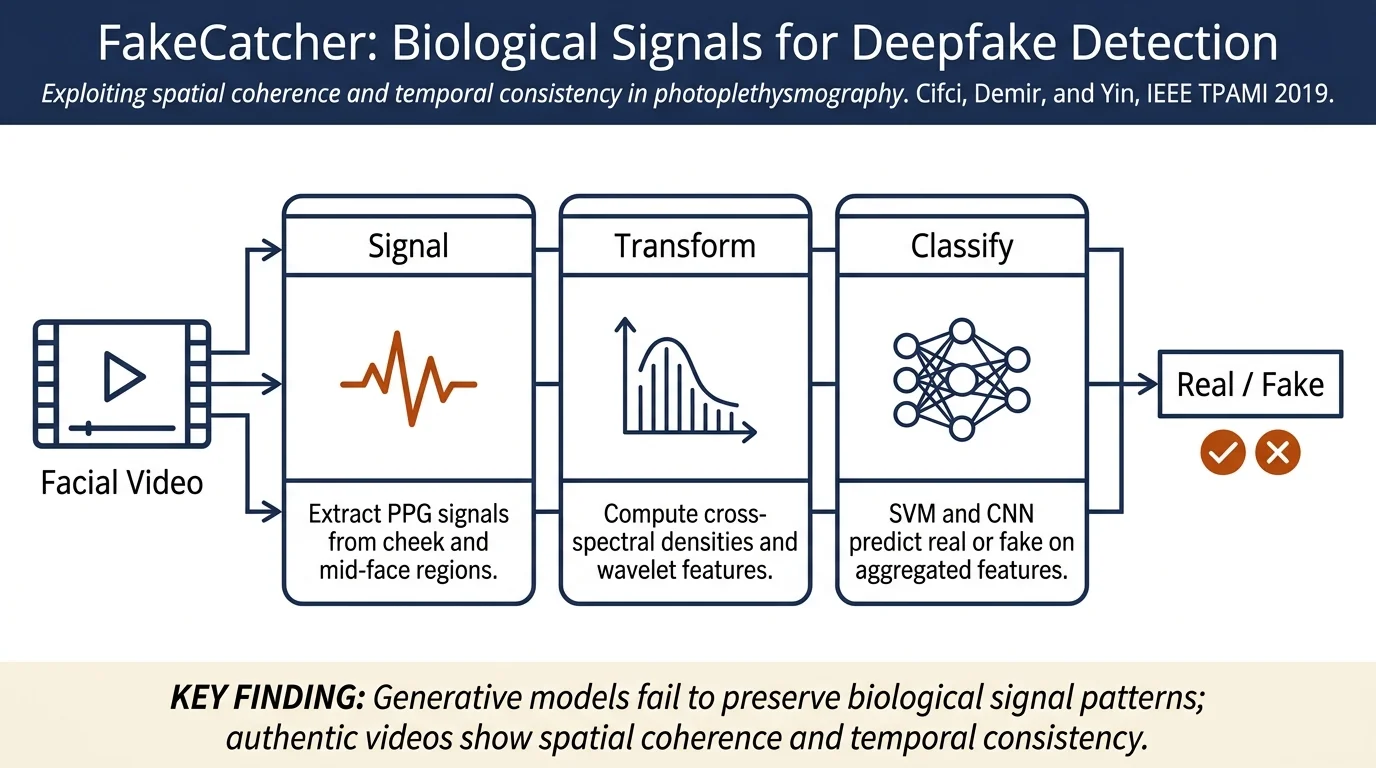
FakeCatcher operates in three stages:
Signal extraction: From each facial frame, biological signals are extracted from three regions (left cheek, right cheek, mid-region) using photoplethysmography (PPG). Specifically, the method extracts G-PPG (green channel) and C-PPG (chrominance-based PPG) signals.
Signal transformations: To measure spatial coherence and temporal consistency, multiple signal transformations are applied: - Pairwise cross-spectral densities to capture spatial relationships between facial regions - Power spectral density analysis in both linear and log scales - Discrete cosine transforms and wavelet transforms to encode signal characteristics - Time-domain statistical features (mean, standard deviation, differences)
Together, these transformations produce approximately 126 discriminative features. The analysis shows that authentic videos exhibit strong spatial coherence (signals from different face regions are correlated) and temporal consistency (signal properties remain stable across video frames), while synthetic videos generated by GANs exhibit both spatial and temporal inconsistencies.
Classification: Two complementary classifiers are trained: 1. SVM with RBF kernel on the 126 features from signal transformations 2. CNN on PPG maps—visual feature representations of the signals across facial regions
For video-level classification, segment-level predictions are aggregated probabilistically. The method uses weighted voting based on segment classification confidence, achieving high accuracy despite some individual frames containing artifacts that corrupt PPG signals.
Results¶
Within-dataset accuracy: - Face Forensics++: 91.07% video accuracy - CelebDF: 91.50% - UADFV: 97.36% - Deep Fakes Dataset (ours): 87.42% and 91.07% on different evaluation protocols
Cross-dataset generalization: The method shows strong generalization: - Trained on FF++, tested on CelebDF: 86.48% - Trained on FF++, tested on UADFV: 93.51% - Training on diverse datasets improves generalization
Comparison to baselines: FakeCatcher achieves 8.85% higher accuracy than the best baseline CNN architecture, demonstrating the value of biological signal analysis over purely visual approaches.
Robustness: The method is evaluated against various challenge conditions: - Face region sizes (very small to large ROIs) - Temporal segment durations (longer segments improve performance up to a point) - Different compression levels and image distortions - Diverse generative models (GANs, StyleGAN, DeepFakes, Neural Textures)
Connections¶
- Related to FaceForensics++: Learning to Detect Manipulated Facial Images via shared benchmark dataset and face manipulation detection framework
- Cited by and extends work in Face Forensics using novel signal modality
- Complements frequency-domain and visual artifact-based detection methods in Deepfake Detection
- Explores biological signal inconsistencies similar to work on audio-visual synchronization but in video domain
- Part of broader Face manipulation and Synthetic Media Detection literature
Notes¶
Strengths: - Novel insight: biological signals are a fundamentally different modality from visual artifacts, offering orthogonal information - Comprehensive feature engineering showing exactly which signal properties differentiate fake from real - Strong empirical results with good cross-dataset generalization - Practical: operates on standard video without requiring specialized equipment - Creates a new "in the wild" dataset addressing real-world challenges
Weaknesses: - Detection is an arms race; future generative models might learn to synthesize realistic biological signals - Method requires face region extraction; fails on highly occluded faces or extreme poses - Longer video segments improve accuracy, limiting applicability to short clips or single-frame scenarios - Relative to pure deep learning approaches, feature engineering makes the method less end-to-end learnable
Future directions: - How to make biological signal detection robust to adversarial attacks specifically designed to fool it? - Can the method scale to profile-view videos or full-body synthetic media? - Integration with other modalities (audio, 3D head pose) for even higher robustness?