Generating Sentiment-Preserving Fake Online Reviews Using Neural Language Models and Their Human- and Machine-based Detection¶
Authors: David Ifeoluwa Adelani, Haotian Mai, Fuming Fang, Huy H. Nguyen, Junichi Yamagishi, Isao Echizen Venue: arXiv, 2019 — arXiv:1907.09177
TL;DR¶
The paper demonstrates a practical attack where low-skilled adversaries can generate high-quality fake product reviews at scale by fine-tuning publicly available GPT-2 models on real review datasets. A two-step approach—generation plus BERT-based validation to preserve sentiment—produces reviews indistinguishable from genuine ones. Both human raters and automated detectors (Grover, GLTR, OpenAI detector) fail to reliably identify the fake reviews.
Contributions¶
- Demonstrates feasibility of sentiment-preserving fake review generation using pre-trained language models without specialized expertise
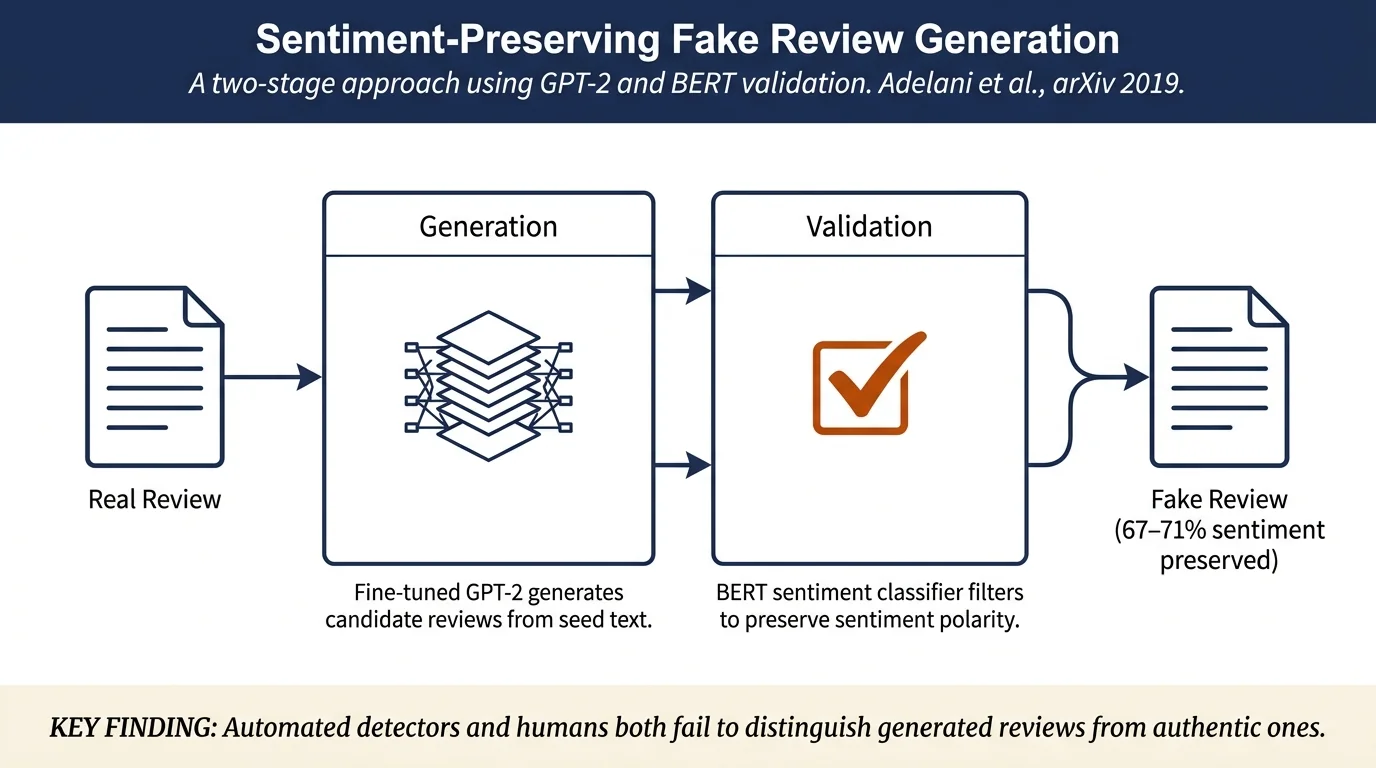
- Proposes a two-stage pipeline: GPT-2 generation conditioned on a seed review, followed by BERT-based validation to filter reviews with incorrect sentiment
- Comprehensive evaluation of human ability to detect generated reviews via subjective assessment with 80 participants
- Empirical evaluation of three automated detection methods (Grover, GLTR, OpenAI GPT-2 detector) and their failure modes
- Shows fine-tuned models outperform pre-trained models in sentiment preservation (67.0–70.7% vs. 62.1–64.3%)
Method¶
The attack exploits the transferability of large pre-trained language models. The authors fine-tune GPT-2 (117M parameters) on Amazon and Yelp review datasets. The generation pipeline takes a real review as a seed, generates a candidate review x', and validates it using BERT fine-tuned as a sentiment classifier. If the generated review matches the original review's sentiment (positive or negative), it enters the attack pool; otherwise it is discarded.
Fine-tuning improves substantially over the pre-trained model: adding task-specific supervision via BERT validation and explicit sentiment modeling yield the best results. The authors also experiment with multi-layer LSTM conditioning on sentiment embeddings, which achieves 70.7% sentiment preservation on Amazon and 71.0% on Yelp.
Results¶
Sentiment preservation: Fine-tuned GPT-2 achieves 67.0% ± 1.4% (Amazon) and 67.7% ± 1.2% (Yelp) sentiment preservation; explicit sentiment modeling reaches 70.7% ± 1.3% (Amazon) and 70.1% ± 1.2% (Yelp).
Subjective fluency evaluation: 80 human raters (39 native, 41 non-native English speakers) rated generated reviews on a 5-point Likert scale. Fake reviews achieved mean opinion scores of 3.23–3.30 (similar to 2.95–3.49 for real reviews), indicating humans find them fluent and indistinguishable from genuine reviews.
Detection performance: Single detectors achieved equal error rates (EER) of 23.5% (GPT-2PD), 40.9% (GLTR), and 11.8% (Grover). Ensemble methods combining multiple detectors reduced EER to 19.6%. Humans choosing between one real and three fake reviews had accuracy near chance (25.4%–34.6%), demonstrating humans cannot reliably identify generated reviews.
Connections¶
- Related to prior work on fake review generation methodology
- Relevant to Zellers et al. on detecting model-generated text
- Builds on GPT-2's transfer learning capabilities (Radford et al. 2019)
- Connected to Sentiment Analysis and Text generation literatures
Notes¶
The work highlights a critical practical threat: state-of-the-art detectors are not yet reliable for distinguishing AI-generated reviews from authentic ones. The reliance on pre-trained, publicly available models makes this attack accessible to non-experts. A key limitation is the relatively modest sentiment preservation rates (67–71%), meaning many generated reviews fail validation and are discarded—a real attacker would need to generate many more candidates than humans would post. The paper does not address countermeasures beyond detection; rate-limiting or review volume constraints might mitigate the attack's practical impact.