Comparative Studies of Detecting Abusive Language on Twitter¶
Authors: Younghun Lee, Seunghyun Yoon, Kyomin Jung
Affiliation: Department of Electrical and Computer Engineering, Seoul National University, Seoul, Korea
ArXiv: 1808.10245
TL;DR¶
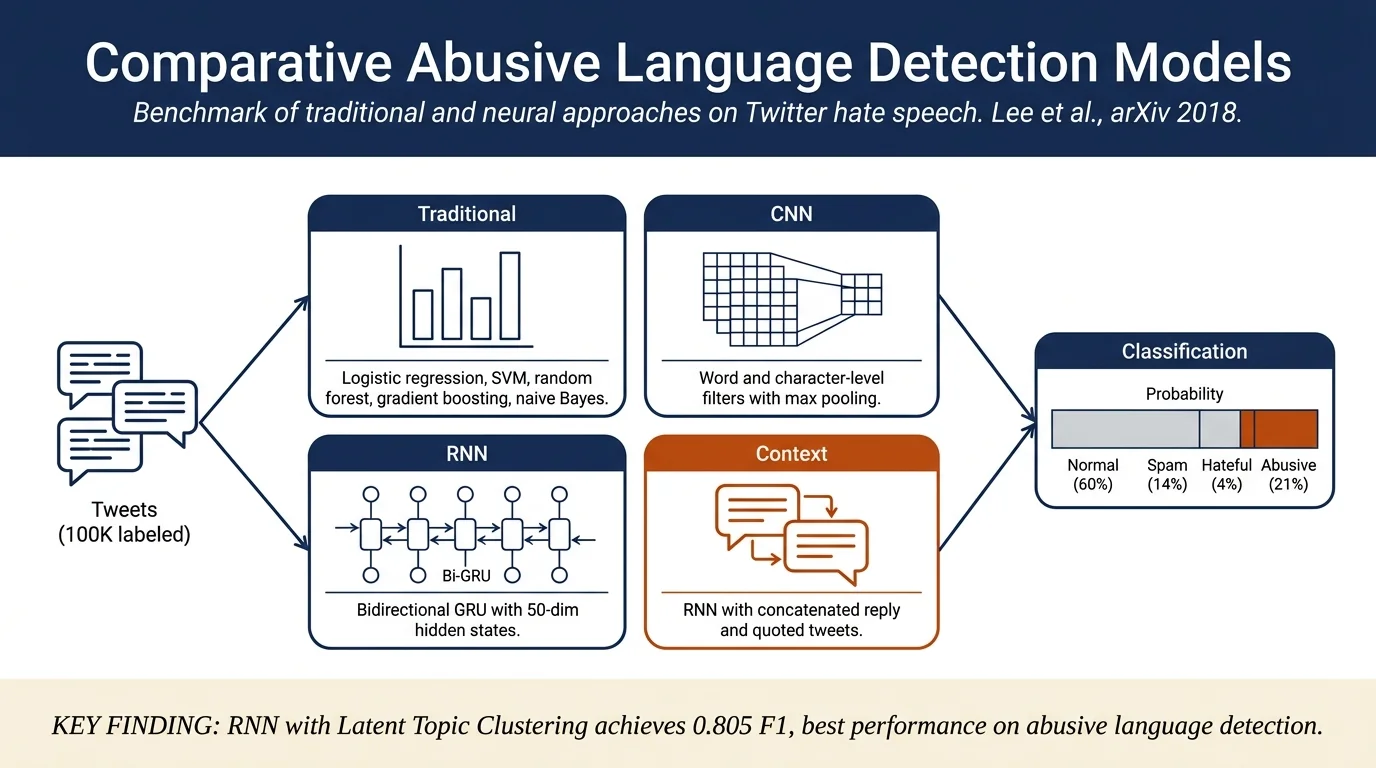
Conducts the first comprehensive benchmark of traditional machine learning and neural network models on the Hate and Abusive Speech on Twitter dataset (100K tweets). Bidirectional GRU networks with Latent Topic Clustering achieve the best performance (0.805 F1), outperforming traditional methods like logistic regression and SVM. Character-level features hurt neural models on this dataset, but context information from reply tweets improves detection of hateful and abusive content.
Contributions¶
- First comparative study of diverse learning models (traditional ML + deep learning) on a large-scale abusive language dataset with 100K cross-validated tweets
- Establishes baseline performance metrics for multiple model architectures on Hate and Abusive Speech on Twitter
- Investigates the effect of character-level vs. word-level representations for this task and domain
- Introduces contextual features (replies and quoted tweets) as additional input to neural models
- Demonstrates that ensemble approaches and model variants (attention mechanisms, latent topic clustering) can improve detection of minority classes (hateful, spam)
Method¶
The paper evaluates five traditional machine learning classifiers and multiple neural network architectures:
Traditional ML: Naive Bayes, Logistic Regression, SVM, Random Forests, and Gradient Boosted Trees, all trained on TF-IDF-normalized Bag-of-Words representations with n-gram features (1–3 for words, 3–8 for characters).
Neural Networks: - CNN: Kim's (2014) baseline with word-level filters, character-level filters, and a hybrid concatenation approach - RNN: Bidirectional GRU cells with 50-dimensional hidden states, trained with cross-entropy and Adam optimizer - Variants: RNN with self-matching attention and Latent Topic Clustering (LTC), which extracts topic information from RNN hidden states to improve classification
Context Enhancement: For tweets that reply to or quote others, the model concatenates max-pooled CNN outputs or final hidden states of context tweets with the labeled tweet's representations.
Preprocessing: User IDs, URLs, and frequent emojis are replaced with special tokens; hashtags are segmented for better coverage.
Results¶
On the Hate and Abusive Speech on Twitter dataset (70,904 crawled tweets from 99,996 IDs):
Best Overall: RNN-LTC (word-level) with F1 = 0.805, precision = 0.804, recall = 0.815
Traditional ML Ranking: Logistic Regression > Ensemble methods (GBT, RF) > SVM > Naive Bayes
Key Findings: - Neural networks outperform traditional ML except for Logistic Regression (F1 = 0.780 at best) - Character-level features reduce neural model accuracy (likely due to dataset size and label imbalance) - Context tweets improve specific metrics: CNN with context achieves best recall (0.914) and F1 (0.875) for "hateful" tweets; RNN with context achieves best recall (0.937) for "abusive" tweets - RNN-LTC model achieves highest F1 for "spam" (0.551) among hateful/abusive tweets - Attention mechanisms provide modest gains (0.800→0.800 F1 for RNN variants)
Datasets¶
- Hate and Abusive Speech on Twitter (Founta et al., 2018): 100K tweets labeled as normal (60.5%), spam (13.8%), hateful (4.4%), or abusive (21.3%). The authors successfully crawled 70,904 tweets; missing tweets were deleted or from suspended accounts.
Connections¶
- Related to Schmidt & Wiegand (2017) — Hate Speech Detection Survey via comprehensive review of feature engineering and ML methods
- Related to Zampieri et al. (2019) work on shared task benchmarking offensive content and multilingual scope
- Related to Waseem's work via annotation quality issues in abusive language corpora
- Connected to work on offensive language detection on Twitter using similar methodology and dataset focus
Notes¶
Strengths: The comparative study provides valuable baseline performance across a diverse range of models and is the first systematic evaluation of deep learning approaches on a 100K-scale abusive language corpus. The investigation of contextual features is practical and well-motivated. The code is made publicly available, supporting reproducibility.
Limitations: The dataset is still relatively imbalanced (hateful: 4.4%, spam: 13.8%). The paper does not deeply analyze failure modes or provide error analysis. The improvements from variants (attention, LTC, context) are often marginal. The paper does not address real-world deployment considerations like computational cost or latency.
Follow-ups: Ensemble methods combining the best models could further improve minority-class detection. More sophisticated context selection (e.g., learned weighting of context) could improve over simple concatenation. The approach could be extended to other languages and social media platforms. Investigating why character-level features fail despite prior successes in other tasks remains an open question.