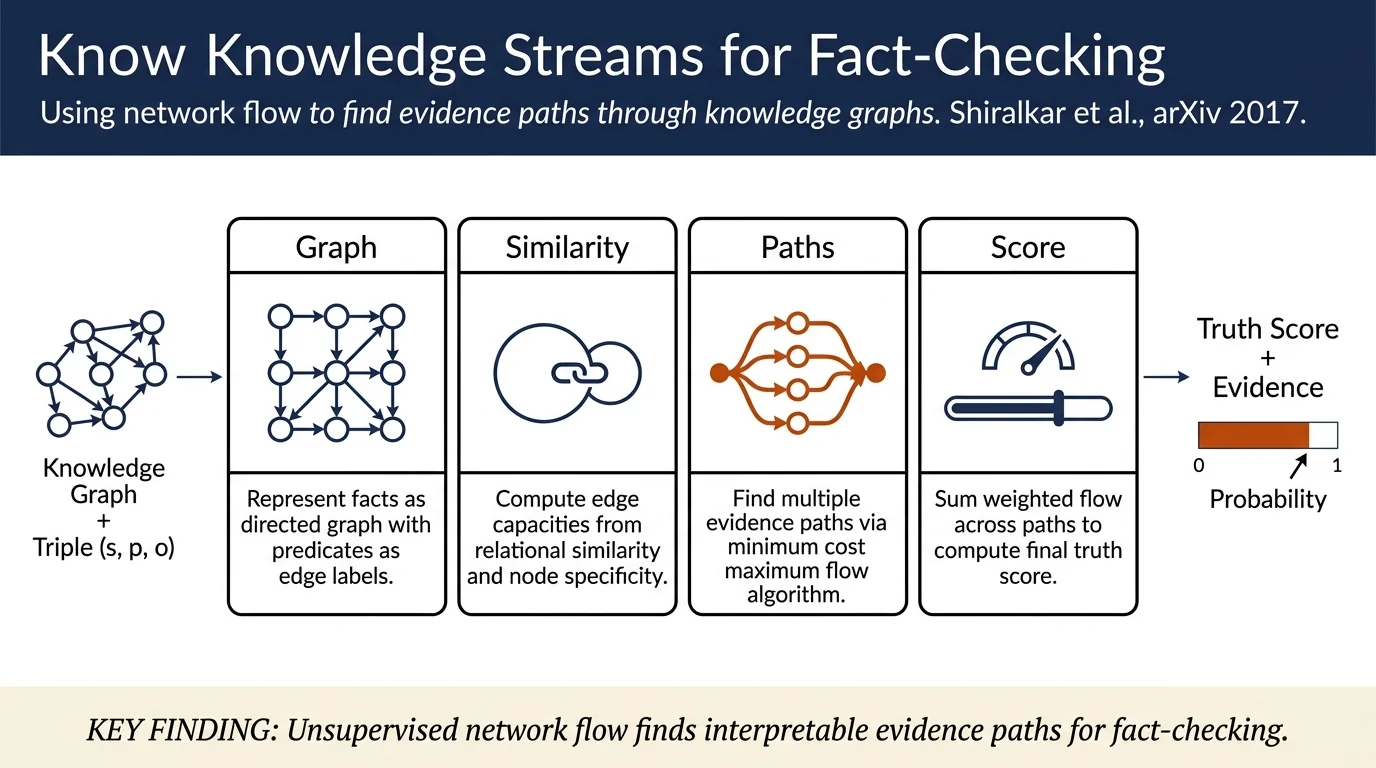
Finding Streams in Knowledge Graphs to Support Fact Checking¶
Authors: Prashant Shiralkar, Alessandro Flammini, Filippo Menczer, Giovanni Luca Ciampaglia
Affiliation: Center for Complex Networks and Systems Research & Network Science Institute, Indiana University, Bloomington
Venue: arXiv, August 2017 — ArXiv
TL;DR¶
Knowledge Stream (KS) is an unsupervised network-flow approach for computational fact-checking that treats a knowledge graph as a flow network. For a triple (subject, predicate, object), KS finds multiple paths connecting subject to object and uses edge capacities (based on relational similarity and node specificity) to compute a truth score. The method discovers interpretable patterns and relevant facts while achieving performance comparable to supervised baselines on synthetic and real-world datasets.
Contributions¶
- Proposes Knowledge Stream, the first application of network flow theory to fact-checking, which finds "streams" of knowledge from subject to object through knowledge graph paths.
- Introduces a data-driven method to compute relational similarity between predicates using the contracted line graph of a knowledge graph and TF-IDF weighting.
- Proposes Relational Knowledge Linker (KL-REL), which extends shortest-path fact-checking by biasing path search toward semantically related predicates.
- Demonstrates empirically that multiple paths provide complementary evidence; optimal performance (KS-AVG) uses exactly two paths per stream.
- Shows that KS automatically discovers interpretable relational patterns (e.g., spouse relationships via child-parent-spouse paths) without hand-crafted features.
Method¶
Knowledge Stream frames fact-checking as a minimum cost maximum flow problem on a knowledge graph:
-
Edge Capacity: Each edge e=(vi,vj) has capacity based on (a) relational similarity between the edge's predicate and the target predicate p, and (b) specificity of the incident node (high-degree nodes are generic, low-degree nodes are specific). Capacity is the product: U(e) = u(g(e),p) / (1 + log k(vj)).
-
Edge Cost: Cost is log k(vj), penalizing paths through high-degree (non-specific) nodes.
-
Path Specificity: S(P) = 1 / (1 + Σ log k(vi)) for intermediate nodes, favoring short paths through rare entities.
-
Net Flow: Each path P carries bottleneck flow β(P)·S(P), the product of minimum edge capacity and path specificity.
-
Truth Score: τ_KS = Σ_P∈stream W(P) = Σ_P β(P)·S(P), the sum of net flow across all discovered paths.
The algorithm uses Successive Shortest Path (SSP) to iteratively find shortest paths in residual networks, computing node potentials π to maintain reduced-cost optimality. Complexity is O(γ|E| log |V|) where γ is maximum flow; on DBpedia (~6M nodes, 24M edges), ~356 seconds per triple.
Results¶
Fact-checking performance (AUROC): - Synthetic datasets (8 benchmarks): KL-REL 94.47%; KS-AVG 96.05%; KS-CV 96.14% vs. PredPath 96.79%, KL 89.80%, PRA 85.51%. - Real-world datasets (6 benchmarks from GREC and WSDM): KL-REL 91.63%; KS-AVG 84.67%; KS-CV 85.24% vs. PredPath 85.41%, KL 86.65%, PRA 69.71%.
Key findings: - Performance is optimized when exactly two paths are used (Fig. 4), suggesting diminishing returns beyond multiple paths. - KL-REL (single shortest semantically-related path) outperforms original KL and most link prediction baselines on real-world data. - KS discovers highly interpretable patterns (e.g., spouse relations via child→parent→spouse paths; CEO via parentCompanyOf→keyPerson) that correlate with human intuition. - KS surfaces relevant facts for human fact-checkers by channeling flow through paths with high semantic and structural coherence.
Connections¶
- Related to Ciampaglia et al. (2015) via knowledge-graph-based shortest-path fact-checking; KS extends to multiple paths and network flow.
- Compares against Link Prediction methods (Katz, Adamic & Adar, Jaccard, Degree Product) and knowledge graph embedding methods (TransE, RESCAL).
- Contrasts with supervised approaches including PredPath (Shi & Weninger 2017) and PRA (Lao & Cohen 2014).
- Relates to Knowledge graphs, Knowledge Base Completion, and Link Prediction as related tasks.
Notes¶
Strengths: - Novel and elegant formulation: network flow as a metaphor for knowledge searching is intuitive and mathematically rigorous. - Fully unsupervised: no labeled training data required; edge capacities are data-driven but computed without supervision. - High interpretability: discovered paths and their flow weights provide human-readable explanations. - Discovers meaningful patterns: top-k paths per relation are semantically coherent and align with domain knowledge. - Handles uncertainty: multiple paths and capacity constraints naturally model partial and competing evidence.
Limitations: - Computational cost: 356 seconds per triple on DBpedia is slow for real-time fact-checking; authors identify SSP as a bottleneck and suggest network simplex as future optimization. - Edge capacity design: success hinges on relational similarity metric; authors note this is a design choice and explore alternatives (TF-IDF weighting was chosen empirically). - Mixed results on real-world data: KS underperforms KL-REL, suggesting that additional paths may introduce noise. The supervised KS-CV variant (tuning number of paths per dataset) performs better, hinting that the optimal number of paths is dataset-dependent. - Limited to triple-level claims: does not handle complex claims with multiple entities or temporal/spatial qualifications; authors mention this as future work (spatio-temporal KGs like YAGO2, Wikidata). - Undirected graph treatment: paper treats directed KGs as undirected, losing directionality information.
Open questions: - How do performance and interpretability scale to extremely large KGs (e.g., Wikidata with 90M+ entities)? - Can the method be extended to temporal/spatial fact-checking (e.g., "X was born in Y in 1980")? - How sensitive is the method to KG quality and completeness? What happens when the KG has systematic biases or missing data?